
Amazon Bedrock + Kendraで社内ドキュメントを参照(RAG)するLLMを実装する

株式会社Yoiiで自然言語処理に関する業務のインターンを行なっている浅井です。
先日行われたAmazon Bedrock Prototyping Campという1dayワークショップにて、Amazon Bedrock + Kendra を用いて社内ドキュメント(ここではnotion内のドキュメント)をLLMに参照する機能のプロトタイプの実装を行いました。
以前より、LLM利用プロジェクトの一環として、LLM(gpt3.5-turbo) + RAG(Pinecone)による社内ドキュメント参照チャットbotの作成を行っていました。
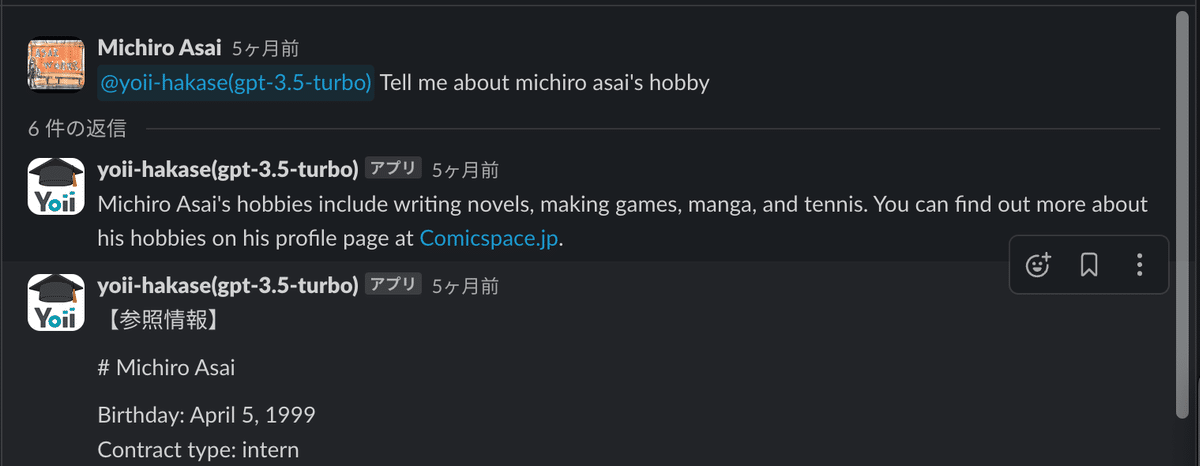
このチャットbotの精度向上、およびAWSサービス内での完結を目指しました。
使用するLLMをgpt-3.5-turbo → Bedrock内のもの(Claude)に、RAGをPinecone → Kendraに変更した場合に精度の向上が見込めないかを検討するため、ワークショップ内でのプロトタイプ実装を行いました。
