
YOLOv9 のお勉強~何がすごいのか?なぜすごいのか?~

2024 年 2 月に,物体検出モデル YOLO のバージョン 9 が発表されました。"Learning What You Want to Learn" という論文のサブタイトルに、開発者の意気込みがうかがえます。そんな論文を読んで、YOLOv9 が達成したブレイクスルーやその要因について考えてみます。
論文はこちら
実装についてはこちらの記事で書いています。興味がある方は合わせてご覧ください。
0. そもそも物体検出とは?
物体検出とは、簡単に言うと画像中の「どこに・何が」あるかを同時に予測する技術です。
画像 AI というと、例えば動物の画像を見せて犬か猫かを予測する「画像分類」が有名ですが、実際に私たちが見ている世界では、様々な領域に様々なモノが存在します。機械が私たちと同じように認識するためには、モノの種類だけでなく位置も判断する必要があります。これを実現するのが物体検出という技術です。

1. 何がすごいのか
YOLOv9 の素晴らしい点は、リアルタイムの物体検出がまだまだ進展しうることを示した点にあると思います。精度とパラメータ数のグラフを見てみます。

(論文の Table 1 をもとに作成)
グラフの縦軸はモデルの検出精度を表しており、高いほどいいです。
横軸はモデルのパラメータ数(サイズ)を表しています。一般に、パラメータ数は多いほど精度が上がりますが、処理に要する時間が増える・過学習に陥りやすいといった負の側面もあります。なので、パラメータ数が異なるいくつかのモデルで評価を行い、「このパラメータ数ではこの精度まで出せた」という曲線で良し悪しを判断します。
この曲線がグラフの左上に向かうほど、少ないパラメータ数でも高い精度を出せる良いモデルということになります。
このままだと見にくいので、数字が振られているバージョンに絞って、バージョンが上がったときにどの程度精度が上がったか比べてみます。

(論文の Table 1 をもとに作成)
これまでも、確かにバージョンが上がることで進歩はしていました。しかし、その伸びはわずかに見えます。これは最前線のグループが競い合っているので当然といえます。陸上の世界記録を0.01秒更新するだけでも偉業になるイメージです。
特に二つ前の YOLOv7 と一つ前の YOLOv8 はほとんど同じカーブに見えます。自分は正直なところ、物体検出は技術としては飽和しており、ここから大きく進展することはないのかなと思っていました。
では、YOLOv9 はどれほど進化したのでしょうか?
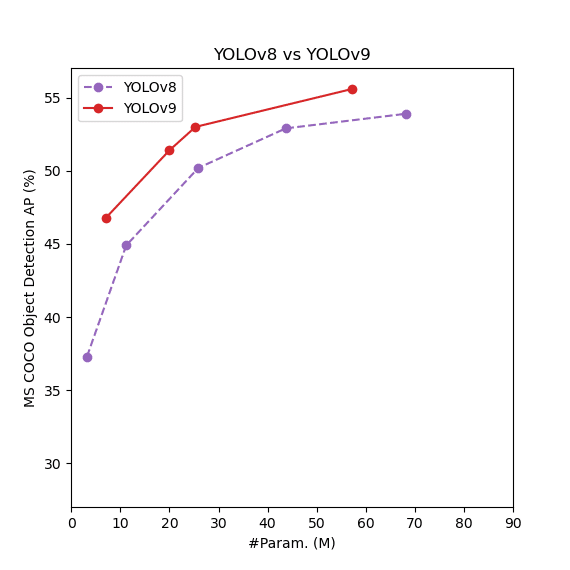
どうでしょうか? YOLO v6 から v8 までの曲線は、一つ前のバージョンの曲線と接近する箇所があったのに対し、v9 の曲線は全てのパラメータの範囲で前のバージョンよりもはっきり高い精度を示しています。陸上で例えると、ボルト選手が 100m、150m、200m と世界記録を大幅に塗り替えたようなイメージです。
実際 YOLOv9 は、MS COCO という物体検出の精度評価でおなじみのデータセットを用いた検出テストにおいて、過去のどの物体検出モデルよりも最も高いパフォーマンスを示したと報告しています(state of the art, 通称 SOTA と呼ばれます)。
こんなぶっちぎりの更新をできたのは、何か秘訣があるはずです。
2. なぜすごいのか
これまでの問題点
深層学習モデルは、名前の通りいくつもの層 (レイヤー) で構成されています。入力された画像が深い層に伝達されるほど、元の情報が失われてしまうという問題がありました。

この問題に対処するために、"Programmable Gradient Information" (PGI) というコンセプトと、"Generalized ELAN" (GELAN) というアーキテクチャの 2 つを提案しました。
Programmable Gradient Information (PGI)

Programmable Gradient Information (PGI) とは、深層学習モデルが重みを更新する際の勾配情報をコントロールする技術です。Main branch のほかに、auxiliary reversible branch、Multi-level auxiliary information から構成されます。PGI によって深い層にも重要な情報を伝達でき、最終的な予測の精度を向上させることが可能になります。
Generalized ELAN (GELAN)
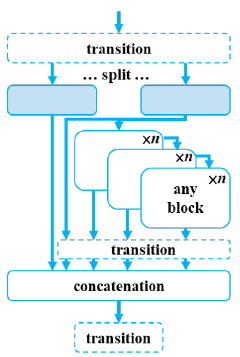
GELAN (Generalized Efficient Layer Aggregation Network) は、この論文で提案された新しいアーキテクチャです。
各層からの情報を効率的に集約し、活用することで、モデルの性能を向上させると同時に、計算コストを削減します。その結果、リソースが限られている環境でも高い性能を発揮することが可能となります。

まとめ
この記事では、2024 年 2 月に発表されたばかりの YOLOv9 の論文についてレビューを行いました。YOLOv9 はこれまでのモデルを大きく上回る検出精度・速度を達成しましたが、これは PGI・GELAN という 2 つの技術に支えられていることが分かりました。
(繰り返しになりますが) 自分で動かしてみたくなった方は以下の記事もご覧ください。