
【3.1独立運動】「朝鮮騷擾經過槪要」

この記事は、「韓国が独立を意識する日」としている3月1日に、justiceforjapan(@justiceforjapan)さんのTWの記載で存在を知り、これは、当時の公式文書として、皆が簡単に読める様にしたいとの想いで、OCR化し、可読性を高めた記事として行くつもりで立ち上げました。
紹介文献の取得先
この文献の取得先は次となります。
国立公文書館デジタルアーカイブ
簿冊標題:単行書・八年陸乙七一・朝鮮騒擾経過概要
https://www.digital.archives.go.jp/das/image/F0000000000000013850
「朝鮮騷擾經過槪要」OCR文字化データ
朝鮮騷擾經過槪要
陸軍省印刷 大正八年九月
国立公文書館
排架番号 2A 34-6 (单)2141
アジア歴史資料センター Japan Center for Asian Historical Records
目次
朝鮮騷擾經過槪要
目次
一、騒擾ノ起因 …………………………………… 一
二、騒擾ノ企畫 …………………………………… 二
其一 天道敎、耶蘇敎、佛敎徒等ノ聯盟 …… 二
其二 運動ノ著手 ……………………………… 三
其三 在外鮮人ノ關係 ………………………… 四
三、騒擾ノ經過 …………………………………… 四
其一 一般ノ經過 ……………………………… 五
其二 三月中ニ於ケル騒擾ノ槪況 …………… 六
其三 四月中ニ於ケル騒展槪況 ………………一一
其四 五月以降ニ於ケル騒擾ノ槪況 …………一六
四、騒擾間ニ於ケル在外鮮人ノ動靜 ……………一六
五、鎭壓ノ爲ノ處置 ………………………………一八
六、騒擾ニ關スル損害 ……………………………一九
一、騒擾ノ起因(ソウジョウ ノ キイン)
朝鮮騷擾經過槪要
一、騒擾ノ起因
大戰勃發以來在外不逞鮮人等ハ頻リニ祖國復興ノ急務ヲ叫ヒ居リシカ此風潮
ハ大正六年ニ入リ漸次其度ヲ高メ更ニ戰亂ノ務局ニ近クニ件ヒ歐洲ニ於テ遂
日旺盛トナリシ民族獨立運動ノ狀況朝鮮內ニ傳ハルヤ民心ニ動搖ヲ來シ次テ
獨逸ノ屈服トナリ米國大統領ニ依リ民族自決主義ノ提唱セラルルヤ之ニ關ス
ル諸種ノ報道ハ鮮人智識階級及青年子弟ヲ刺戟シ排日者ト否サル者トヲ問ハ
ス民族自決ノ思想ニ囚ハルルニ至レリ此ニ於テ天道敎徒、耶蘇敎徒首唱トナリ
前述最近ニ於ケル世界民心ノ急激ナル變化ニ乘シ鮮人ノ特性タル隴ヲ得テ蜀
ヲ望ムノ性情ヲ利用シ舊韓國時代ノ匪秕政ヲ忘レ彼等ノ平素抱懐セル日本ノ統
治ニ封スル不平不滿ハ勿論偶ゞ李太王ノ薨去ニ際會スルヤ薨去ノ原因等ニ關
聯シ有ユル虚構ノ事項ヲ暴ケテ民心ヲ煽リ遂ニ三月一日ヲ期シテ獨立運動ヲ
起スニ至レリ
二、騒擾ノ企畫
二、騒擾ノ企畫(キカク)
二、騒擾ノ企畫
其一 天道敎、耶蘇敎、佛敎徒等ノ聯盟