※IAMの付与についての説明は省略していますが、適宜使うサービスの権限を付与してください。
①Amazon Bedrock側の準備
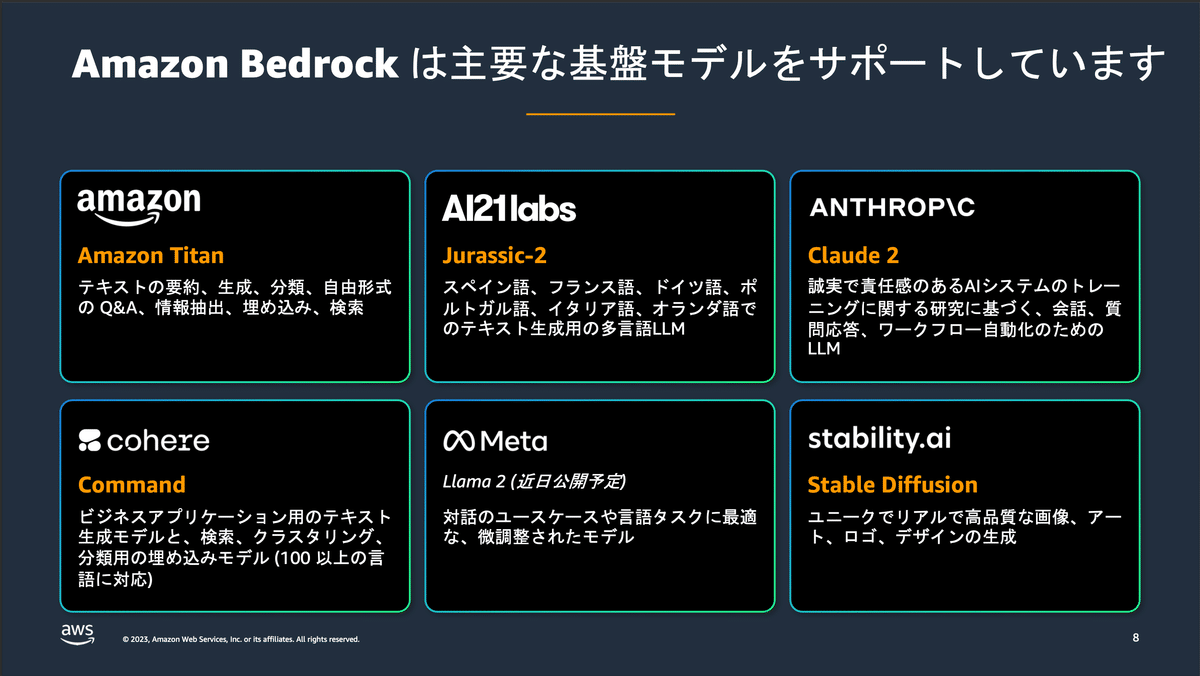
Amazon Bedrock は、API を通じて多種多様な基盤モデルを利用できる、AWSによるサーバーレスのサービスです。
2023年の9月29日ごろに公開されたばかりですが、11月現在においても、このように多様な基盤モデルが使用できるようになっています。
今回はLLMを試していますが、画像生成のモデル等も利用可能です。
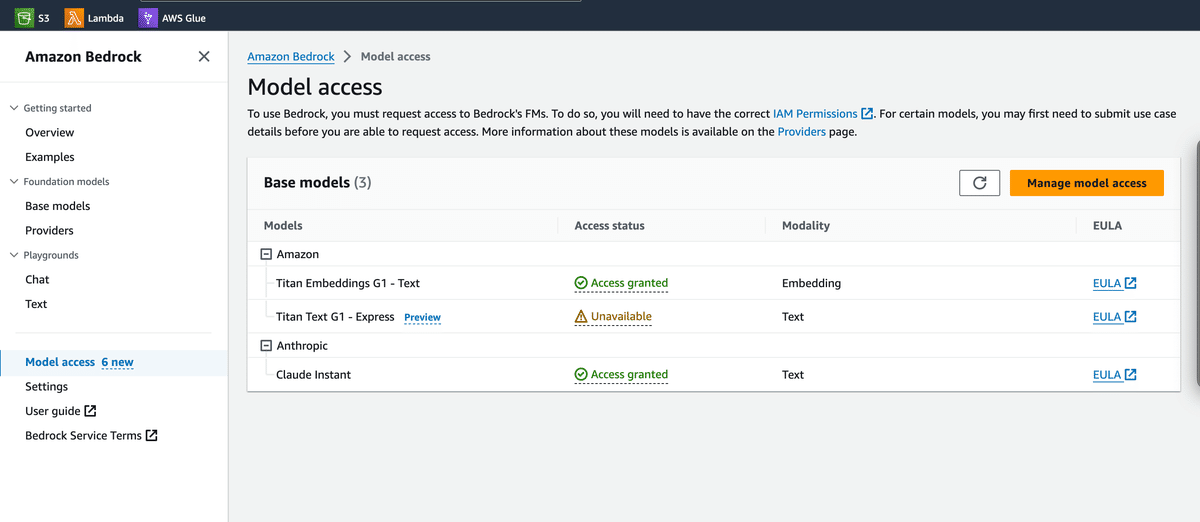
各モデルの使用を開始する場合、Model accessのページから、使用したいモデルを選んでアクセスの利用申請を行う必要があります。(一つ一つのモデルについて、それぞれの許可がなければ使用できません)
