
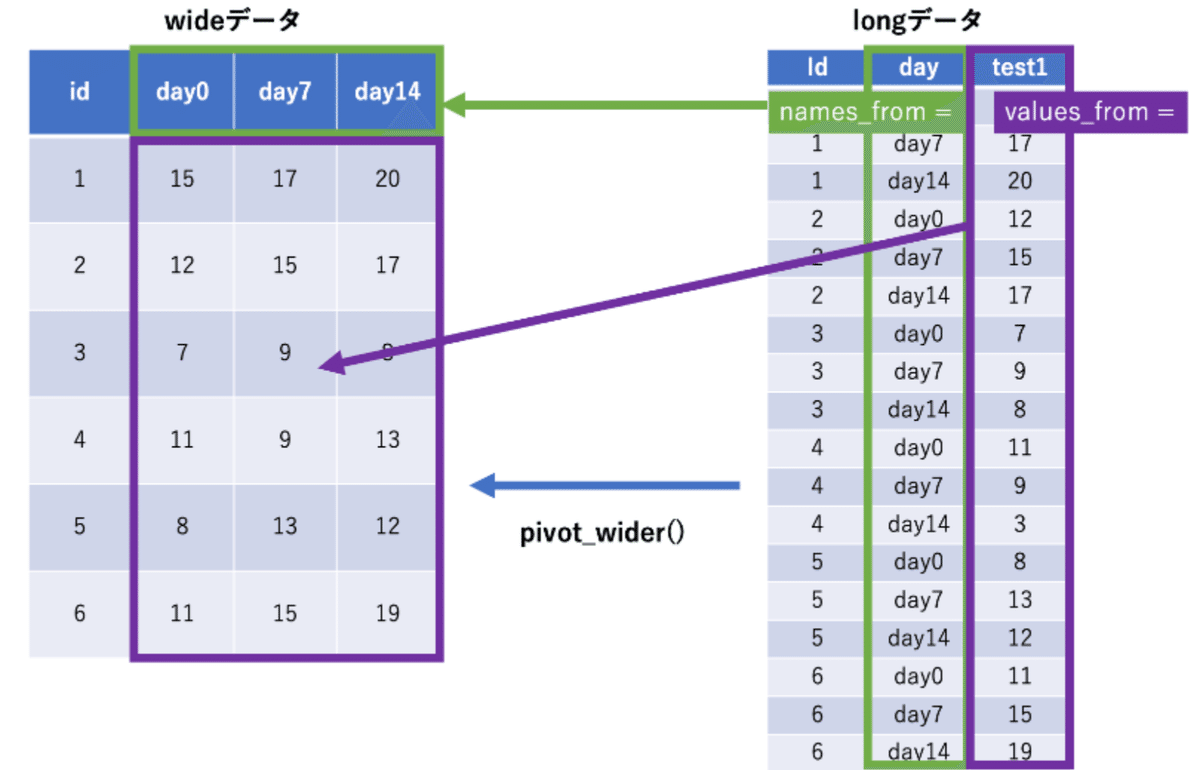
【2-7】Rでwideデータとlongデータを変換する

はじめに
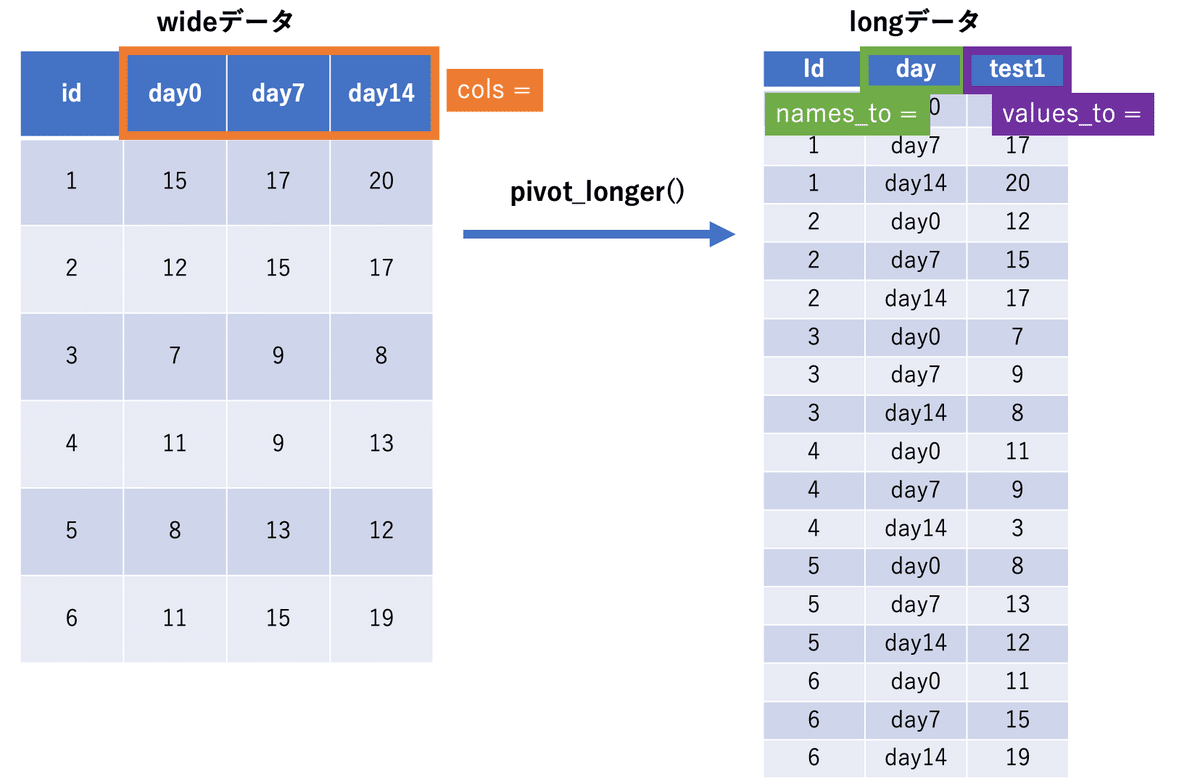
Rで分析、集計、グラフを作成するときはlongデータとwideデータについての理解が必要です。
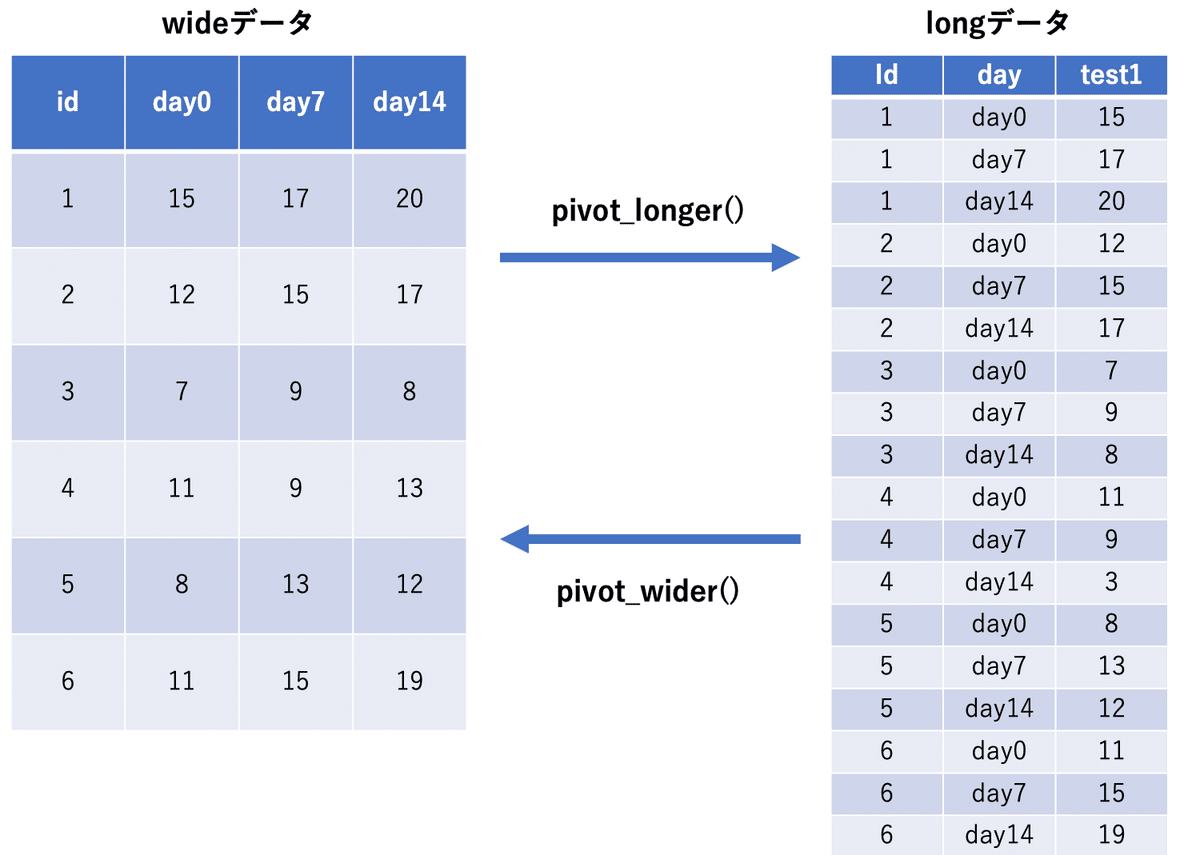
プログラミングやExcelのピボットテーブルで集計をしていないと左のwideデータが馴染み深いと感じると思います。これは人にとっても見やすい形式だと思われます。
しかし特にRで集計やグラフを作成するとなると右のlongデータの方が圧倒的に作業時間が少なくて済むことがあります。longデータとwideデータを自由に変換できることは分析する上で大切になりますので今回はpivot_longer()とpivot_wider()の基本的な使い方について紹介します。
wideデータとlongデータの使い所
完全に決まりはありませんし人によって意見が異なると思いますが、wideデータとlongデータの使い所について紹介します。
wideデータ
人が見やすい
集計の結果を人に見せる際、csvやExcelに出力する時にwideデータに直す
異なる種類や単位のデータが複数ある場合
同じ人に複数回データを取るときの統計解析(繰り返しのある検定)
longデータ
集計しやすい
グラフが作りやすい(グループ毎に色を変えるなど)
自前で集計するようなデータはwideデータが多い印象を受けます。
分析やグラフを作成する際はlongデータに直し、解析が終わりプレゼンで人に見せるときなどはwideデータに戻すといったこともあります。
データの準備
