
3. 土木遺産データ整形してみます

まず、身近なところで京都府のデータをサンプルにやってみます。
WEBのデータはこんな見た目です。

上段に市町村名(京都はややこしいことに京都市〇〇区が存在します)、
その下段に都道府県名を挟んで
最後に土木遺産のデータが入っています。
■WEBデータをどうやって取り込むか?
①WEBキャプチャでいけるか?
②PDFは?
③やっぱりエクセルに張り付けか・・・
①②はダメ元でやってみます。
まず、①WEBキャプチャどーん!

京都府だけでえらいことになってしまいました。

さすがにモニョモニョです。こんなの初めて見ました。。。
Prepさんごめんなさい。。。

PDFも同じく。範囲の指定をやり直してみたりしましたが駄目でした。
Desktopでもやってみましたが、見たことのないエラーが・・・

で、大人しく③エクセルに張り付けで真面目にチャレンジします。
■WEBデータをエクセルに張り付けて取り込む
WEBページの範囲を全選択して、エクセルシートに貼ってみます。
もっと賢いやり方がありそうですが・・・

上段は削除して、都道府県名以下のデータの形にして読んでみます。

上段に都道府県名も残したままなので(後でデータが確認しやすいのでそのままに)
まま、こうなるかな~とは思っていました。
ここでデータインタプリターマジック(もはや魔法だと思っています)!

大体読めている感じです。
ここで、元データ×エクセルの不安材料を再確認していきます。
①1レコードが2段になっているケースがある
②空欄の行が多数存在する
③価値評価欄に画像(赤丸にA)が存在する


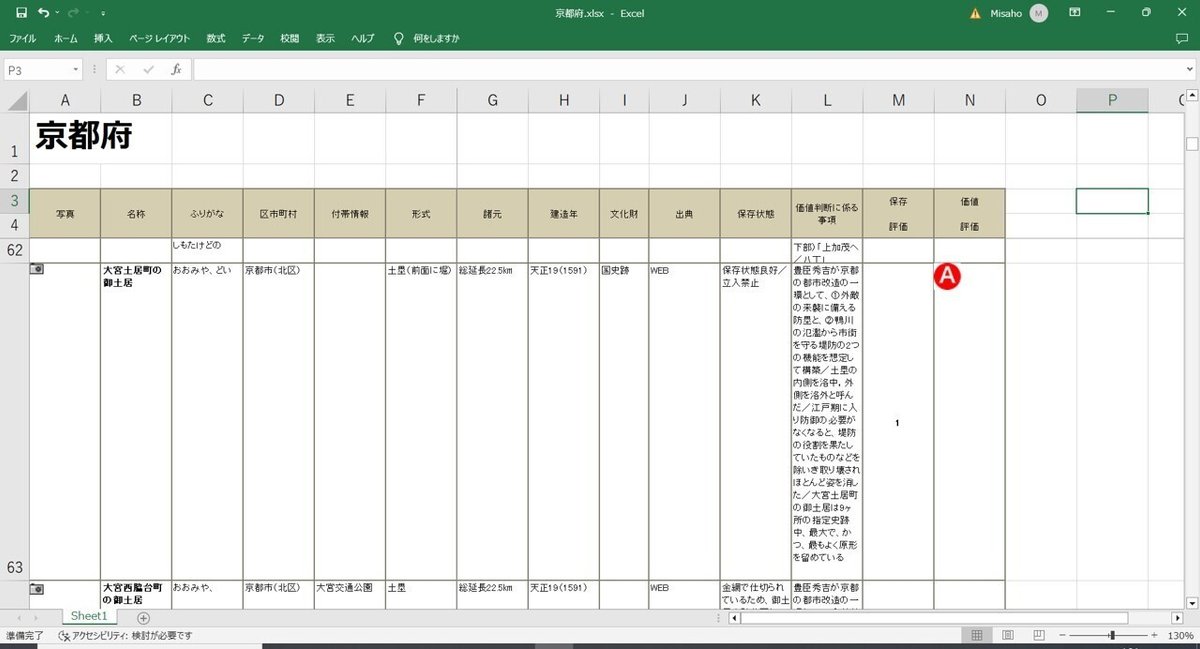

どうやら②は問題なさそうです(データ行とデータフィールドを確認)。
①はやはり2行になってしまっている様子。。。

③はNULLになっているようです。

というところで、今日はこの辺で。
①③解決できるでしょうか・・・