
「5人でユーザテストすればユーザビリティ上の問題のうち85%が見つかる」の元ネタ論文を解説する

Webサービスやアプリなど開発や運用に関わっている方であれば、こんなことを耳にしたことがあるのでは無いでしょうか?
5人でテストを行えば、ユーザビリティ上の問題のうち85%を発見できる
これらは業界的にはある意味で常識ですが、色々話を聞いてみると、この常識の「出処」あるいは「根拠」ってあんまり知られていないようなのです。
もちろん、ちょっと知識のある人であれば、ユーザビリティ業界の第一人者であるヤコブ・ニールセン博士が提唱したというところまでは知識として知っているでしょう。しかしながら、その元ネタとなった論文を実際に読んだ人、あるいは85%という数字の根拠やその条件について理解されている方はどの程度居るのでしょうか。
ということで本記事では「ユーザテストは5人で85%」の元ネタである下記の論文について、解説、と言うとちょっと大げさかもですが、概要を紹介してみたいと思います。願わくば、この記事が、みなさんが今取り組んで居るユーザビリティ評価手法やプロセス改善について考える一助になれば幸いです。
Jakob Nielsen and Thomas K. Landauer. 1993. A mathematical model of the finding of usability problems. In Proceedings of the INTERACT '93 and CHI '93 Conference on Human Factors in Computing Systems (CHI '93). ACM, New York, NY, USA, 206-213.
なお、参考までに私自身のユーザビリティ評価に関する知識について書いておくと、実際にユーザビリティ評価を実施したこともありますし、ユーザビリティ評価に関するジャーナル論文を複数本持っています。ユーザビリティに関する講演や研修講師経験も何度かあるので「ワタシユーザビリティチョットデキル」と言っても、あまり怒られないのではないかな?とちょっと思っています。
また、本記事で使用されている図表はすべて、前述した論文からの引用となることをここに書き記して置きます。
論文の背景
この論文が書かれた当時(1993年ですので、今から約25年前)にはすでにユーザビリティ評価手法に関する研究が行われていました。
それらの研究を踏まえて、実際の開発現場で開発者が知りたいであろう「いつ、どのように、何人で評価すると最もコスパが良いのか?」に対するひとつの回答を示したのが本論文です。
本論文では、過去に行われたユーザビリティ評価に関するデータを集めてきて、それらをもとに数学的なモデルを構築し、それに対して考察を加える内容となっています。
そもそもユーザビリティ評価とは
ユーザビリティ評価の目的はプロダクトを改善するために、できる限り多くのユーザビリティ上の問題点を見つけることであり、その手法には大きくわけてふたつ、ユーザテストとヒューリスティックテストがあります。
ユーザテストは実際のユーザにシステムを使ってもらい、問題を抽出する方法で、ヒューリスティックテストは専門家が彼らの知識や経験からユーザビリティ上の問題点を抽出するものです。それぞれ方法は大きく異なり、それぞれにメリット・デメリットがあります。
ユーザテストは実際のユーザから知見を得られるのが大きなメリットですし、後者は準備が簡単で比較的低コストで実施できる事がメリットです。(なお、本論文におけるヒューリスティック評価とは、一人の人間が行うのではなく、複数人が独立して評価を行い問題点リストを作り、集約する事を前提としています。)
いずれの手法を用いる場合であっても「ユーザビリティ評価によってプロダクトを改善できる」は多くの場合で事実ですが、開発現場においては「どれだけの被験者によってユーザビリティ評価を行うべきか」について判断する材料が求められています。