#pacmanパッケージがあるかを確認。なければinstall.packagesパッケージをインストール
if (!require("pacman")) install.packages("pacman")
#今回使うパッケージ
pacman::p_load(tidyverse, rio)
url <- "https://github.com/mitti1210/myblog/raw/master/data.xlsx"
data <- import(url, which = "anova")
head(data)
D0:0日目のテストの結果
D30:30日目のテストの結果
D60:60日目のテストの結果
*架空データ
このデータはgroupに関しては1列に対照群・介入群というlongの構造になっていますが、テストの結果については3列になっているのでwideな構造となっています。
pivot_longer()
D0, D30, D60をlongデータに変えていきます。
ここで使うのはpivot_longer()になります。
cols = でまとめたい列を選択します。
# pivotg_longerを使ってみるdata_longer <-
data |>
pivot_longer(
cols = c(D0, D30, D60) # D0:D60でもよい
)
head(data_longer)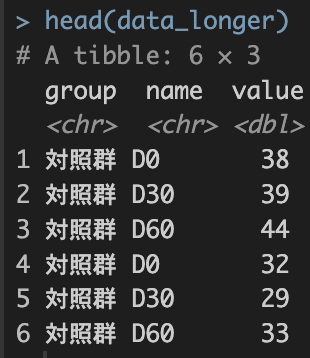
cols =
cols = はlong形式にする列を選択します。
列選択は以前紹介したselect()で使った方法が役に立ちます。
詳細はリンク先に譲りますが以下の方法でも同じ結果になります。
cols = D0:D60 #D0の列からD60の列まで全部