天道敎ハ宗敎トシテ認ムルノ價值ナク敎主等幹部ノ政治的野心ノ許ニ組織セ
ル團體ニ過キスシテ迷信ニ富ム國民性ヲ利用シテ愚夫愚婦ヲ惑ハシ敎主自ラ
荒唐無稽ノ操言ヲ傳ヘ(神託ト稱シ)其信仰ヲ繋持シ來リシモ民衆ノ文化漸ク
進ムニ從ヒ宗敎トシテノ根本的地位危カラントシ為ニ何等カノ方法ヲ講セサ
トハ其存否ノ運命ニ關スルコトヲ苦慮シツツアリシカ千九百十八年(大正七
年末)民族自決主義唱道セラルルヤ朝鮮ノ獨立ヲ企圖スルノ最好機會トナシ天
道敎ノ元老株ハ屢々會合ヲ重ネツツアリシカ一月下旬ニ至リシ獨立運動ノ實
行ヲ決意シ之ヲ敎主孫乗𠘕ニ計リ茲ニ天道敎ノ方針ヲ一定スルニ至レリ之レ
今囘ノ騒擾事件ノ發端トス然レトモ大ニ鮮人ノ輿論ヲ喚起シ列強ヲシテ朝鮮
人一般ノ意思表示ヲ認メシムルニハ天道敎ノ力ノミヲ以テスルノ不利ナルニ
鑑ミ協同運動ニ關シ耶蘇敎徒及佛敎徒ニ交渉スルコトニ決セリ依テ天道敎幹
部ハ耶蘇敎徒ト關係アル一有力者ヲ介シテ耶蘇敎徒間ニ交渉セシムルヤ同敎
徒ニアリテモ當時一般ニ民族自決主義祖國復興等ニ就テ論議シツツアリシ際
ナリシヲ以テ直ニ之ニ賛同セリ
佛敎ニアリテハ宗敎トシテノ地位頽廢其極ニ達シ残影ヲ僅二寺院ニ止ムルノ
悲境ニ鑑ミ天道敎ノ勧誘引受クルヤ將來自己ノ地位ノ向上ヲ期スル爲有利ト
ナシ直ニ天道敎徒ト事ヲ共ニスルニ至レリ
其二 運動ノ著手
三敎徒ノ協同聯盟ニ關スル協議成立スルヤ協議ノ結果成ルヘク青年有爲ノ士
及中學程度以上ノ学生ヲ勧誘シ之カ團結ヲ鞏固ニシ運動ニ參加セシムルヲ有
利ト認メ是等代表的人物ニ交渉シ其賛同ヲ得茲ニ愈ゞ運動ニ著手シ二月中旬
頃國權返還ニ關スル請願書、米國大統領及巴里講和會議ニ列席セル英、佛、米、
伊四國委員ニ提出スル獨立援助嘆願書ヲ起草シ三月一日迄ニ是等書類ヲ發送
セリ
又二月二十五日頃ニ於テ三月一日ヲ期シ愈ゞ獨立運動ヲ開始スルコトニ決定
シ獨立宣言書二萬一千枚ヲ印刷シ之ヲ京城市内及各地方ニ配布セリ而シテ本
運動ニ就テハ耶蘇敎側ハ日本內地及外國竝ニ在鮮外國人宣敎師ニ對スル運動
ヲ擔當シ天道敎側ニ於テ其費用ヲ負擔スルコトニ協定セリ
其三在外鮮人ノ關係
東京留學鮮人學生ハ二月八日東京ニ於テ窃ニ朝鮮基督敎青年會館ニ會合シ「民
族大會召集請願書」「獨立宣言書」等ノ印刷物ヲ各大臣、貴衆両院議員其他ニ郵
送スル等不穩ノ言動ヲナシ之ヲ朝鮮ニ通信シ陰ニ企圖シツツアル運動ヲ助成
セリ
在上海排日鮮人モ亦窃ニ代表者ヲ派遣シ耶蘇敎徒中主ナルモノヲ説テ獨立運
動ニ干與セリ
三、騒擾ノ經過(ケイカ)
三、騒擾ノ經過
其一 一般ノ經過
三月一日京城ニ於テ勃發スルト共ニ地方ニ於テハ平安南道平壌鎭南浦、安州、
平安北道義州、宣川、咸鏡南道元山ノ六箇所勃發シ次テ第二日ニ至リ黄海道
海州、遂安ノ兩地ニ起リ斯クテ以上ノ各道ノ各地ニ騒擾ヲ惹起シ日ヲ逐フテ各
道ニ憂リ斯クテ三月下旬ニ至リ遂ニ十三道ニ彌蔓シ同時期ヨリ四月上旬ニ亙
