
【1/28-2/3】生成AIニュース/調達/研究-Weeklyまとめ

ニュース
・OpenAI、投資先へのGPT-4などへの早期アクセス提供
OpenAI は、 投資先への特別特典として、GPT-4やWhisperなどへの早期アクセスなどを提供
https://www.theinformation.com/articles/openai-bolsters-ties-to-other-ai-startups-with-venture-investments?rc=5htos4

・AIのパイオニアがAI スタートアップ向けのRadical Venturesを支援
基盤を形成するモデルを構築している企業や幅広いAI アプリケーションに投資計画。
・OpenAIは月額 20 ドルで利用できるChatGPT Plus発表
ピーク時の応答時間の短縮や新機能や改善への優先など。
・ChatGPT、1月にMAU1億人達成
史上最速で成長したコンシューマー向けアプリケーション

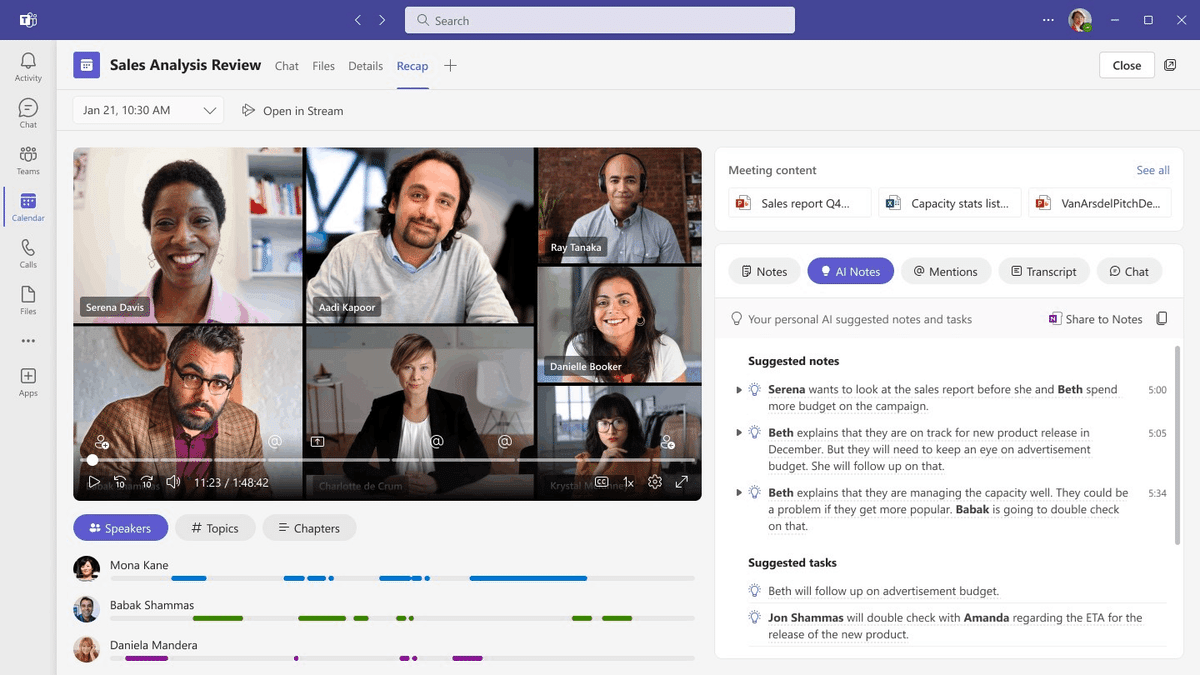
・Microsoft Teams Premiumの一般提供がスタート
自動会議メモ・要約、タスク推奨、パーソナライズ会議テンプレート、話者分離、リアルタイム翻訳など。2023年7月1日までならユーザーあたり月額7ドルで購入。以降は月額10ドル。
https://www.microsoft.com/en-us/microsoft-365/blog/2023/02/01/microsoft-teams-premium-cut-costs-and-add-ai-powered-productivity/
・D4VのSo Gormanさんによる生成AIまとめ
【内容】
1. Generative AIの背景
2. Generative AIの現状
3. Generative AIの活用例
4. 誰がGenerative AIの時代を制するのか?
・生成AI「ChatGPT」と日本の新たな可能性
落合さんとOpenAIの強化学習リーダーのシェイン・グウさんとの対談
・背景画に画像生成を活用したショートムービー
Netflix × アニメ・クリエイターズ・ベース × 技術開発のrinna株式会社 × WIT STUDIOによる共同プロジェクトアニメ『犬と少年』
https://about.netflix.com/ja/news/the-dog-and-the-boy
Netflix アニメ・クリエイターズ・ベース×技術開発のrinna株式会社×WIT STUDIOによる共同プロジェクトアニメ『犬と少年』のショートムービー。
— Netflix Japan | ネットフリックス (@NetflixJP) January 31, 2023
人手不足のアニメ業界を補助する実験的な取り組みとして、3分間の映像全カットの背景画に画像生成技術を活用! pic.twitter.com/GYuWONSqlJ
・ゲーム開発に生成AIを利用した事例
ゲーム開発者が、AI の助けを借りてゲームを構築した各ステップについて報告。時間を50% ~ 80%短縮したとのこと
https://echoesofsomewhere.com/category/devblog/