cols = 2:4 #2列目から4列目まで全部
cols = starts_with("D") #Dで始まる列全部
names_to = "新しい列名"
names_to = はnameとなる列名を何に変更するか?を指定します。
character型で入力する必要があるため" " でくくります。
# pivotg_longerを使ってみる
# names_toで列名を変更
data_longer <-
data |>
pivot_longer(
cols = c(D0, D30, D60),
names_to = "day"
)
head(data_longer)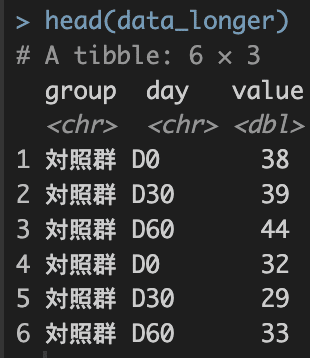
values_to = "新しい列名"
values_to = はvalueとなった列名を変更します。《》
# pivotg_longerを使ってみる
# names_toで列名を変更, values_toで値を変更
data_longer <-
data |>
pivot_longer(
cols = c(D0, D30, D60),
names_to = "day",
values_to = "test"
)
head(data_longer)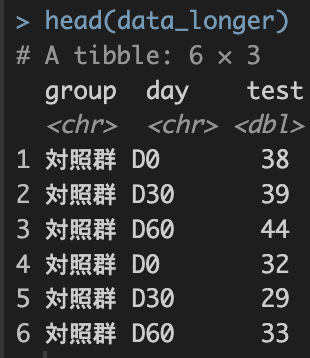
value → test
今までのまとめは以下になります
pivot_wider()
pivot_wider()はlongデータをwideデータに変換します。
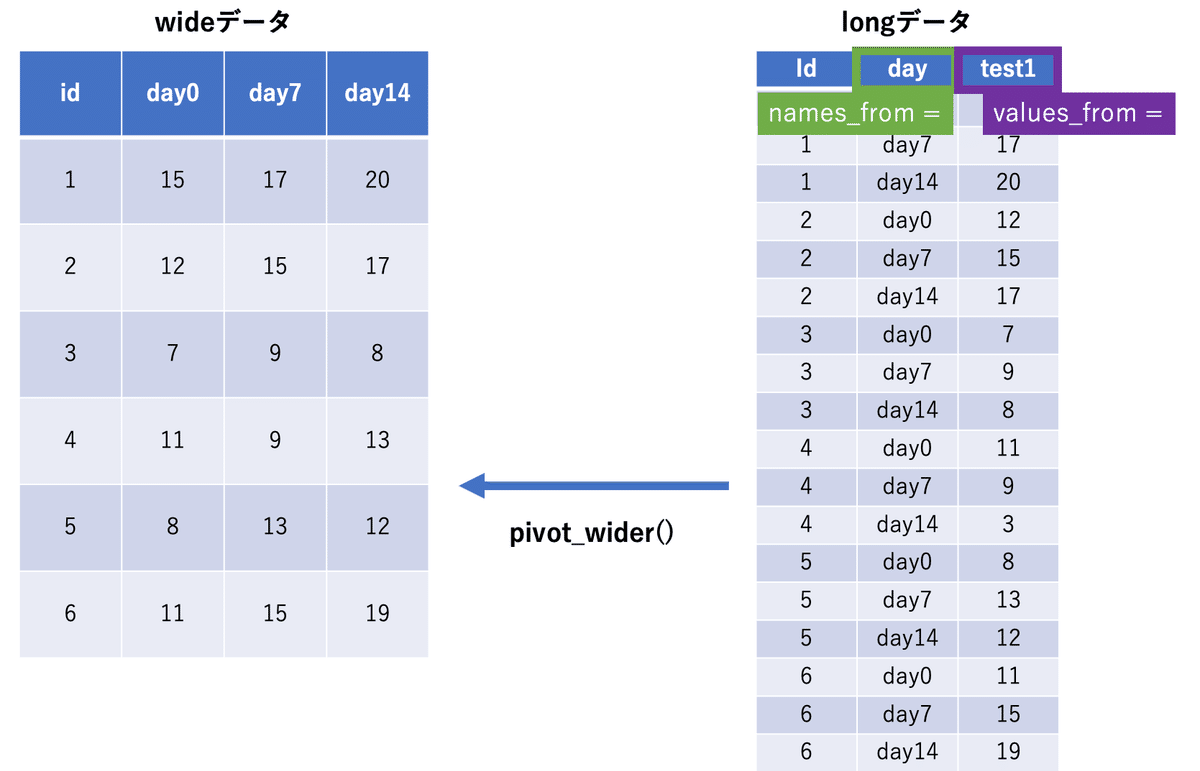
pivot_wider()を使う上で大切なものがidに当たる列です。