リ各所ニ續發スルノミナラス一般人ノ心著シク險悪ニ化シ警備機關ノ缺乏ニ
乗シ交通ノ便否ニ依リ遂次僻陬ノ地ニ波及ッ其手段ニ於テモ棍棒、鎌、鍬或ハ
竹槍又ハ稀ニ拳銃等ノ兇器ヲ使用シテ軍隊警務官憲ニ抵抗スルノミナラス官
公署又ハ學校ヲ襲ヒ放火又ハ破壊ヲナシ內地人家屋ニ對シテモ同樣ノ迫害ヲ
加ヘ或ハ巡査補、憲兵補助員ノ居宅ヲ侵シ其甚タシキニ至リテハ警察官ヲ惨殺
スル等獰猛ヲ極メ暴戻至ラサル所ナカリシカ四月中旬ニ至リ之ニ對スル官憲
ノ處置モ漸ク峻厲ヲ加フルト共ニ槪シテ四月中旬末以後ニ至リ各道共ニ殆ン
ト騒擾ノ跡ヲ斷テリ而シテ是等各地ニ於ケル騒擾者ハ當初多クハ耶蘇敎徒、天
道敎徒又ハ是等ニ關係アル學生ヲ主トセシモ遂日機敏且巧妙ナル煽動ハ心ナ
キ一般ノ人民ヲモ驅リテ騒擾ノ渦中ニ投セシムルニ至レリ
其二 三月中ニ於ケル騒擾シ槪況
1 京畿道
三月一日約三、四千名ノ學生ハ豫定ノ通リ「パコタ」公園ニ集合シ獨立宣言書
ヲ朗讀シ示威運動ヲ開始スルヤ群衆之ニ附加シ其數十萬ニ達シ市中ヲ練リ廻
リシカ當日李太王國葬拜觀ノ爲地方ヨリ入京中ノ者數十萬ニ達シ混雑名狀ス
ヘカラス依テ總督ハ軍隊ヲシテ警務官憲ヲ援助シ治安ノ維持ニ務メシ爲三月
中旬末ニ至ル迄ハ表面槪ネ靜穩ヲ維持シタルカ三月下旬ニ至リ市内各所及京
城近郊ノ郡部ニ騒擾績發シ從來ノ示威運動ハ漸次悪化シ京城市中ニ於テハ電
車ニ投石乗客ヲ脅迫シ又ハ警官派出所ヲ襲ヒ投石暴行又ハ之ヲ破壊シ警官ノ
制止ヲ肯セス頑強ニ抵抗ヲ試ムル爲官憲側ト衝突シ彼我多少ノ死傷ヲ生スル
ニ至レリ
郡部ニ於テモ二十一日以後八十餘箇所ニ騒擾勃シ或ハ憲兵、警察官署、郵便
所、面事務所ヲ襲ヒ又ハ內地人民家ニ放火スル等暴行ヲナシタルモノ尠カラス
就中暴民ノ最モ暴行ヲ逞フセシハ水原、安城地方ニシテ放火破壊ハ勿論內地人
巡査一名ヲ虐殺スル等兇暴ノ度本月ニ於ケル騒擾ヲ通シ稀ニ見ル所ナリ
2 忠清北道
十日満州學校生徒ノ騒擾ニ始マリ十郡中ノ四郡數箇所ニ於テ騒擾シ京畿道ニ
於ケル暴民ノ範ニ倣ヒ二、三箇所ニ於テハ官憲ニ抵抗スルニ至レリ
3 忠清南道
十日論山郡江景ニ騒擾勃發シ次テ他ノ二十餘箇所ニ騒擾ヲ惹起シ或ハ兇器ヲ
携ヘ憲兵駐在所ヲ襲ヒ銃器ヲ奪取セント企テ又電線ヲ切断シ其他警察署ノ破
壊ヲナス等ノ暴行ヲナセリ
4 全羅北道
數箇所ニ於テ運動ヲ企テシモ葵樹ニ於テ暴民カ警察官駐在所及面事務所ニ押
寄セ暴行セシ外執レモ大事ニ至ラス
5 全羅南道
五箇所ニ於テ九囘ニ亙リ示威運動ヲナシタルノミニテ何レモ大事ニ至ラスシ
テ鎭静セリ
6 慶筒北道
八日大邱ニ於ケル學生ノ示威運動ニ始マリ各地ニ波及シ十一日以降二十餘箇
所騒擾勃發シ就中安東、盈德、義城及青松郡內ニ於テハ暴民狂暴ヲ逞フシ頑
強ニ抵抗シ殊ニ安東ニ於テハ郡廳、法院支廳、警察署及警察官駐在所ヲ襲ヒ投
石暴行又ハ破壞ヲ試ムル等ノ行為アリ