・仮想世界(ゲーム、シミュレーション、メタバースアプリケーション)関連の生成AIマーケットマップ
https://t.co/rXkwWibaVX

調達
・Anthropic(約3億ドル)
OpenAI の競合であるAnthropic はGoogleから3億ドルを調達。同社の総評価額は50億ドルに達する可能性。 ちなみに、2022 年にシリーズ AとシリーズBの資金調達ラウンドで 7億400万ドルを調達している (シリーズ B の多くは、あのFTX創設者とのこと)
・EasyTranslate(約300万ドル)
アムステルダムの Pride Capital Partners がデンマーク語の翻訳ソフトウェア EasyTranslate に 約300万ドルを投資
・Libristrip(約210万ドル)
AI を活用して、環境に配慮した旅行者向けにパーソナライズされた旅程を生成および予約するLibristripが210万ドル調達
・Lavender(約1,300万ドル)
AIを活用したメールマーケティングのLavenderが1,300万ドル調達。メールプロバイダーと統合して、見込み顧客に関するコンテキストを提供し、メッセージを最適化して返信を得る方法を提案する。
・Supernormal(約1,000万ドル)
会議の自動文字起こしと要約、そしてアクションと重要な決定を抽出できるSupernormalが 1,000万ドルを調達。
研究
・Noise2Music
テキストプロンプトから高品質の30秒の音楽クリップを生成
論文: https://arxiv.org/abs/2302.03917
プロジェクト: https://google-research.github.io/noise2music/
Noise2Music: Text-conditioned Music Generation with Diffusion Models
— AK (@_akhaliq) February 9, 2023
introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts
abs: https://t.co/r6RdpVTSKz
project page: https://t.co/odJiFOc2rk pic.twitter.com/7nYwtL2vvL
・Make-An-Audio
プロンプトを強調した拡散モデルによるテキストからオーディオ生成
論文: https://text-to-audio.github.io/paper.pdf
プロジェクト: https://text-to-audio.github.io
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models by @RongjieH
— AK (@_akhaliq) January 29, 2023
project page: https://t.co/vdobbcEtDj
paper: https://t.co/OPpqchwKaf pic.twitter.com/DSGnw1GTBd
・Tuning-A-Video
学習済みのテキスト画像生成モデルを、1セットのテキスト×動画セットでチューニングすることで、テキスト動画生成モデルを作成できる
非公式hugging face demo: https://huggingface.co/spaces/Tune-A-Video-library/Tune-A-Video-Training-UI
github: https://github.com/showlab/Tune-A-Video

