数値に基づくポリゴンの色分け(自然分類) | R, GIS

この記事では、Rを使った、数値に基づくポリゴンの色分け(自然分類)について説明します。
記事の概要です。
まず、前回の記事を参考に、シェープファイルとCSVファイルを結合します。
次に、色分けに使う値(2020年の推計人口)をグループ分けします。
グループ分けには、変化が大きいところで区切る「自然分類」を用います。
そして描画時、geom_sfのfill引数にグループ分けした数値のカラムを渡すと、数値(グループ)に基づいたポリゴンの色分けがなされます。
プログラム全体を示します。
## シェープファイルとCSVファイルを結合
library(sf)
shp <- st_read("./data/N03-20150101_08_GML", options = "ENCODING=SHIFT-JIS")
d <- read.csv("./data/kekkahyo1_ibaraki_2015-2045.csv")
library(dplyr)
shpCsv <- left_join(shp, d, by = c("N03_004" = "市区町村"))
## 2020年の推計人口を、自然なブレイク(Jenks)で5グループに分ける
## 確認:2020年の推計人口
summary(shpCsv$cy2020)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 89.20 93.50 95.20 95.28 96.55 104.30
## 確認:グループの境界
library(BAMMtools)
getJenksBreaks(shpCsv$cy2020, 6) # 第2引数には"グループの数+1"を与える
## [1] 89.2 92.4 94.3 97.0 100.5 104.3
## 5グループに分ける
Breaks <- getJenksBreaks(shpCsv$cy2020, 6)
Labels <- c("89.2 - 92.4", "92.4 - 94.3", "94.3 - 97.0",
"97.0 - 100.5", "100.5 - 104.3") # 各グループのラベル
shpCsv$cy2020Grp <- cut(shpCsv$cy2020, breaks = Breaks,
labels = Labels, include.lowest = T) # グループ化した結果をcy2020Grpカラムへ
## 描画
library(ggplot2)
ggplot(shpCsv) + geom_sf(aes(fill = cy2020Grp)) +
scale_fill_brewer(palette = "Reds") # QGISに合わせ、赤色のグラデーションにするこの記事で使用したRとパッケージのバージョンを記載しておきます。
R 3.6.1
sf 0.7-6
dplyr 0.8.3
BAMMtools 2.1.6
ggplot 3.2.0
準備
BAMMtoolsパッケージをインストールします。
このパッケージは、色分けに使う値(2020年の推計人口)をグループ分けするときに使います。
このパッケージのgetJenksBreaks関数により、変化が大きいところで数値を分類する「自然分類」が使えるようになります。
インストールの仕方は、こちらを参考にして下さい。
※他のパッケージもインストールしていない場合は、インストールが必要です。
数値に基づくポリゴンの色分け
CSVデータをシェープファイルに結合
前回の記事を参考にCSVデータをシェープファイルに結合します。
## シェープファイルとCSVファイルを結合
library(sf)
shp <- st_read("./data/N03-20150101_08_GML", options = "ENCODING=SHIFT-JIS")
d <- read.csv("./data/kekkahyo1_ibaraki_2015-2045.csv")
library(dplyr)
shpCsv <- left_join(shp, d, by = c("N03_004" = "市区町村"))色分けに使う値(2020年の推計人口)のグループ分け
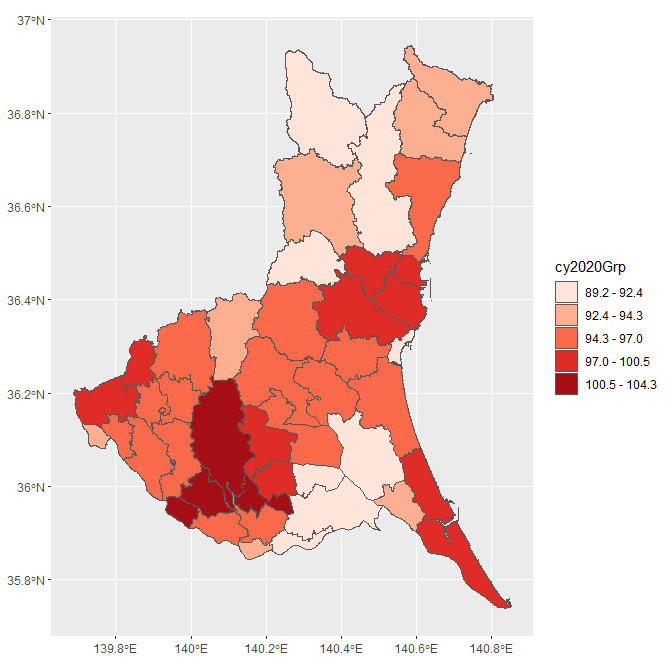
今回は、茨城県にある各市町村の2020年推計人口でポリゴンを色分けします。
QGISの記事と対応づける為、2020年の推計人口を5グループに分類します。
まず、2020年推計人口の確認です。
> summary(shpCsv$cy2020)
Min. 1st Qu. Median Mean 3rd Qu. Max.
89.20 93.50 95.20 95.28 96.55 104.30 5つのグループに分ける範囲は、最小値89.2から最大値104.3までの範囲になります。
次に、グループ分けしたときの境界値を確認しましょう。
> library(BAMMtools)
> getJenksBreaks(shpCsv$cy2020, 6) # 第2引数には"グループの数+1"を与える
[1] 89.2 92.4 94.3 97.0 100.5 104.3QGISのときと同じ値(89.2, 92.4, 94.3, 97.0, 100.5, 104.3)が境界値になっていますね。
では、5つのグループに分けます。
Breaks <- getJenksBreaks(shpCsv$cy2020, 6)
Labels <- c("89.2 - 92.4", "92.4 - 94.3", "94.3 - 97.0",
"97.0 - 100.5", "100.5 - 104.3") # 各グループのラベル
shpCsv$cy2020Grp <- cut(shpCsv$cy2020, breaks = Breaks,
labels = Labels, include.lowest = T) # グループ化した結果をcy2020Grpカラムへ数値のグループ分けには、cut関数を用いています。
そしてグループ分けした結果は、シェープファイルのcy2020Grpカラムに格納しています。
このように、データセットができれば、ほぼ完了です。
描画
描画します。
library(ggplot2)
ggplot(shpCsv) + geom_sf(aes(fill = cy2020Grp)) +
scale_fill_brewer(palette = "Reds") # QGISに合わせ、赤色のグラデーションにするQGISの記事に合わせ市町村名を入れようと思いましたが、止めました。
プログラムが複雑になるからです。
また、この記事の趣旨ではないため、凡例についての詳細は別記事で述べます。
以下のような地図が表示されれば完成です。
おわりに
お疲れさまでした。
グループ分けの処理はQGISに比べ複雑ですね。
しかし、cut関数を使ったこのグループ分けは、地図作成に限らず使えます。
ぜひ、覚えておいて下さい。