この列がないとwide形式にする時にRはどれを繋げればよいのかわからないため求めた出力をしない可能性があります。
head(data_longer)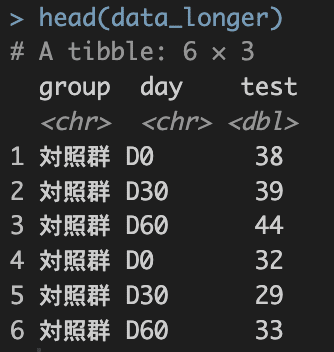
そこで行名(一番左の1,2,3….)を使いidの列を作ります。
行名(row_names)を列(coulumn)に追加する関数で便利なのはrownames_to_column()です。元のdataにidを追加してみましょう。
# dataにrownames_to_columnを使ってみる
data_longer <-
data |>
rownames_to_column("id") |>
pivot_longer(
cols = c(D0, D30, D60),
names_to = "day",
values_to = "test"
)
head(data_longer)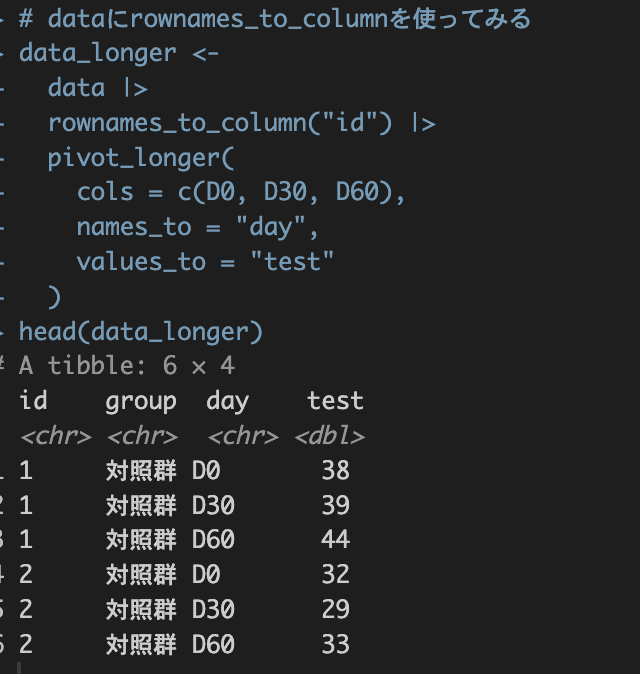
これでpivot_wider()を行ってみましょう。pivot_wider()に最低限必要なのは以下2つです。
names_from = どの列を列名にするか?
values_from = どの列を値にするか?
# pivot_widerを使ってみる
data_wider <-
data_longer |>
pivot_wider(
names_from = "day",
values_from = "test"
)
head(data_wider)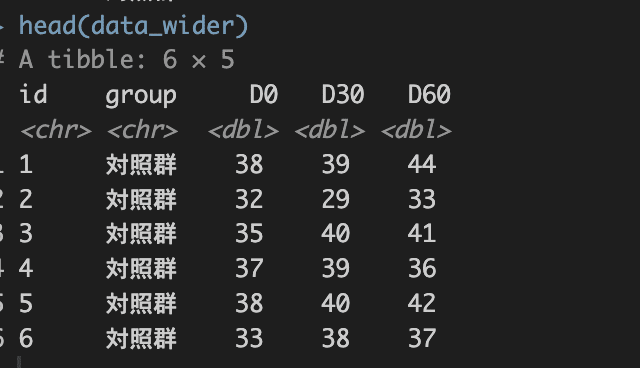
まとめ1
今回はlongデータとwideデータの基本的な使い方について紹介しました。
まずはこの使い方になれることから始めるといいと思います。