7 慶何南道
十一日釜山鎭ニ於ケル耶蘇敎學生ノ示威運動ニ始マリ二十餘箇所騒擾ヲ惹
起シ郡廳、警察官駐在所、郵便所、登記所、面事務所、学校等ヲ襲ヒ之ヲ破壊スル
等暴行ヲ逞フセルモノ紗カラス
8 黄海道
二日天道敎徒ヲ主トスル多數ノ暴民黄州警察署ヲ襲ヒタルニ始マリ三十餘箇
所ニ騒擾勃發シ就中遂安ニ於テハ暴民百餘名郡廳憲兵分隊ヲ引渡スヘシト稱
シ憲兵分隊構內ニ殺到シ暴行ヲナシ其他各所ニ於テ憲兵官署ニ來襲シ狂暴ヲ
逞フセルモノ紗カラス
9 平安南道
本道ハ今囘騒擾ノ主謀者タル耶蘇敎及天道敎ノ勢力最モ旺盛ナル關係上各地
共密接ナル連絡アリシカ如ク一日ヨリ十日間ニ於テ三十餘箇所ニ騒擾ヲ勃發
シ其後表面不穩ニシテ三月中ニ於テ僅ニ數箇所ニ騒擾アリタリ而シテ其狂暴
京畿道郡部ニ讓ラサルモノアリ就中成川ニ於テハ暴民數百棍棒、鎌、斧等ヲ携
帶憲兵分隊ニ來襲シ破壊其他ノ暴行ヲナシ憲兵ハ極力防衛ニ努メ遂ニ之ヲ解
散セシムルニ至リタルカ之カ爲憲兵分隊長ハ重傷後死亡シ暴民側ニ六十餘名
ノ死傷者ヲ生シ孟山ニ於テモ成川ト同樣ノ暴行ヲナシ爲ニ憲兵一名其兇手ニ
斃レ暴民ニモ五十餘名ノ死傷者ヲ出セリ沙川ニ於テハ憲兵四名暴民ノ包圍ヲ
受ケ極力鎭壓ニ努メタルモ彈樂盡キ全員兇手ニ斃レ駐在所ハ放火セラルルニ
至レリ
10 本安北道
前後數囘ニ亙リ騒擾シ混雑ヲ極メタルハ耶蘇敎徒最モ多キ宣川ニシテ量壇者
ノ數多キトキハ六千名ニ上レリ其他三十餘箇所ニ渉リテ騒擾シ暴民狂暴ヲ逞
フセシ箇所炒カラス
11 江原道
十日鐵原ニ於ケル騒擾ニ次テ七箇所ニ騒擾アリ就中二箇所ニ於テハ憲兵駐在
所及面事務所ヲ襲ヒ破壞暴行シ面長及憲兵ヲ傷ケ面書記三名ヲ拉去スル等ノ
事アリ
12 成鏡南道
一日元山ニ於ケル示威運動以來騒擾三十餘箇所ニ上リ或ハ憲兵警察官署ニ來
襲廳舎ヲ破壊スル等ノ暴行ヲナスモノ七箇所ニ上リ就中古土里ニ於テハ憲兵
駐在所內ニ闌入シ憲兵ヲ毆打負󠄁傷セシメ兵器、書類、器具等悉ク破壊焼却セ
リ
13 咸鏡北道
十日城川ニ於ケル學生ノ示威運動暴行ニ始マリ二十餘箇所ニ騒擾勃發シ暴民
ノ數多キハ五千ニ上リ數箇所ニ於テ面事務所ヲ襲ヒ警察官駐在所ヲ襲ヒ放火
スル等ノ暴行ヲナセリ
其三 四月中ニ於ケル厳援ノ槪況:
1 京畿道
京城府內ニ於テハ官憲及軍隊ノ至嚴ナル警戒ノ爲騒擾ヲ惹起スルニ至ラス表
面上ノ秩序ヲ維持シ得タリト雖モ郡部ニ於テハ水原安城附近ニ於テハ激烈ナ
ル騒擾ノ影響ヲ受ケ四月上旬ニ至リ猖獗ヲ極メ郡廳、面事務所、警察官署、憲
兵駐在所ノ襲擊民家及面事務所ノ破壊、放火、橋梁ノ破壊、焼棄等有ラユル暴
行ヲ敢テシタルノミナラス約二千名ノ暴民ハ水原郡雨汀面花樹警察官駐在所
ヲ襲ヒ之ヲ包圍暴行シタルヲ以テ駐在巡査ハ發砲應戰シタルモ衆寡敵セス彈
丸盡キ遂ニ慘殺セラレ其屍ハ凌辱セラレタリ狀況右ノ如ク殆ント内亂ノ如キ