本来必要な人数よりも少ない人数でテストを行うことによってユーザビリティ上の問題をほとんど抽出できていなかったり、あるいは必要よりも多くの人数でテストを行う事によってコストを掛けたわりに得られる知見が少ない…なんてことにもなりかねません。
研究に使用したデータセット
前述した「どれだけの被験者によってユーザビリティ評価を行うべきか」を推定するために、過去の研究データから数学的なモデルを生成し、その妥当性を検証します。
この研究のもととなったデータセットは11種類。下記のように5種類のユーザテストと、6種類のヒューリスティックテストの結果を使っています。

リストを簡単に抜き出すとこんな感じ。
ユーザテスト
- オフィスシステム、パソコン、GUI
- カレンダーアプリ、パソコン、GUI
- ワープロソフト、パソコン、GUI
- アウトラインプロセッサ、パソコン、GUI
- 文献検索アプリ、メインフレーム、CUI
ヒューリスティックテスト
- 飛行機の離陸情報サービス、ビデオテックス、CUI
- 電話帳アプリ、メインフレーム、CUI
- 銀行(送金サービス)、音声UI
- 銀行(残高照会および両替)、音声UI
- 乗換案内サービス、音声UI
- 社内システム、ワークステーション、GUI
ご覧頂ければわかりますが、ユーザテストとヒューリスティックテストが混在しています。また、1993年という時代を考えると当たり前なのですが、音声UIやCUIもデータセットの中に含まれている一方で、WebサイトやWebアプリケーション、あるいはスマートフォンアプリは登場していません。
評価者数と問題発見率の関係
ユーザビリティ上の問題点を発見する行為というのは、ソフトウェアに含まれる「バグ」を発見する行為と似ています。どういうことかと言うと、複数の試験者がいた時に、彼らは独立にバグ探しを行いますので、試験者Aがとあるバグを発見したかどうかは、試験者Bが同じバグを発見できるかどうかに影響しないわけです。
こういった状況下において、試験者がどれだけのバグを発見できるかをポアソン分布で説明できることが先行研究からわかっています。同様にポアソン分布でユーザビリティ上の問題点の個数を推定することができるのではないかというところがスターティングポイントです。
なお、ポアソン分布とは、サンプル数を変化させたときに、特定の事象がどの程度発生するかを見積もるためのモデルです。ということで、さっそくですが各データセットに対してポアソンでフィッティングを行ったグラフが下記になります。横軸が被験者数。縦軸が問題発見率ですね。
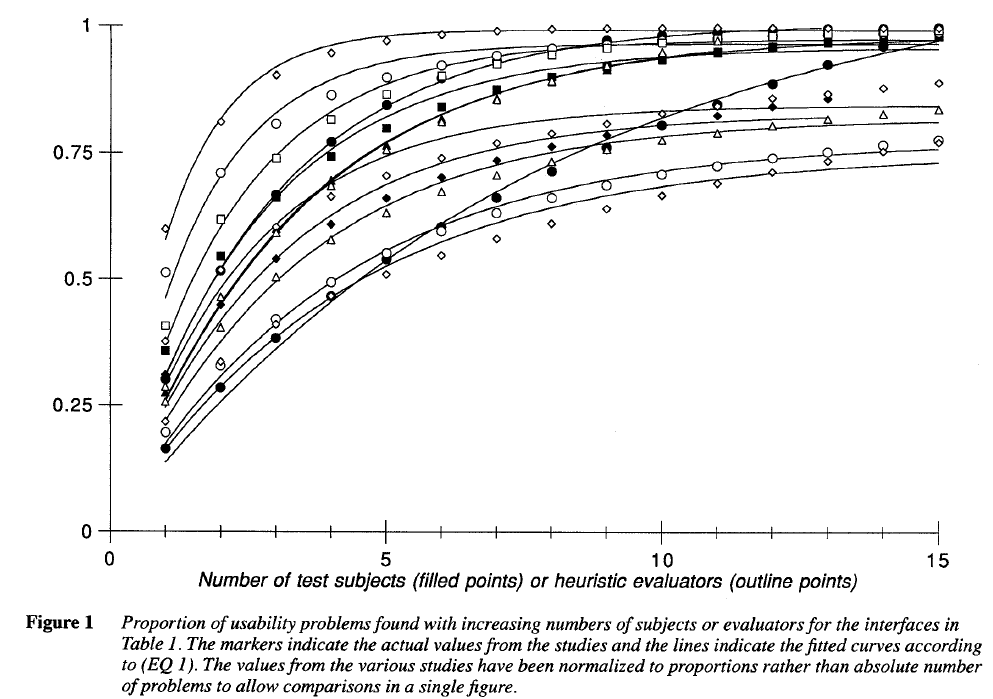
個々のユーザビリティ問題の発見がポアソンに従っていることは上記図からわかりますが、対象となるシステムによって、ポアソン分布のパラメータλ(ラムダ)は大きく異なっています。ここでパラメータλは下記のような式で表されます。
λ = (一人の評価者が見つけるユーザビリティ上の問題の個数) / (システムに存在する問題の総数)
λが異なるとユーザビリティ評価者を増やしたときの問題発見率がゆるやかになったり急激になったりします。このブレ幅の要因はケース・バイ・ケースですが、例えば下記のようなモノがあると述べられています。
- アプリケーションの種類、規模、タスクの大きさ。
- ヒューリスティックの場合は評価者の熟練度。
- システムのフェーズ。何回かのブラッシュアップを重ねられたシステムのほうが洗練されているため、開発初期段階のシステムのほうが問題点が見つかりやすい。
- ペーパープロトタイプよりも、実際に動くもののほうが多くの問題を見つける事ができる。
- ユーザテストをする際に、思考発話法(被験者に感じたこと、思ったことを口に出しながら操作してもらう評価手法)を行った場合と行わなわなかった場合では行った場合の方が多くの問題を見つける事ができる。
