
【2-6】複数のdata.frameを横につなげる(bind_cols, joinの使い方)

はじめに
【2-5】複数のdata.rameを縦につなげるではdata.frameを縦に繋げました。
今回は横に繋げる方法を紹介します。
例えば"基本情報"と"実際のテスト"という複数のcsvやExcelのデータがあるとします。ここでそれぞれにあるidを揃えてデータがつながると便利ですよね(ExcelだとVlookupです)。他にもデータの構造上行数が揃っている場合もあります(患者の入院時・退院時のような時系列データの場合など)。この場合はidなど気にせずそのまま繋げてもいい場合もあります。
今回のbind_colsやjoinが使えるようになると1つの大きなデータベースにつなげるのではなく、複数のファイルで管理できるようになります。
データの準備
#pacmanパッケージがあるかを確認。なければinstall.packagesパッケージをインストール
if (!require("pacman")) install.packages("pacman")
#今回使うパッケージ
pacman::p_load(dplyr, rio)
#データの準備
url <- "https://mitti1210.livedoor.blog/data.xlsx"
基本情報 <- import(url, which = "基本情報")
入院 <- import(url, which = "入院", skip = 2)
退院 <- import(url, which = "退院", skip = 2)
head(基本情報)
head(入院)
head(退院)
入院:"時期" "id" "入院日" "氏名" "評価日" "testA_1" "testA_2" "testA_3" "testA_4" "testB_1" "testB_2" "testB_3" "testC"
退院:"時期" "id" "入院日" "氏名" "評価日" "testA_1" "testA_2" "testA_3" "testA_4" "testB_1" "testB_2" "testB_3" "testC"
今回はそれぞれのdata.frameの同じ行は同じ人になっています。
bind_cols()を使う場合
今回はそれぞれのdata.frameの同じ行が同じ人になっているので、順番を気にせずに横につなげることが可能です。
縦に繋げたときはbind_rows()でしたが、今回の場合はbind_cols()が使えます。重ねて伝えますがもし1行でも順番がズレていたらズレて繋がりますので注意が必要です。
今回は次のケースを想定してみましょう
id, 氏名, 年齢, 性別, 入院のtestC, 退院のtestCを抽出してつなげる
#データの準備
# 基本情報のid, 氏名, 年齢, 性別をtemp_基本情報として抽出
temp_基本情報 <- 基本情報 |> select(id, 氏名, 年齢, 性別)
# 入院のtestCをtemp_入院として抽出
temp_入院 <- 入院 |> select(testC_入院 = testC)
# 退院のtestCをtemp_退院として抽出
temp_退院 <- 退院 |> select(testC_退院 = testC)必要な列をselect()を使って列を抽出しています。
更にselect(新しい列名 = 元の列名)で列名も同時に変更しています。
selectの基本的な使い方は【2-2】、列名を変える方法は【2-4】で紹介しています。

# temp_基本情報, temp_入院, temp_退院をbind_colsで結合
temp <- bind_cols(temp_基本情報, temp_入院, temp_退院)
head(temp)
ただしそれぞれのdata.frameが1行でもずれると結果が狂うので次に紹介するjoinの方が使われるかもしれません。
left_join()
joinは複数のdata.frameをid等のキーになる列を使って繋げる方法です。
そのため行の順番がバラバラでも結合が可能です。
joinにはleft_join()やright_joinなど色々な結合がありますが、まずここではExcelのVLOOKUPと似たleft_joinに関して説明します。
説明のためにslice()を使って行を間引きます。
# 基本情報のid, 氏名, 年齢, 性別をtemp_基本情報として抽出
temp_基本情報 <-
基本情報 |>
select(id, 氏名, 年齢, 性別) |>
slice(1:13) # 1~13行目を抽出
# 入院のtestCをtemp_入院として抽出
temp_入院 <-
入院 |>
select(id, testC_入院 = testC) |>
slice(1:8) # 1~8行目を抽出
# 退院のtestCをtemp_退院として抽出
temp_退院 <-
退院 |>
select(id, testC_退院 = testC) |>
slice(4:13) # 4~13行目を抽出 
基本的な使い方

# temp_基本情報, temp_入院, temp_退院をidをキーにして結合
temp<-
temp_基本情報 |>
left_join(temp_入院, by = "id") |>
left_join(temp_退院, by = "id") 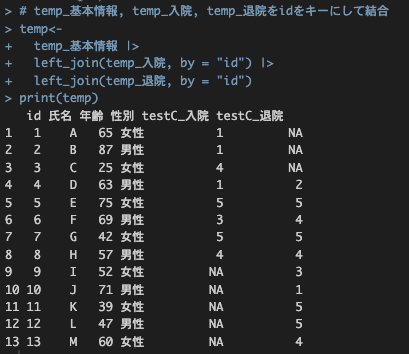

1つ目は1~13がある
2つめ以降は条件に合ったkeyのみ結合される
無いデータはNAとなる
1つ目のdata.frameを変えてみる
ここで1つ目のデータフレームを変えて検証してみます。
# 1つめのdata.frameを変えてみる
temp <-
temp_入院 |>
left_join(temp_基本情報, by = "id") |>
left_join(temp_退院, by = "id")
print(temp)

