
ChatGPT API入門~にゃんたさんのudemyを受けてみた感想~

初めまして、みずぺーといいます。
このnoteを機に初めて私を知った方のために、箇条書きで自己紹介を記述します。
年齢:28歳
出身:長崎
大学:中堅国立大学
専門:河川、河川計画、河道計画、河川環境
IT系の資格:R5.4基本情報技術者試験合格💮、R5.5G資格
本日はChatGPTの全般について解説します。
ChatGPT使用時の注意点
ChatGPTは以下の三点に気を付けて使用することが必要です。
存在しない事実や関係を生成することがある(ハルシネーション問題)
学習した期間までの情報しか参照できない
情報漏洩リスク
プロンプトとは
プロンプトとは、以下の画像の赤枠で囲った部分に入力する文章のことです。

ChatGPTはプロンプトによって回答する精度も異なってきます。
以下は過去の記事でプロンプトの方法を解説してます。是非参考にしてください。
APIに入力するパラメータ
temperture
出力のランダム性を調整するもの(0~2の間で設定)
温度が低い:確率値の差分が大きくなり出力のランダム性が減る
温度が高い:確率値の差分が小さくなり出力のランダム性が増える
top_p
出力の候補の絞り込みに使用(0~1の間で設定)
top_p=0.15とすれば確率が上位15%までのトークンのみが候補となる
tempertureと同時に調整することは非推奨(OpenAi API documentより)

OpenAI APIを使用したChatGPTによる返答
それでは例として以下のレスポンスの関数を作成してChatGPTに答えさせてみましょう。
APIキーの設定
まずはOpenAIのAPIキーを入力します。
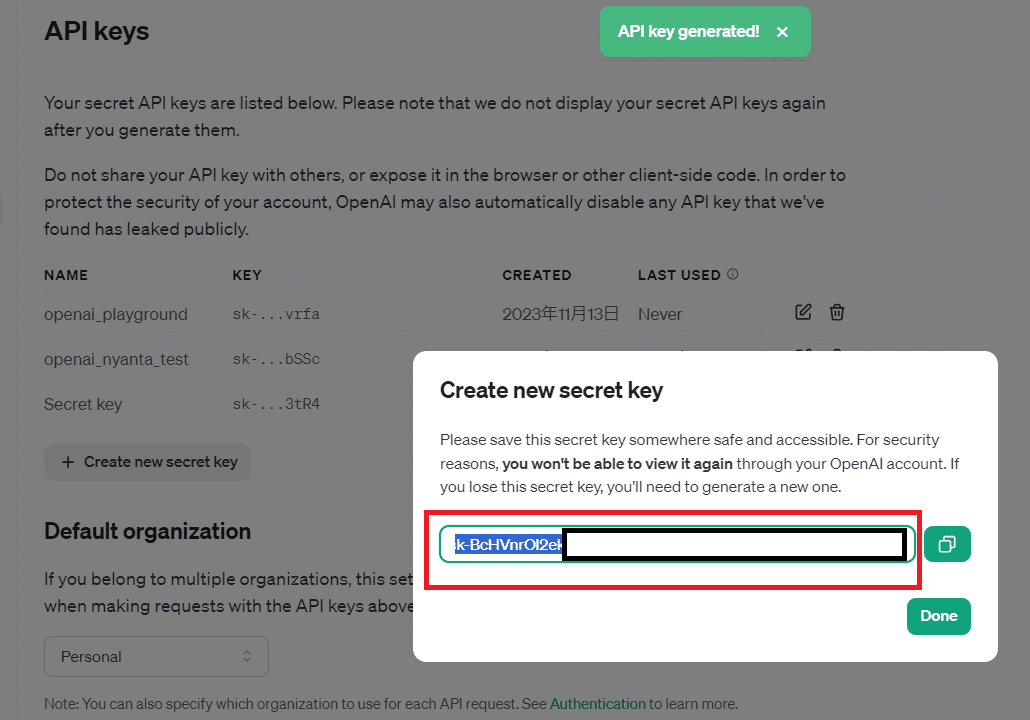
APIキーの取得に関しては、以下のリンクのCreate new sercre keyから発行できます。↓
Create new secret keyを押していただき