- ヒューリスティック評価者およびユーザーテストを実行している実験者のスキル。例えば、ユーザビリティ専門知識を持つ評価者は、そのような専門知識を持たない評価者よりもより多くの問題を見つけられた。ユーザビリティと評価されるアプリケーションに関する両方の知識の種類の両方を持つ評価者はさらに多くの問題を見つけた。
- 異なるケースにおいて正の相関がある。つまり、問題に気が付きやすい人は、他のシステムを評価する場合であっても問題に気が付きやすい。
- ユーザテストの被験者が実際のユーザーにどの程度近いのか。
システムに潜むユーザビリティ上の問題の数を見積もる
このモデルの使いみちの1つは、いつまでユーザビリティを評価するかを見極めるということです。つまり、開発中のシステムの中に何個ぐらいの問題が残っており、評価者を1名追加するとどの程度新しい問題を見つけられるかという事です。
例えば、評価者が1名であったときに、アプリケーションの中に潜むユーザビリティ上の問題点の約30個、評価者が2名であった時に二人で合計50個の問題を見つけたとします。そうすると、ポアソン分布のパラメータλは下記のようになります。
λ = 2 - (50/30) = 0.33
そしてこの場合に、アプリケーションの中に潜む問題の総数Nは下記のような式で推定することができます。
N = 30 / 0.33 = 90
しかしながら、これはあくまでも推定であって、それなりの分散があると考えるべきです。そして推定精度は評価者の数が増えるにつれて向上するはずです。例えば、評価者の数と推定精度の関係を示した表は下記の通りになります。これによると評価者の数が2人または3人の場合は推定精度にかなり大きなブレがありますが5人以上の評価者から得られたデータであれば、それなりに信頼できることがわかります。

で、結局何人で評価するののコスパ良いの?
ユーザビリティ評価の終了タイミングの決定は、個々の開発プロジェクトの特性、具体的にはユーザビリティ評価にかかるコスト、およびユーザビリティ改善から得られる利益によって判断されるべきですが、実際には画面数、ユーザー数、使用期間、頻度、およびミッションクリティカルであるかどうかなど、さまざまな要素が影響します。
まず、ユーザビリティ評価にはどの程度のコストがかかるのでしょうか。本論文では、いくつかの先行研究から費用を仮定して見積もりを行っています。
例えばヒューリスティック評価は固定費が4000ドル+評価者1人あたり600ドル。仮に5人でテストすると、7000ドルですね。一方、ユーザテストの場合は3000ドル+被験者1人あたり1,000ドルと見積もって居ます。こちらは5人で評価しようと思った場合、8000ドルとなります。
ただしこれは1993年当時、あるいはその数年前の相場です。なお、消費者物価指数的には1993年から2019年の間に、アメリカの物価は約1.8倍(つまり当時の100ドルは、現在180ドルの価値)になっています。
そして、ユーザビリティ評価から得られる利益はどの程度あるのでしょうか。本論文ではやはりいくつかの先行研究から、ユーザビリティの問題1つ発見することで得られる利益を15,000ドルと設定しています。
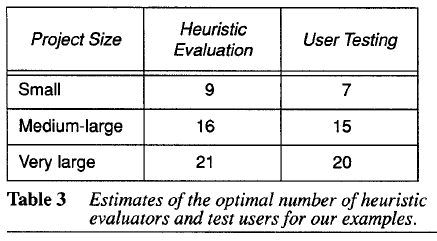
このような仮定を置いたとき、この論文で使用しているデータセットの平均であるλ=0.31(一人の評価者が発見できる問題の割合)、N=41(一つのシステムに含まれるユーザビリティ上の問題点の数)を前提にヒューリスティック評価者および、ユーザテスト被験者の限界値を計算すると2の知見が得られます。
ひとつは下記の表に示すように、これ以上被験者、あるいは評価者を増やしてもコスト的にメリットが無いよ、という人数。例えば、中くらいのサービスに対して評価を行う時に、評価者を15人以上にしてもコスト的にメリットはないよ。ということができるわけですね。
