
2章の知識を使った課題

第2章ではtidyverse(特にdplyr)を使ったdata.frameの扱い方について紹介しました。
ここでは実際に架空データを扱ってみます。
今回は解法はいくらでもあります。人によってぜんぜん違うかもしれません。めんどくさく1つずつ手打ちする面倒くさい方法もあれば少ないコードで一気にしてしまう方法もあります。
今ならChatGPTやGeminiに相談すればすぐに教えてくれます。ただどう質問すればいいだろう?と質問するスキルもそれなりに必要だったりします。
質問スキルを上げるためにいきなり回答を答えてもらう
(問題自体が質問するヒントにもなります)自分がコードを書いた上でChatGPTに答え合わせや別解を示してもらう
コードを書くうえでのコーチになってもらう
ちなみにRのtidyverseを使ってと伝えると第2章の復習になります。
どんな使い方でもいいと思います。課題を出すサイトなんてなかなかないので遊びで使ってみてください!
使うデータ
#pacmanパッケージがあるかを確認。なければinstall.packagesパッケージをインストール
if (!require("pacman")) install.packages("pacman")
#今回使うパッケージ
pacman::p_load(tidyverse, rio)
#データの読み込み
url <- "https://github.com/mitti1210/myblog/raw/master/FIM.xlsx"
data1 <- import(url, which = 1, skip = 2) |> mutate(回数 = "1回目") |> rename(id = 1)
data2 <- import(url, which = 2, skip = 2) |> mutate(回数 = "2回目") |> rename(id = 1)
data3 <- import(url, which = 3, skip = 2) |> mutate(回数 = "3回目") |> rename(id = 1)
#データの加工
set.seed(1)
row1 <- sample(1:100, 80)
set.seed(2)
row2 <- sample(1:100, 80)
set.seed(3)
row3 <- sample(1:100, 80)
data1 <- data1[row1,]
data2 <- data2[row2,]
data3 <- data3[row3,]
#データの確認
head(data1)
head(data2)
head(data3)
#余分な変数の削除
rm(row1, row2, row3, url) 今回はFIMという身の回りのことがどれくらい1人でできるか?介助が必要か?というテストを使います。ちなみにFIMは1点から7点までの整数で18項目あり、合計は18点〜126点満点となっています。食事〜階段までの13項目を運動項目、表出〜記憶の5項目を認知項目といいます。他にもid・年齢・性別があります。
data1, data2, data3はそれぞれ1回目〜3回目と繰り返し測定しています。
ただ、もともとの100人のデータなのですが、80人ずつ抽出しidの順番もバラバラにしました。そのためデータがない人もいます。
課題1
data1のidとFIM_運動合計, FIM_認知合計, FIM_合計の4列にする
FIM_合計の平均値より高いものだけを抽出する
結果をkadai_01という変数名に入れてください。
44行4列になっていればOK

ちなみに平均値は86.8875…
忘れてしまった方はこちら
課題2
kadai_01を使う
新たにFIM_合計2という列名を作る
FIM_運動合計 + FIM_認知合計を足したもので作る更に差という列名を作る
FIM_合計 - FIM_合計2で計算する結果をkadai_02に格納する

忘れてしまった方はこちら
課題3
data1, data2, data3を使う
全てを縦につなげる
1回目, 2回目, 3回目それぞれのFIM_運動合計, FIM_認知合計, FIM_合計を集計する
結果をkadai_03に格納する

忘れてしまった方はこちら
課題4
課題3で平均を求めたが、欠損データがあるデータです。
今data1, data2, data3全てにデータがある(idがある)人だけを抽出する
全部で何人?
そしてidをベクトルとして抽出したものをindexという変数に格納する

第2章の方法でも、伝えていない全く違う方法でもできます。
2章の方法で行うとすればこちら
課題5
data1, data2, data3を先程のindexに当てはまる人だけにしてdata1_index, data2_index, data3_indexを準備する。
data1_index, data2_index, data3_indexを使う
このように集計して、kadai_05に格納する

ヒントはこちら
課題6
kadai_05を使う
以下のようにwideデータにしてkadai_06に格納する

課題7
data1_index, data2_index, data3_indexを使う
idとFIM_合計の列のみ使う
FIM_合計の列名は1回目をfirst, 2回目をsecond, 3回目をthirdと変更する
以下のように整形する(同じ人の時系列がわかる)
idの並び順は自由でいいです。今回はアルファベット順にしています。arrange(id)とするとidがアルファベット順になります
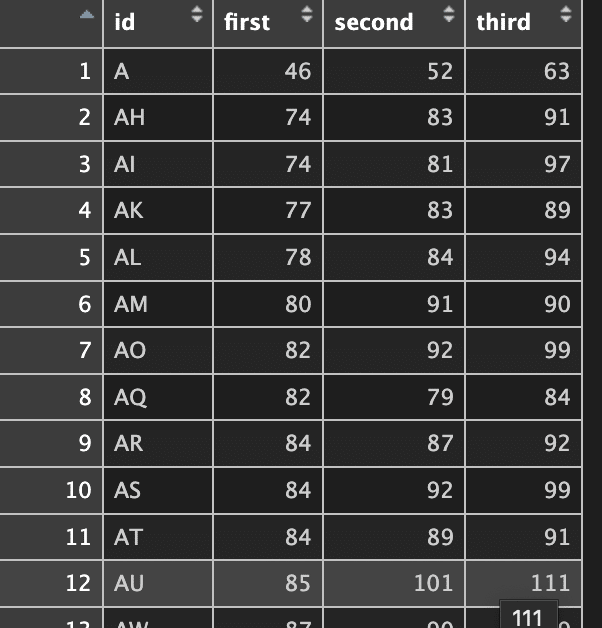
全く同じコードになったら、それはもうすごい確率かも
まとめ
今回は第2章を使った課題を紹介しました。
このあたりができるようになると業務効率が10倍以上変わります。
Excelなら毎回コピペするのがRなら1度コードを書いてしまえば後は一瞬です。データが1万行増えてもコードは変わりませんので。