狀態ニシテ爲ニ同地方内地人ノ如キハ危險ヲ冒シ婦女子ヲ一時他ニ避難セシ
ムル等人心恟々形勢混沌タリシカ當時來著セル發安城守備隊長ハ現況ニ鑑ミ
暴動ノ主謀者ヲ剿滅スルノ必要ヲ認メ四月十五日部下ヲ率ヒテ提岩里ニ到リ
主謀者ト認メタル耶蘇敎徒、天道徒等ヲ集メ二十餘名ヲ殺傷シ村落ノ大部ヲ焼
棄セリ
2 忠清北道
四月上旬ニ於テ京畿道騒擾ノ餘波ヲ受ケ始ント同郡ニ亙リテ騒擾頻發シ破壊
放火等ノ暴行亦紗カラサリシモ中旬ニ亙リテ槪シテ表面終熄スルニ至レ
リ
3 忠清南道
四月上旬ニ於ケル騒擾ハ京畿道郡部ニ次テ狂暴ヲ極メ各種官公署學校等ノ破
壊又ハ襲擊セラルルモノ十數箇所ニ及ヒ或ハ警察官ヲ傷ヶ面長フ脅迫シ又ハ
憲兵ヲ拉去スル等混亂甚シク爲ニ內地人ノ避難警察官及憲兵駐在所ヲ警備上
他ニ引キ揚クルノ已ムヲ得サルニ至リタルモノ三箇所ニ及ヒシカ十三日以後
ハ槪シテ靜穩ニ歸セリ
4 全羅北道
數箇所ニ於テ暴行シ又橋梁ニ放火シタルモノアル外槪シテ不穩ナリ
5 全羅南道
四月中ニ於ケル騒擾發生區域ハ一府八郡ニ亙リタルモ一箇所ニ於テ面事務所
ヲ襲ヒタル以外ハ単ニ示威運動ニ止マリ特記スヘキ騒擾ナシ
6 慶尚北道
三月中ニ於ケル激烈ナル暴動餘波ヲ受ケ四月中ニ於テハ前半月間ハ尚各地ニ
騒擾續發シタルモ後半箇月間ニ於テハ槪ネ平穩ニ歸セリ
7 慶尚南道
四月中南鮮ニ於テ最正頻發シタルハ本道ニシテ前半箇月ハ素ヨリ後半箇月ニ
至ルモ體發シ其手段ニ於テモ棍棒又ハ竹槍ヲ携ヘ或ハ銃器ヲ奪去スル等多ク
ハ悪性ヲ帶ヒ猖獗ヲ極メタルモノ多シ就中警察官駐在所憲兵駐在所其他ノ官
廳ヲ襲撃又ハ破壊セルモノ十箇所ニ垂ントシ又犯罪被告人ノ押送ノ途中ヲ扼
シテ妨害ヲ加フル等ノ爲鎭撫ニ際シテモ特別ノ手段ヲ採ルノ已ムヲ得サルニ
至レル箇所尠カラス
8 黄海道
四月中ニ於テハ前半箇月ハ殆ント毎日ノ如ク續發シ道內各郡ニ彌蔓シ其發生
件數モ全鮮ノ首位ヲ占メ就中七日、八日ノ兩日ニ於テハ騒擾箇所數十七箇所ニ
上レリ暴行ノ箇所亦頗ル多ク警察官又ハ憲兵駐在所ヲ襲ヒタル者ノミニテモ
二十箇所ノ多キヲ算シ暴動ノ地域件數ハ勿論其手段ニ於テモ京畿道郡部下竝
ヒ實ニ全道ニ冠タリ
9 平安南道
四月ニ入リテハ不穩ノ舉アリシハ僅ニ四件ニ過キスシテ槪シテ不穩ナリ
10 平安北道
四月中最モ多ク發生セシハ一日ニシテ其數十三件ニ上リタルモ其後ハ逐次減
少シ十日以後ハ全ク終熄セリ而シテ官廳ノ襲撃、破壊、放火等ノ暴行十數箇所
ニ及ヒ群衆ノ多キハ六、七千ヲ算スル所アリタリ
11 江原道
四月中全半箇月ヲ通シ一日トシテ騒擾ノ發生ヲ見サルコトナク官公署ノ襲擊
セラルルモノ九箇所ニ及ヒ其他民家ノ破壊、被檢舉者ノ奪還ヲ企ツル等暴行ノ
程度、事件數等敢テ猖獗ナリシ他道ニ穰ラサルモノアリタリ
12 咸鏡南道
四月八日成興郡德川ニ於テ暴民ノ憲兵駐在所ヲ襲ヒタル外槪シテ不意ニ經過
セリ
13 咸鏡北道」