そしてもう一つは、最もコスパの良い、つまり評価にかかる費用と、そこから得られる利益が良い人数は何人かということ。コストと利益のグラフが下記になります。これは中規模プロジェクトの費用対効果モデルですが、ユーザテストの場合は3.2人、ヒューリスティック評価の場合は4.4人です。

おわりに:補足と個人的な所感
ニールセン博士はこの論文を執筆する以前の1989年頃からdiscount usability engineeringと呼ばれる、5人でのユーザビリティテストを提唱していますので、この論文にはdiscount usability engineeringの妥当性を補足する意図があるとも捉える事ができます。
Nielsen, J. (1989). Usability engineering at a discount. In Salvendy, G., and Smith, M.J. (Eds.), Designing and Using Human–Computer Interfaces and Knowledge Based Systems, Elsevier Science Publishers, Amsterdam. 394-401.
Nielsen, J. (1990). Big paybacks from ‘discount’ usability engineering. IEEE Software 7, 3 (May), 107–108.
そんなわけで、この論文では「ユーザテストは5人で実施するべきだ」とは言ってないのですね。「ユーザテストは5人で実施するべきだ」の元ネタは前述したDiscount Usability Engineering論文であり、その手法の妥当性として「5人でテストすれば85%」を示しているのが本論文になります。
なお、1993年と2019年で同じ条件が当てはまるかと言う指摘もあるかと思います。例えば当時に比べて、WebやスマホではUIのガイドラインといいますか、フレームワークが進化してきました。つまり、特定のアプリケーションの操作に慣れていれば、他のアプリケーションを操作する際に戸惑うことも少ないはずですし、開発者もユーザビリティに関する知識が浸透してきているので、あからさまなユーザビリティ上の問題点を作り込むケースもあまりないでしょう。
一方で、私自身は3Dアプリケーション(Second Lifeやマインクラフトのようなものを想像してください)やVRアプリケーションにおけるUIデザインや評価に携わったこともありますが、ユーザビリティに関する原則といいますかユーザビリティに関する知見は、媒体が変わっても使い回せることが多いと感じています。
それよりも、時代背景を考慮すべき要注意ポイントとしてはコストと利益のバランスでしょう。本論文ではコストと利益の関係から適切なユーザビリティ評価人数を導いているものの、2019年の日本においてその仮置きの数字に妥当性にはいささかの疑問があり、2019年現在、この数字を鵜呑みにするのは危険があるのではないかと個人的に思います。
とはいえ、5人ぐらいでテストをすれば一定の方向性が見いだせるのは私の経験則的にも事実であり、まずは5人、というのはある意味で妥当であるとも感じて居ます。いずれにせよ、ユーザビリティ評価を行う際には、評価対象となるプロダクトの特性、開発チームとして使用可能なリソース(予算や時間など)を把握した上で適切なテストを設計する必要があるでしょう。
最後に、ちょっとだけ宣伝
弊社ANKR DESIGNでは、お客様のプロジェクトの目的やフェーズに応じて最適なユーザビリティ評価やその他デザインリサーチプログラムをご提案・実施させていただいております。具体的なプロジェクトについてのご相談はもちろん、「こういったことって可能だろうか?」といった段階から、お気軽に下記のTwitterアカウントへのDM、または弊社Webサイトからお気軽にご連絡頂けますと幸いです。