このようにleft_join()は順序が大切です。
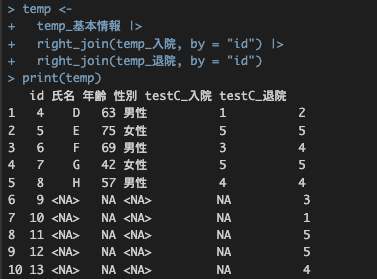
right_join()
right_join()は2つ目のdata.frameを基準とします。
次のコードでleft_joinとright_joinの違いを確認してみてください。
# right_joinを使ってみる
temp <-
temp_基本情報 |>
right_join(temp_入院, by = "id") |>
right_join(temp_退院, by = "id")
print(temp)

慣れるまでは頭の中でのイメージと実際の結果が合っているかをその都度確認したほうがいいかなと思っています。
inner_join()
inner_join()は両方に含まれている行を抽出して繋げます。
# inner_joinを使ってみる
temp <-
temp_基本情報 |>
inner_join(temp_入院, by = "id") |>
inner_join(temp_退院, by = "id")
print(temp)

full_join()
full_join()はすべての行が含まれます。
# full_joinを使ってみる
temp <-
temp_基本情報 |>
full_join(temp_入院, by = "id") |>
full_join(temp_退院, by = "id")
print(temp)

left_join()とは違い、最初にtemp_入院を先にしても上記の結果になります
繋げたい列名が異なる場合
joinで列をつなげる際、ファイルによっては列名が違うこともあります。
その場合はby = c("左の列名" = "右の列名")で設定可能です。
# by = でつなぐ列名が違う場合
# temp_入院のid をIDに変更
temp_入院 <-
temp_入院 |>
rename(ID = id)
temp <-
temp_基本情報 |>
left_join(temp_入院, by = c("id" = "ID")) 行内に重複した値がある場合
行内に複数同じ物があるとどうなるのでしょうか?
新しいデータを使って確認します。
temp_基本情報 <-
基本情報 |>
select(id, 氏名, 年齢, 性別)
temp_入院 <-
入院 |>
select(id, testC_入院 = testC)
入院日が違いますので2回目の入院と判断できます
この状態でidを使ってleft_join()を行います。
すると元々20行だったtemp_基本情報がleft_join()の後は22行に増えます。
temp <-
temp_基本情報 |>
left_join(temp_退院, by = "id")
print(temp)
なぜこのようなことが起こったかはWarning messageにヒントがあります。
Warning message:
In left_join(temp_基本情報, temp_退院, by = "id") :
Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 1 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship = "many-to-many"` to silence this warning.
x` と `y` の間に予期しない多対多の関係が検出されました。
ℹ `x` の行 1 は `y` の複数の行にマッチします。
ℹ `y` の 1 行目が `x` の複数の行にマッチする。
ℹ 多対多のリレーションシップが予想される場合は、`relationship = "many-to-many"`を設定して、この警告を消してください。
先程の結果を確認します。特に入院日と評価日を確認してみます。

結果行が増えた
このように元の行よりも増えた場合はこのようなケースが考えられます。
もし複数の組み合わせを意図的に作ってこうするのならいいのでしょうが、多くの場合は増やすつもりじゃないのになぜか増えたということがあります。その場合は大抵、それまでのコードになにか問題があったか、今回のjoinの設定が間違っている可能性があります。経験的にはこのような問題が起こったら、今までの経過を1つずつ振り返って検証することをおすすめします。
今回の場合でいうとidと入院日の2つをkeyとすることで1対1対応できそうです。
複数の列を使ってjoinを行う
temp_退院を修正します。具体的には入院日を追加します。
# temp_退院を修正
temp_退院 <-
退院 |>
select(id, 入院日, 評価日, testC_退院 = testC)
print(temp_退院)
# id と 入院日をキーにして結合
temp <-
temp_基本情報 |>
left_join(temp_退院, by = c("id", "入院日"))
print(temp)

このように1対1対応するにはby = ""をどうすると1対1対応になるかを考えることが必要です。
繋げる列以外でそれぞれに同じ列名が合った場合
もしby = … 以外で同じ列名があると2つのデータフレームで列名が競合してしまいます。そのような状況では列名がかぶらないように自動的に.xや.yといった文字が付きます。
# データを修正
temp_基本情報 <-
基本情報 |>
select(id, 氏名, 年齢, 性別, 入院日)
temp_入院 <-
入院 |>
select(id, 入院日, 評価日, testC)
temp_退院 <-
退院 |>
select(id, 入院日, 評価日, testC)
temp <-
temp_基本情報 |>
left_join(temp_入院, by = c("id", "入院日")) |>
left_join(temp_退院, by = c("id", "入院日"))
print(temp)

.xは最初のdata.frame(temp_入院)
.yは2番めのdata.frame(temp_退院)
この.xと.yを変更するにはsuffix = c(".xの代わり", ".yの代わり")を使います。
# suffixをつけてみる
temp <-
temp_基本情報 |>
left_join(temp_入院, by = c("id", "入院日"), suffix = c("_入院", "_退院")) |>
left_join(temp_退院, by = c("id", "入院日"), suffix = c("_入院", "_退院"))
print(temp)

まとめ
今回はjoinを使い複数のdata.frameを繋げる代表的な方法を紹介しました。
この方法を使うと複数のデータベースをつなぐことができるようになり、分析の幅が大きく広がります。使用頻度も高いですのでぜひ実際にコードを書きながら挙動を確認してみてください。