適当な名前を付けていただいて

以下のSercretkeyをコピーしていただいて、忘れないように!
ただ、もし忘れた場合には削除していただいて、再発行することも可能ですので!無料でできますのでご安心を。。。
Google clobでのキーの入力
本noteではGoogle clobを用いて解説します。
driveの左上のnewから作成しましょう
%%capture
!pip install openai==1.3.5import getpass
import json
from openai import OpenAI
from IPython.display import Markdown, display
apikey = getpass.getpass(prompt="OpenAIのAPIキーを入力してください")
client = OpenAI(api_key=apikey)ChatGPTに読み込ませる関数の定義
def get_chatgpt_response(
user_input: str,
template: str,
model: str = "gpt-3.5-turbo-1106",
temperature: float = 0,
max_tokens: int = 500,
) -> str:
"""
ChatGPTに対して対話を投げかけ、返答を取得する
"""
prompt = template.format(user_input=user_input)
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
seed=0
)
return response.choices[0].message.content入力する文章に関しては後程user_inputを入力すると見越して以下のような文章としております
テンプレート文の定義
PROMPT_TEMPLATE = """
下記の文章を関西弁にしてください。
{user_input}
"""今回は「がむしゃらにやれ!」をuser_inputとしてPROMPT_TEMPLATEに渡し、それを引数としたget_chatgpt_response関数に渡して、最終的にプリント文で出力します。
入力文の記載
print(get_chatgpt_response("がむしゃらにやれ!", PROMPT_TEMPLATE))その結果返ってくるのは
「がんばってやりなさいやで!」
FunctionCallingを使用した文章回答生成
続いてはFunctionsCallingを使用した文章回答生成を行いたいと思います。
今回は商品名と特徴が記載された前情報を読み取り、補助知識として読み込ませてから回答を生成させてみたいと思います。
前情報の入力(本セクションでNEW)
以下のデータを読み込ませてみます。

前情報を抽出する関数の定義(本セクションでNEW)
以下のコードで商品名から特徴を返す関数を定義します。
def get_product_description(product_name: str) -> str:
"""
商品名から特徴を返す関数
"""
description = dict_description.get(product_name)
if not description:
description = "該当データがありません"
return descriptionChatGPTに読み込ませる関数の定義
さらに以下のコードより対象の商品に対する商品の特徴を返しChatGPTに入力するところを記載します。
def get_chatgpt_response_with_description(user_input: str) -> str:
# 与えた関数の説明を記載
my_functions = [
{
"name": "get_product_description",
"description": "商品名から特徴を返す関数",
"parameters": {
"type": "object",
"properties": {
"product_name": {
"type": "string",
"description": "商品名を抽出する。例:商品A",
},
},
"required": ["product_name"],
},
}
]
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=[{"role": "user", "content": user_input}],
functions=my_functions,
function_call={"name": "get_product_description"},
seed=0
)
message = response.choices[0].message入力文の記載
最終的にuser_inputによる文章と事前にChatGPTに与えられた、get_product_descriptionにより回答が補正されて文章が答えられます。
response = get_chatgpt_response_with_description("商品Bについて教えてください")商品Bは独自のテクノロジーにより、効率的な性能を発揮する商品です。充電一回で長時間使用することができ、直感的な操作性を誇り、誰でも簡単に使いこなすことができます。忙しい日々にピッタリな商品です。PDFからQ&Aで回答を行う仕組み
以下のようなPDF文章から自分が欲しい情報を抽出したい場合にスクロールしながら該当文章を見つけ出すことは一苦労です。
そのためこの文章から該当情報を抽出させてChatGPTに読み込ませ、回答を生成させてみましょう。

ステップとしては以下の通りです。
まずはPDFを分割して整理するベクトル化を行います。
ベクトル化とは??と思われた方もいると思いますので、こちらの記事を参考までに。
イラストで表すと以下になります。

ベクトル化に関する概要や、やり方は以下の記事で解説してますので参考にしてください。
さらにベクトル化した文章から該当する箇所を検索し、回答を生成します。

ベクトル検索に関しては以下の記事で解説してますので参考にしてください。
PDFからQ&Aで回答実装
キーの入力
import getpass
import json
import os
from pathlib import Path
from IPython.display import Markdown, display
from langchain.chat_models import ChatOpenAI
from llama_index import (GPTVectorStoreIndex, LLMPredictor, ServiceContext,
StorageContext, VectorStoreIndex, download_loader,
load_index_from_storage)
apikey = getpass.getpass(prompt="OpenAIのAPIキーを入力してください")
os.environ["OPENAI_API_KEY"] = apikey # llama indexは環境変数じゃないとエラーがでる?PDFの読み込み
PDFReader = download_loader("PDFReader")
loader = PDFReader()
documents = loader.load_data(file=Path("コンプライアンスのすべて.pdf"))ベクトル化手法の設定
service_context = ServiceContext.from_defaults(
llm_predictor=LLMPredictor(
llm=ChatOpenAI(model_name="gpt-3.5-turbo-1106", temperature=0, model_kwargs={"seed": 0})
)
)ベクトル生成(index生成)
# indexを作成
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
index.storage_context.persist(persist_dir="./storage/")検索エンジン生成
query_engine = index.as_query_engine()処理実行
response = query_engine.query("AIとコンプライアンスについて教えて")最後に
本内容はにゃんたさんの講義を元に作成しております。一部自分が変えたところや飛ばしているところが多々あります。
PDFからQ&A
回答の高速化技術
FuctionCallingの分岐の方法
等々解説してます。詳細はにゃんたさんのudemyをご覧いただければと思います。
最後までお読みいただきましてありがとうございました!
この記事が気に入ったらサポートをしてみませんか?