ただ、実際に使っているともう少しこうなれば…という箇所も出てきます。
そこは以下中級編としていくつか紹介していきます。
longデータにした時に列の順番バラバラになる問題
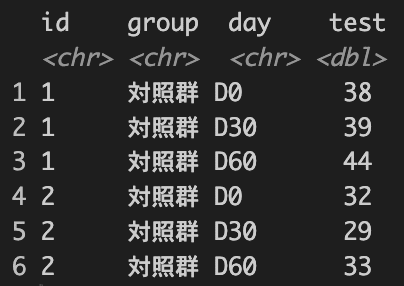
上記のlongデータですが、D0, D30, D60…と並んでいます。
そしてdayの下に<chr>とありcharacter型ということがわかります。
これは【1-12】Rでよく使われる型について説明しますで説明した通り、factor型にすると因子の順番が五十音順に並んでしまいます。
今回はD0, D30, D60は五十音順に並んでも問題ありませんが、五十音順では問題になる場合があります(例えば"pre" "post"など)。そういった場合は【1-12】で紹介したfct_inorder()が役に立ちます。この関数は文字型の出てきた順番に因子を並べてくれます。
pivot_longer()の後にmutate()でfct_inorder()を使う
# longデータにした後にmutate()でfct_inorderを使い因子型にする
data_longer <-
data |>
rownames_to_column("id") |>
pivot_longer(
cols = c(D0, D30, D60),
names_to = "day",
values_to = "test"
) |>
mutate(
day = fct_inorder(day)
)
head(data_longer)
しかもfactor型のlevelsも出てきた順番になります
ここではもともと五十音順なので変化はありませんが、これを使う機会は多くあります。
names_transform = を使う