四月中ニ於ケル本道ノ暴動地城ハ一府五郡ニ過キス穩城郡内ニ於テ一箇所暴
行シタル外ハ大ナル騒擾ヲ惹起セス槪シテ平穩ニ經過セリ
其四 五月以降ニ於ケル騒擾ノ槪況
五月以降ハ全道表面槪シテ静穩ニシテー、二箇所ヲ除キ騒擾ト認ムヘキモノヲ
見サルモ密ニ在外鮮人就中上海、露領方面ノ排日鮮人ト密ニ連絡シ海外ニ於テ
種々ノ排日的宣傳ヲ行フト共ニ鮮內ニ於テ虚構ノ風説ヲ流布シ學生其他ニ對
シ煽動脅迫ヲ試ミ陰ニ秩序ヲ破壊セントスルモノアリ
四、騒擾間ニ於ケル在外鮮人ノ動靜(ドウセイ)
四、騒擾間ニ於ケル在外鮮人ノ動靜
一、露領及間島方面同地方鮮人ハ元來排日鮮人ノ在住スルモノ多ク從テ鮮內
ノ騒擾ヲ傳ヘ在米及在上海鮮人ト互ニ氣脈ヲ通シ相呼應シテ鮮內ノ騒擾者
ヲ聲援スルノミナラス就中琿春、龍井村ニ於テハ騒擾ヲ惹起シタルモ支那官
憲ノ取締ニ依リ又露領內ニ在リテハ露國官憲ノ取締ニ依リ表面槪シテ静穩
ナルモ裏面ニ於テ尚獨立運動ニ關シ種々畫策スルモノ未タ其跡ヲ絶タス
一、上海方面 上海ニ在ル鮮人ハ常ニ在米鮮人ト氣脈ヲ通シ露領殊ニ浦潮方
面鮮人ト相待テ鮮内同志ト窃ニ連絡シ其不斷ノ煽動ハ常ニ鮮內ノ民心ノ安定
ヲ破リツツアリ而シテ該方面鮮人ハ民族自決ノ主義ヲ高唱シ朝鮮人現狀ヲ
訴ヘテ世界ノ同情ヲ得ントシ巴里講和會議ノ際ニ陳情請願ノ爲代表者ヲ派
遭シ或ハ日本ノ統治又ハ今囘ノ騒擾ニ關シ廣ク誇大虚構ノ事實ヲ宣傳シ他
國ノ同情ヲ喚起スルニ努メ或ハ煽動者ヲ鮮內ニ送リ或ハ山東問題ニ關聯ス
ル支那人ノ排日的行動ニ相通シテ之ヲ煽動スル等上海ハ實ニ在外排日鮮人
ノ獨立企畫ノ一根據地タルノ感アリテ三月以前ニ於ケル在上海鮮人ノ數僅
ニ五百内外ナリシモト今ヤ優ニ一千五百名ヲ算スルニ至リシカ講和會議カ全
ク朝鮮問題ニ觸ルルコトナクシテ絡結スルニ至リシモ近ク假政府ヲ組織シ
尚運動ヲ繼續シ目的ノ貫徹ヲ決議シ在米鮮人ト連絡シ國際聯盟會議ニ一縷
ノ望ヲ囑シ種々畫策シツツアリ
五、鎭壓ノ爲ノ處置(チンアツ ノ タメ ノ ショチ)
五、鎭壓ノ爲ノ處置
騒擾ノ遂日各道ニ蔓延スルヤ警務官憲ノ不足ハ警備上忽チ蹉跌ヲ來シタルノ
ミナラス交通ノ不便ハ更ニ鎭撫ノ困難ヲ増大スルニ至リタルヲ以テ鮮內ノ狀
況ニ鑑ミ折角集結ヲ了セル軍ヲ再ヒ分散配置ヲ取ラシメ以テ警務官憲ヲ援助
スルノ已ムナキニ至レリ此ニ於テ朝鮮總督ハ三月十二日軍司令官ニ對シ所要
ノ兵力ヲ使用シ鎭壓ヲ圖ルヘキコトヲ指示ス依テ軍司令官ハ京城其他各道ノ
要點ニ兵力ヲ分派シ警務機關ト協力シテ騒擾鎭撫ニ任セシメタリ而シテ是等
部隊ヨリ更ニ所要ニ應シテ必要ノ地ニ兵力ヲ分派スルノ必要ヲ生シ其數百數
十箇所ニ及ヒタリ然ルニ三月下旬ヨリ四月初旬ニ亙ル間ニ於テ騒擾ハ漸次暴
動ト化スルニ至ルヤ僅々一師團半ニ充タサル駐箚軍隊モ時將ニ新兵敎育期ニ
シテ其過半數使用ニ堪ヘサルノミナラス剩ヘ南部烏蘇里ニ一大隊餘ヲ派遣シ