・形状を認識したテキストによる動画編集
論文: https://arxiv.org/abs/2301.13173
プロジェクト: https://text-video-edit.github.io
Shape-aware Text-driven Layered Video Editing
— AK (@_akhaliq) January 31, 2023
abs: https://t.co/yTFVrN13Pr
project page: https://t.co/OodT8tRB8Y pic.twitter.com/boOF7A7JkT
・GeneFace: 高精度なオーディオ to 3Dトーキングフェイス生成
論文: https://arxiv.org/abs/2301.13430
プロジェクト: https://geneface.github.io
GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis
— AK (@_akhaliq) February 1, 2023
abs: https://t.co/fz869Nh5Ac
project page: https://t.co/bwXO4PZFR2 pic.twitter.com/1n6KjUuOaF
・Dreamlx: 画像or動画とプロンプトから新しい動画生成
論文: arxiv.org/abs/2302.01329
プロジェクト: https://dreamix-video-editing.github.io
Dreamix: Video Diffusion Models are General Video Editors
— AK (@_akhaliq) February 3, 2023
abs: https://t.co/It6BuYHU8c
project page: https://t.co/Tks6bU4kmb
present diffusion-based method that is able to perform text-based motion and appearance editing of general videos pic.twitter.com/Milx6UeXau
・SceneDreamer: 複数の2D画像から無限の3D シーン生成
github: scene-dreamer.github.io
論文: https://arxiv.org/abs/2302.01330
動画: https://youtube.com/watch?v=AjtOlDHsiyU&feature=youtu.be…
SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections
— Aran Komatsuzaki (@arankomatsuzaki) February 3, 2023
proj: https://t.co/HiVpuuyju4
abs: https://t.co/Rd0OcK781B
video: https://t.co/UCoLnFMfk7 pic.twitter.com/Sym8ylzGVT
・SceneScape: テキストによる一貫したシーン生成
論文: https://arxiv.org/abs/2302.01133
プロジェクト: https://scenescape.github.io
SceneScape: Text-Driven Consistent Scene Generation
— AK (@_akhaliq) February 3, 2023
abs: https://t.co/QO0jVxzcoQ
project page: https://t.co/vK8RmTJ8wr
text-driven perpetual view generation -- synthesizing long videos of arbitrary scenes solely from an input text describing the scene and camera poses pic.twitter.com/DGFnjqgZa9
・Instructpix2pixを動画に適用
動画をゴッホ風に変換した事例
Yep, looks more stable. It's a totally different way of prompting and sometimes doesn't work at all but check out the background in this video. I want to see how much impact negative prompts make. How to use the text and image cfg etc
— TomLikesRobots (@TomLikesRobots) January 29, 2023
"Make it a Van Gogh Painting" pic.twitter.com/fqILt7QOvt
・Moûsai
長いコンテキスト踏まえたテキストから音楽生成
論文: https://arxiv.org/abs/2301.11757
github: https://github.com/archinetai/audio-diffusion-pytorch
プロジェクト: https://anonymous0.notion.site/anonymous0/Mo-sai-Text-to-Audio-with-Long-Context-Latent-Diffusion-b43dbc71caf94b5898f9e8de714ab5dc
Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
— AK (@_akhaliq) January 30, 2023
abs: https://t.co/DQ3MEM1daS
github: https://t.co/qJwOLj4k6l pic.twitter.com/aJ376GMcxd
・テキストから音楽生成をするAudioLDMのデモ https://huggingface.co/spaces/haohelu/audioldm-text-to-audio-generation
try out the @Gradio Demo for AudioLDM: Text-to-Audio Generation with Latent Diffusion Models on @huggingface
— AK (@_akhaliq) February 2, 2023
demo: https://t.co/uH4ktCDVUN https://t.co/KwKuhOzY0y pic.twitter.com/aqZ6TpPK9d