先程はpivot_longer()の後にmutate()を使いましたが、実はpivot_longer()内で一度に処理することも可能です。それがnames_transform = list(列名 = 関数名)です。
names(ここではday)にfct_inorderを使います。関数名なので( )はつけません。
# 上記をmutateを使わずにnames_transform = を使い同じことをする
data_longer <-
data |>
rownames_to_column("id") |>
pivot_longer(
cols = c(D0, D30, D60),
names_to = "day",
values_to = "test",
names_transform = list(day = fct_inorder)
)
head(data_longer)列名を分解したい
複数のテストとその下位項目が横に並んでいるデータがあります。
以下は【2-6】で紹介したデータです。
#pacmanパッケージがあるかを確認。なければinstall.packagesパッケージをインストール
if (!require("pacman")) install.packages("pacman")
#今回使うパッケージ
pacman::p_load(dplyr, rio)
#データの準備
url <- "https://mitti1210.livedoor.blog/data.xlsx"
基本情報 <- import(url, which = "基本情報")
入院 <- import(url, which = "入院", skip = 2)
退院 <- import(url, which = "退院", skip = 2)
head(基本情報)
head(入院)
head(退院)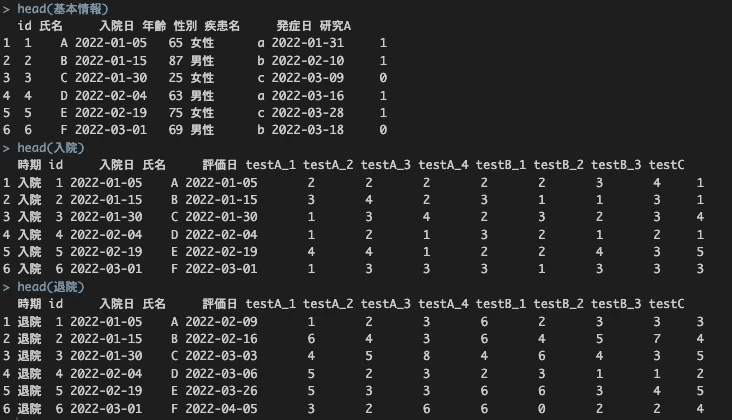
入院と退院の列名を確認すると以下のようになっています。
testA_1, testA_2, testA_3, testA_4,
testB_1, testB_3, testB_3,
testC
この入院のtestをlongデータに変換してみます。
入院_long <-
入院 |>
pivot_longer(
cols = c(testA_1:testC),
names_to = "test",
values_to = "点数"
)
View(入院_long)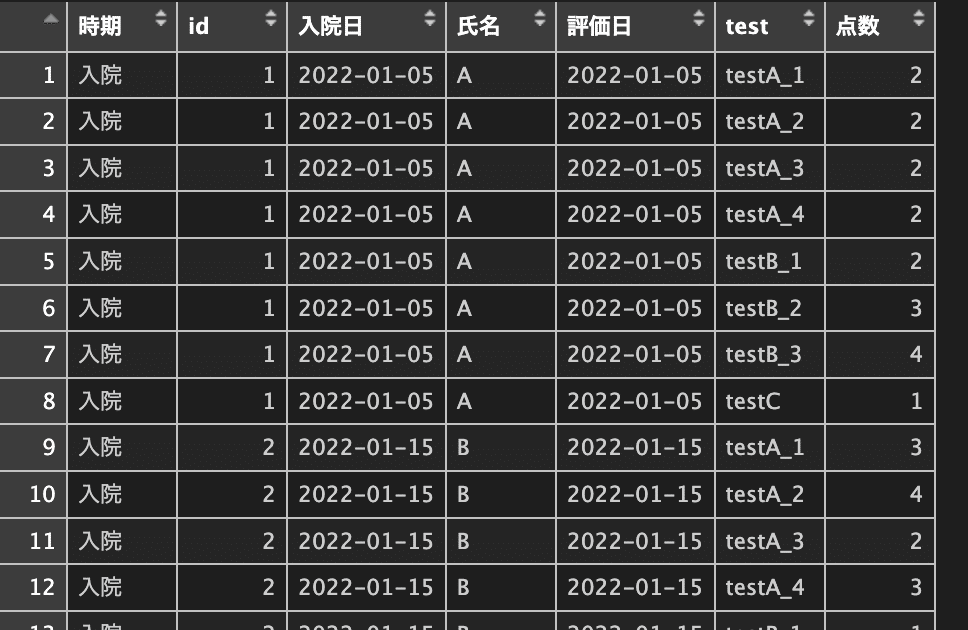
一応できましたが、できることならtestの列は以下であってほしいです。
names_sep =
test:testA, testB, testC
no:1, 2, 3
testA_1をtestAと1の2列に分けたい場合はnames_sep = が使い列を分割することができます。
ここでは"_"を使って区切ることが可能ですが、列が2つできるのでnames_to = は2つ名前をつける必要があります。そしてtestCは_がないため列名をtestC_1に変更します。列名変更は【2-4】で紹介済みです。
# names_sepで区切り文字を指定
入院_long <-
入院 |>
rename(testC_1 = testC) |> #renameで列名変更
pivot_longer(
cols = testA_1:testC_1,
names_to = c("test", "no"),
names_sep = "_",
values_to = "点数"