アリ從テ之カ制壓ノ爲ニハ在鮮軍隊ノミニテハ不足ヲ感スルコト切ナルモノ
アリ依テ四月上旬内地ヨリ步兵六大隊及補助憲兵若干ヲ派遣シ朝鮮軍司令官
ノ隷下ニ入ラシメ騒擾ノ防壓ニ従事セシムルコトニ決セリ該部隊ハ四月上旬
内地港灣ヲ發シ四月十日乃至十三日ノ間ニ朝鮮ニ上陸シ四月下旬初ニ至リ全
ク所要ノ配置ニ就ケリ此ノ如クシテ在鮮部隊及內地ヨリノ増加派遣部隊ヲ以
テ分散配置セル箇所五百數十箇所ニ上リ警務機關ノ監視ト相持テ蠢動ノ餘地
ヲ與ヘサルニ至ルヤ四月二十三日以後ハ騒擾殆ント其跡ヲ絶ツニ至レリ
六、騒擾ニ關(カン)スル損害
六、騒擾ニ關スル損害
騒擾ノ性質ハ騒擾一般ノ經過ニ於テ述ヘタル如ク爲ニ之カ鎭壓ニハ兵器ヲ使
用スルノ已ムヲ得サリシモノ尠カラス三月一日ヨリ四月三十日ニ至ル間ノ騒
擾箇所及官公衛ノ被害別表ノ如シ
尚同期間ニ於ケル死傷左ノ如シ
一、官憲側死傷ハ憲兵、警察官、軍隊及其他ノ官公吏ヲ合セ總計百六十六名
ニシテ其ノ内譯次ノ如シ
死 六 死 二
憲兵{ 警察官{
傷 九一 傷 六一
死 ︙ 死 ︙
軍隊{ 其他官公吏{
傷 四 傷 二
二、暴民側ノ死傷 群衆中ニ死傷者ヲ出スヤ彼等ハ死者ハ直ニ之ヲ運搬シ
傷者ハ暴動參加ノ罪ヲ恐レテ極力秘匿セントスルヲ以テ實數ヲ知ルコト
困難ナルモ最近ニ於ケル調査ノ結果ニ依レハ約一千五百名ニ達セリ
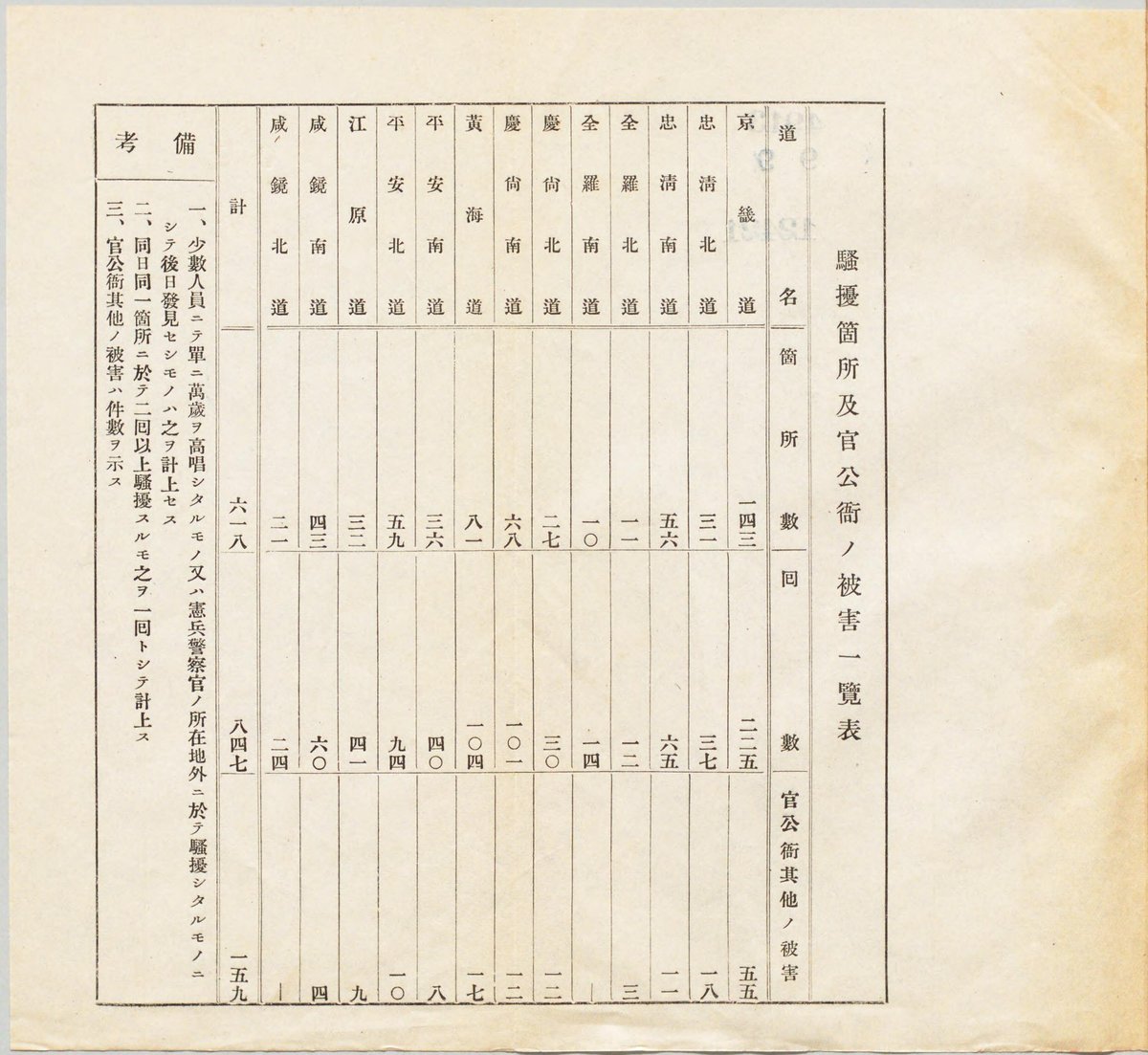
(被害別表)
(被害別表)
┌ ┐
│ 騷擾箇所及官公衙ノ被害一覽表 │
├ ┬ ┬ ┬ ┤
│道 名│箇 所 数 │囘 數│官公衙其他ノ被害│
│京 畿 道│ 一四三│ 二二五│ 五五│
│忠 清 北 道│ 三一│ 三七│ 一八│
│忠 清 南 道│ 五六│ 六五│ 一一│
│全 羅 北 道│ 一一│ 一二│ 三│
│全 羅 南 道│ 一〇│ 一四│ ︙│
│慶 尚 北 道│ 二七│ 三〇│ 一二│
│慶 尚 南 道│ 六八│ 一〇一│ 一二│
│黄 海 道│ 八一│ 一〇四│ 一七│
│平 安 南 道│ 三六│ 四〇│ 八│
│平 安 北 道│ 五九│ 九四│ 一〇│
│江 原 道│ 三二│ 四一│ 九│
│咸 鏡 南 道│ 四二│ 六〇│ 四│
│咸 鏡 北 道│ 二一│ 二四│ ︙│
├ ┼ ┼ ┼ ┤
│ 計 │ 六一八│ 八四七│ 一五九│
├ ┬ ┴ ┴ ┴ ┤
│備│一、少數人ニテ單ニ寓發ヲ高唱シタルモノ又ハ憲兵警察官ノ │
│ │ 所在地外ニ於テ騷擾シタルモノニシテ後日発見セイムモノハ │
│ │ コレヲ計上セス │
│考│二、同日同一箇所ニ於二囘以上騷擾スルモ之ヲ一囘トシテ計上ス│
│ │三、官公衙其他ノ被害ハ件數ヲ示ス │
└ ┴ ┘
「朝鮮騷擾經過槪要」画像
以下に一頁ずつ、傾き補正とトリミング補正した、原本画像を入れておく、不要と判断したもの一部は省略。
表紙