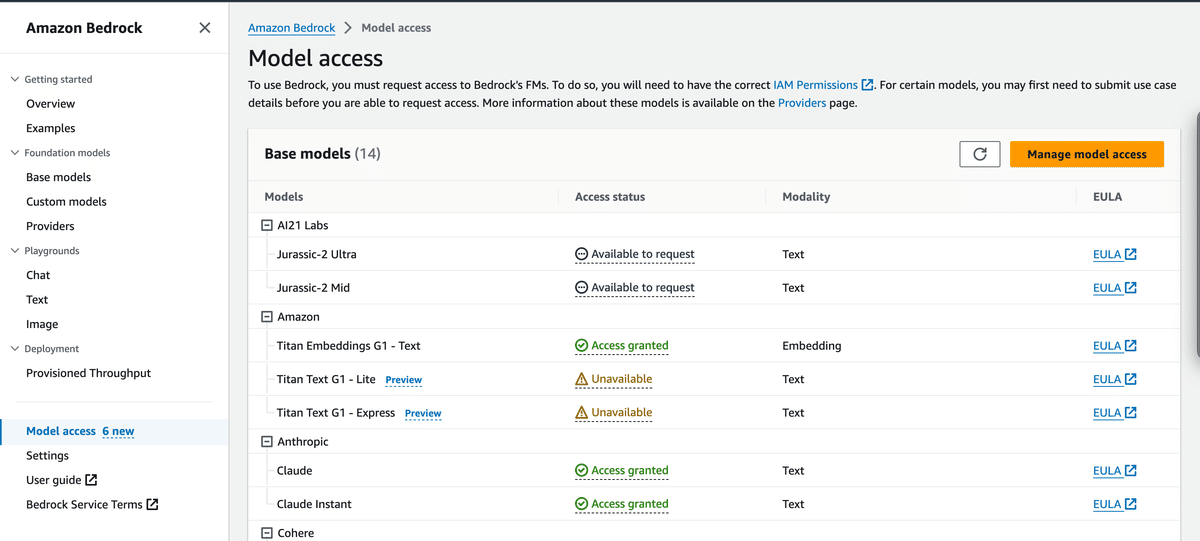
東京リージョンですと、現在はTitan Text G1 ExpressやClaude Instantなどが使用できます。Claude2が使いたい場合などは、バージニア北部などの別のリージョンから申請を行う必要があるため、注意が必要です。
使用許可が降りたモデルを手っ取り早く試したい際には、Playgroundの機能を使用できます。モデルを選択した上で、GUI上でチャットを行ったり、画像生成を行ったりすることができます。
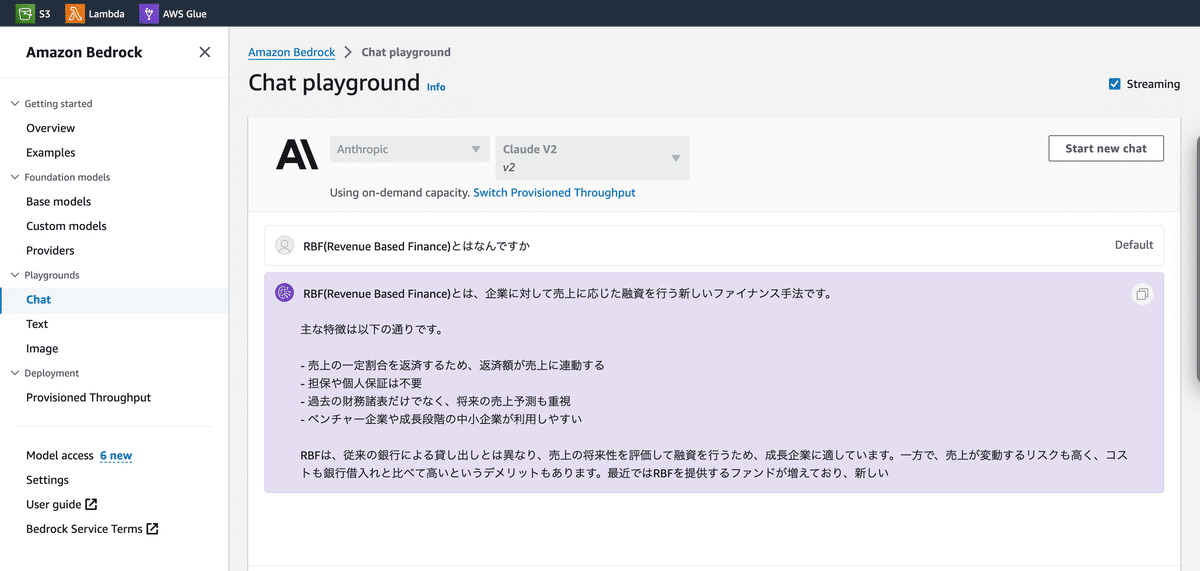
②Kendra側の準備
Amazon Kendraは機械学習を用いて最適されたエンタープライズ検索システム(個々人の持つ情報をもとに行う検索システム)を可能にした検索エンジンです。
パラメータの設定等は必要がなく、データソースもs3等と直接接続が行えるため、最短一時間程度で簡単に高性能なRAGを体験することができます。
今回はnotionの文書を大量にエクスポートし、それをアップロードしたs3バケットをKendraに接続させます。