)
View(入院_long)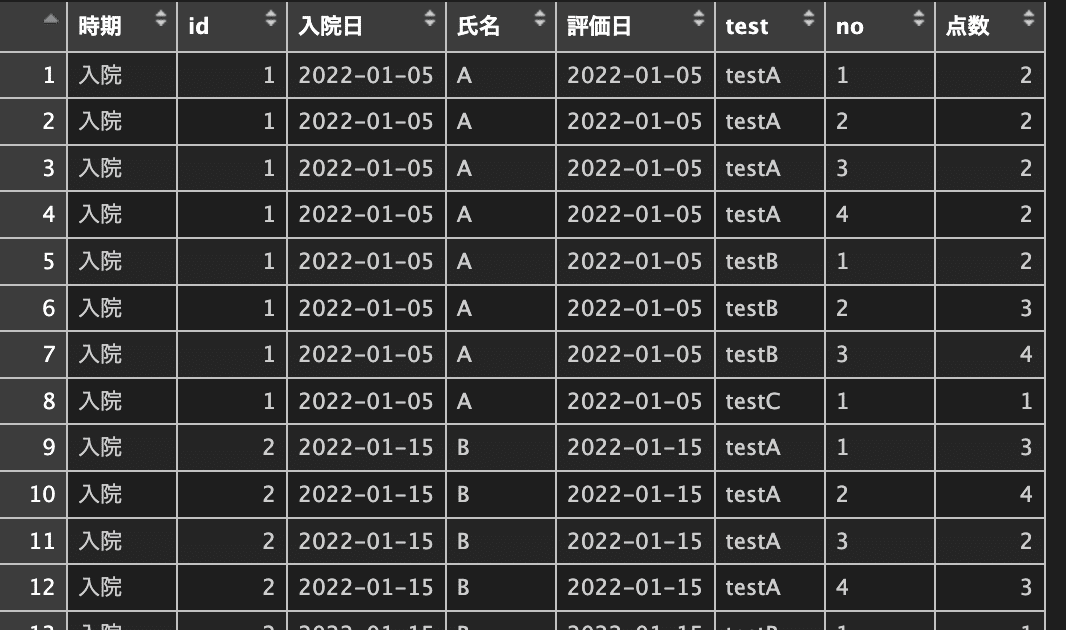
もし区切る文字(. - _ など)がない場合は何文字で区切るかの数値を使うことも可能です。例えばA1, A2, A3,,,などなら1文字の後で区切れるのでnames_sep = 1Lとすれば区切ることが可能です。ちなみに1LのLは整数という意味なのでつまり1です。なので上記は以下のような方法も可能です。
# names_sep=数値で区切り文字を指定
入院_long <-
入院 |>
pivot_longer(
cols = c(testA_1:testC),
names_to = c("test", "no"),
names_sep = 5L,
values_to = "点数"
)
View(入院_long)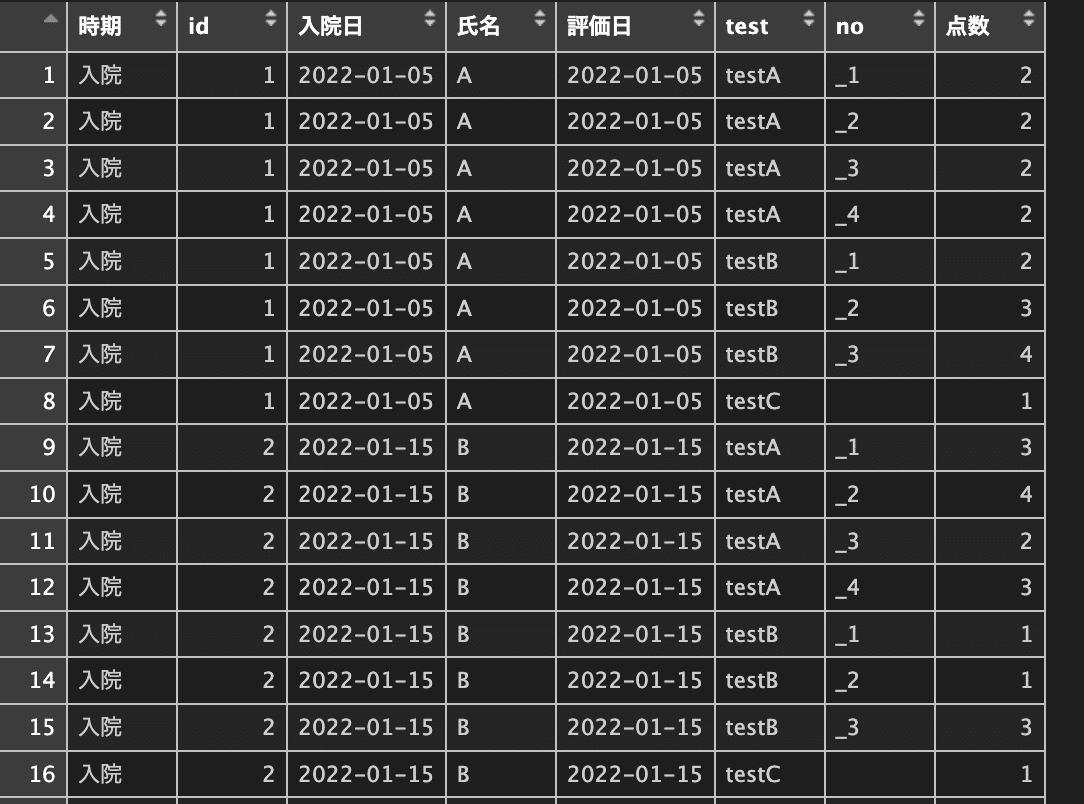
noの_を消すにはまた別の方法になります。
もう少し応用
以前こういうやり取りがありました。
pivotも見たんですが、Rで一発でできますか?
— 坪井 大和@Rehab PdM (@yamato_tsuboi) November 17, 2019
Stataだと、1行でこれができるので。。 pic.twitter.com/m4frnNYzUg
どうすればこうなるでしょうか?
(1行で行おうと考えなくて良ければ)第2章の内容だけで解決できますので挑戦してみてください。
まとめ2
今回はpivot_longer, widerの色々な使い方にも触れてみました。
前半は基本的な考え方、後半は実用的な場面で使える方法を紹介したつもりです。集計やグラフ作成でよく使うのでぜひ実際にコードを書いて挑戦してみてください。