目次1/2

目次2/2

1: 一、騒擾ノ起因

2: 二、騒擾ノ企畫

3

4: 三、騒擾ノ經過

5: 其一 一般ノ經過

6

7

8

9

10

11

12

13

14

15

16: 四、騒擾間ニ於ケル在外鮮人ノ動靜

17

18: 五、鎭壓ノ爲ノ處置

19: 六、騒擾ニ關スル損害

20

被害別表

あとがき
記事作成の動機
今の韓国の方の主観では、とても信じられる文献ではないとして、否定する向きはあるのでしょうが、公式文書とは、それを基準に内部の意思決定を行なう為に作成されるものです。従って嘘偽りの記録や見解を入れることは通常期待出来ることではありません。そのことを踏まえて、是非、当時の半島の国家の認識を主観脳ではなく「ヒトの大脳新皮質」内の脳内活動のみで客観視頂き、一読頂ければ有難く存じます。
今後の記事加筆の計画
目標としては、「韓国語と英語の機械翻訳」迄を考えていますが、何分古い文体の為、このままでは、当方が当てにする機械翻訳では概要把握が限界ですし、誤訳にもつながります。そこで、先ずはOCR文字化を今回行ない、それらの作業を手掛ける中で、OCRの誤読や当方のミスタイプを低減しつつ、そのデータはそのまま維持しつつ、日本の現代人が辞書を引かずに読める程度のルビ打ちを第一の一里塚として作業を進めます。
この作業は手作業ならば、限り無く修正箇所のバージョン管理の混乱が発生しますので、ルビ打ちする文字列とルビ付き文字列を対としたデータを基に自動処理を進めます。何分一人によるボランティア作業であり、一つの読みのルビ追加が、全体に及ぶ様にしなければ、その度に手作業での置換をしなくてはなりません。それを避ける為です。
「3.1独立運動」認識関係の筆者の課題認識
3.1独立運動は、韓国人には高揚感を抱くことの様だ。最初に自らの民族としての自尊心を最大の価値観として、全てを主観脳により、心地良いものに描くのだから、果てしなく史実とはかけ離れてしまう。
そもそも、3.1独立運動の切欠は、民族運動でも何でも無い。何しろ、「民族独立」の思想自体が、欧米国際政治上のプロパガンダに過ぎなかったからだ。
それに、かこつけて動いた団体が居た。そして、それを活用しようとした輩が煽った。それが現実だった。そして、プロパガンダを流した側は、それを視て、ほくそ笑んでいたのだ。
その意味で、韓国人は今も、プロパガンダの格好のターゲットなのだと想う。それを妨害する方法は限られている。理解出来る韓国人限定ではあるが、可能な限り当時の文献を、素で読んで貰うことだ。
その趣旨で、韓国人の言う所謂「3.1独立」を大正8年9月、陸軍省印刷の「朝鮮騷擾經過槪要」をOCRにかけて、誤変換を一通り修正して試た。また、完全とは言えないと想うが、ネット上の原本イメージを読むよりは、遥かに視認性も高く、且つ、翻訳への道をつなぐものになったものと想う。
TODO
誤謬訂正
初版には用字の問題も含めたら経験上最大で行数と同じくらいの誤謬箇所があると想定しています。
基本的には読めますが、誤った文章に成る場合もあり、今後の作業の中で、原本とするテキストデータを洗練させて行く
しかし、最終的には一行ずつ、一字ずつのチェック作業は必要になる。その為の縦書きPDFファイルも作成している。
まだ、初版段階は、ケアレスミスもあり、データ原本の精度は高くないので、そのファイル掲載は、初回は見送ります。
成果ファイルの公開
もう少し安定したら訂正差分と共に公開予定。
ルビ打ち
戦前と戦後では、GHQによる文化介入で、当用漢字導入、文体の口語化他、日常の書き言葉が大きく変化。その結果、現代の日本人には、とても読み辛いものとなっています。幸い?、このNOTEでは、一定の書式で記事を書くことでルビ表示させることが可能です。それを前提に、現代人に読み辛い旧字の漢字読みや漢字語、そして送り仮名の現代語化したものを、データ化し、プログラムで置換させ、掲載したいと考えています。次回の改訂は、この対応後となります。
現代語訳
初めに必要なことは、新字体への置換ですね。これは簡単ですね。今は、逆に国際標準としての旧字(繁体字)に拘っています。海外の人に日本の新字を覚えろと迄は言えませんし、戦前の文献も日本の蓄積したものです。日本人なら、それに触れる機会を増やし、気軽に読める様に成ることも大切だと思うからです。
日本人に対しては殆ど不要ですが、文章の分割や句読点の付加等をルビ打ち完了後辺りから手掛けます。これは、次の諸国語別の機械翻訳の起点と成ります。
機械翻訳
現在機械翻訳は韓国語はPapago、英語はDeepLを中心に使い、Googleを補助としています。言語と機械翻訳の特性に合せた日本語変更も必要になります。直接翻訳する能力は持ちませんので、そう言う取組みになります。この完成のゴールは遥か先で、自分では実現不能な所にはありますね。結果として、索引的な訳文提供に留まると思います。それ以降は、この記事を踏み台にしてくれる方への完全なバトンタッチですね。
自動化
手作業なら誰でもできることですが、時間的に限界もあります。その為に、記事作成には、ある程度の自動化が不可欠になります。そのツール紹介や開発も合せて行ないます。随時別記事として扱って行くつもりです。
画像の差替え
後で気付いたことながら、国立国会図書館デジタル側にもこの文献の映像が掲載されていた。同一文献たが、画質が良い。初版では、文字が潰れて判別がギリギリの推定だった最後の「被害別表」のみを併置した。処理時間はそこそこかかるので現状のまま当分捨て置くが、折をみて、差し替えたいとは思う。今からもう一度OCRからやり直す気には成れないし、それをする成果はもう多くはないだろう。難解な漢字は推定で意を確かめ確定したので恐らく略誤りは無いと考える。
履歴
2022-03-03 初版公開
OCR初版公開
頁別画像の公開
この記事が気に入ったらサポートをしてみませんか?