インデックスの作成
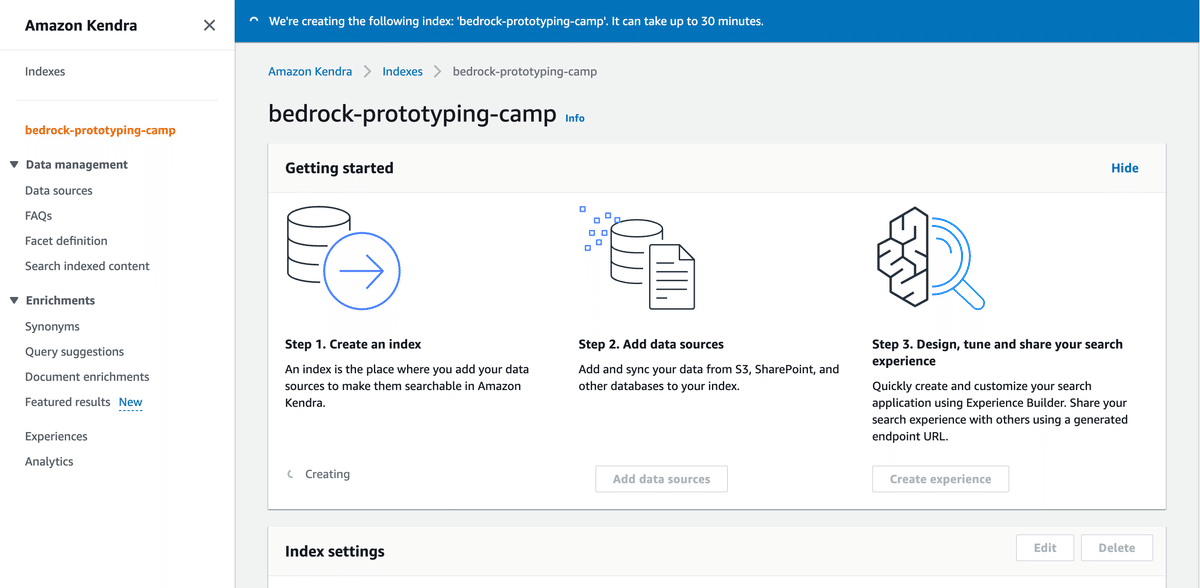
Amazon KendraのIndexesを開き、Create Indexよりインデックスを作成します。
データセットの準備
Yoiiでは社内規則やミーティングログなどの文書の多くをnotionに保管していました。そのため、今回はnotionのいくつかのデータをhtmlの形式でエクスポートして試しました。
(htmlにしたことに深い理由はありません。Kendraはプレーンテキストだけでなく、jsonやcsvなどの構造化データ等も高い精度で読み取ってくれるようなので、お手持ちのお好きなデータで試してみると良いと思います。)
s3を開き、バケットを作成し、中に検索したい文書データをアップロードします。
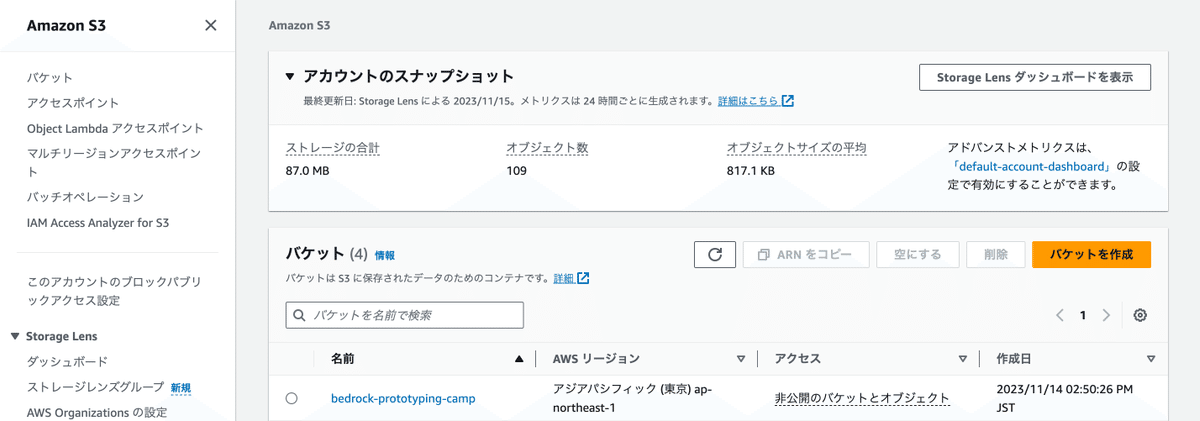
アップロードが完了したら、該当するs3バケットをデータソースとして追加します。
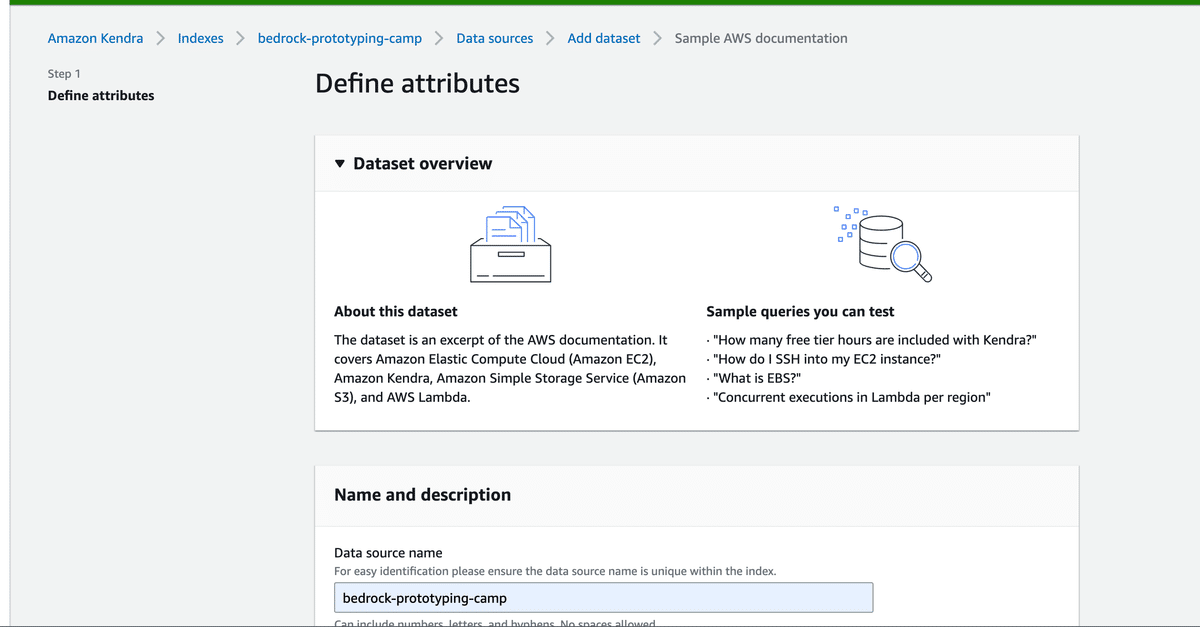
その後、データのSyncが行われます。crawlingとindexingが完了するまで待ちます。
Experienceの作成・GUI上での実行
Syncingが終了し、データソースの作成(接続)が完了したら、最後にそのデータソースを参照するexperienceを作成します。
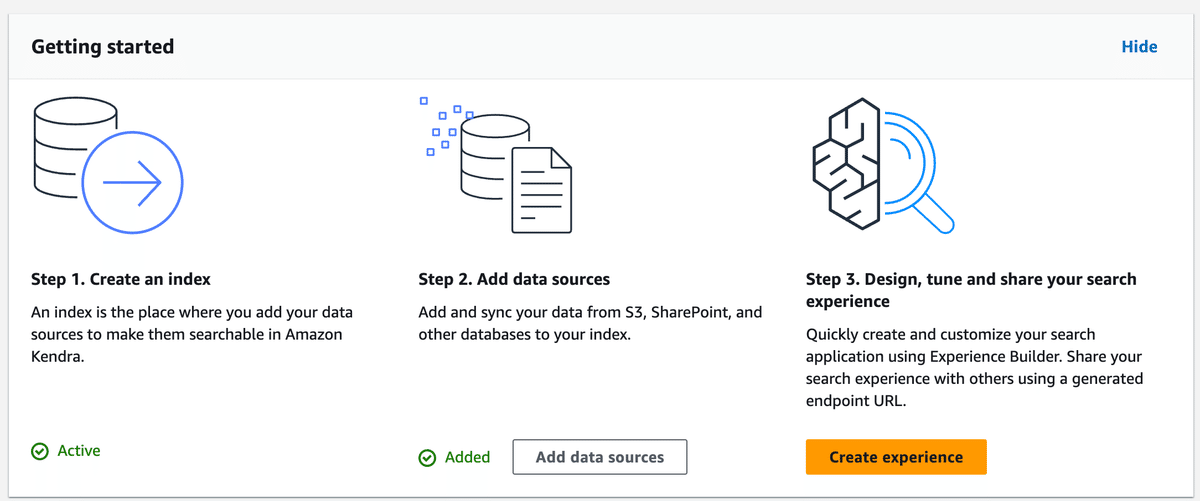
experienceの作成が完了すると、GUI上からKendra searchが行えますので、試してみます。
左メニューの「Experiences」をクリックし、「Open In Experience Builder」をクリックします。
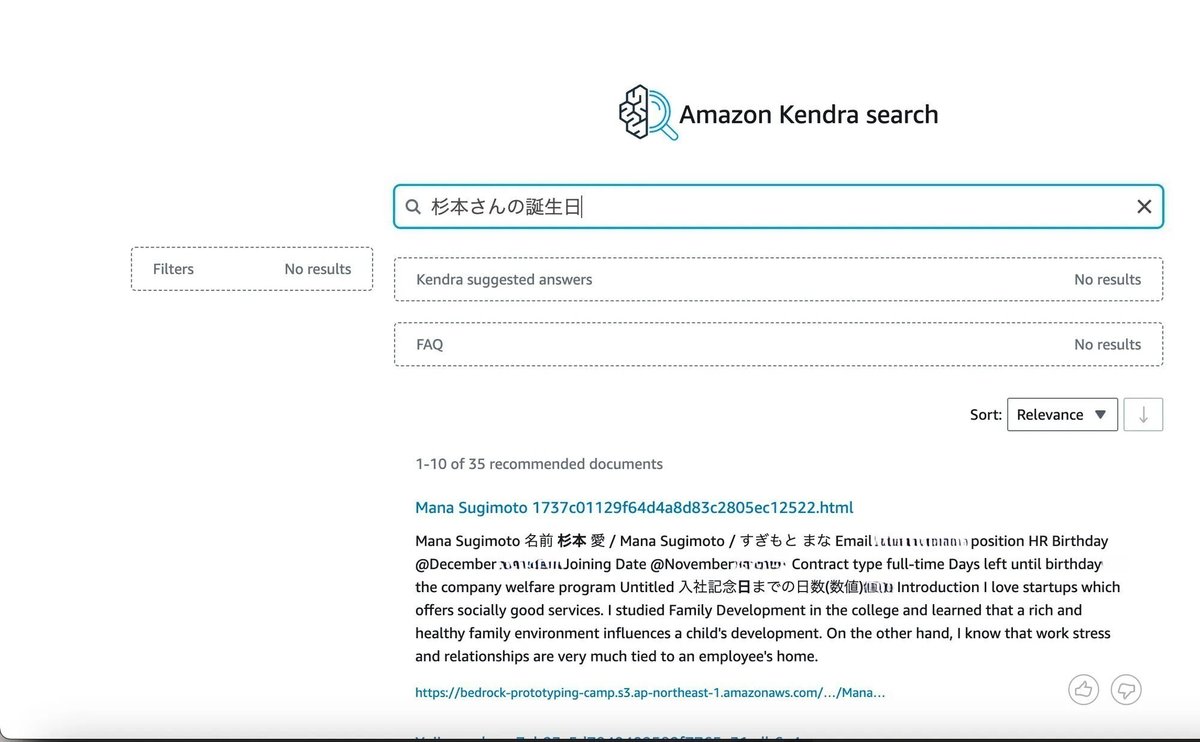
S3にアップロードしたhtmlファイル内の情報をKendra searchで取り出せていることが確認できました。
③Lambdaでのプロトタイピングの実装
上記の①で説明したBedrockのLLMと②のKendraによる検索を組み合わせ、s3上のドキュメントをもとにユーザーからの質問を答えるlambda関数を作成します。
実行の際、boto3に関してエラーが出たので、こちらのサイトを参考にレイヤーを追加しました
作成した簡易的なlambda_function.pyは以下のようなものになりました。
import boto3
import json
from botocore.config import Config
kendra = boto3.client('kendra')
#Claude2はリージョンを指定しないと東京で公開されていない
my_config = Config(
region_name = 'us-east-1'
)
bedrock_runtime = boto3.client('bedrock-runtime',config=my_config)
# プロトタイプのためここでは質問文をハードコーディングしています
question = "Elroy Galbraith's university"
#TODO:検索する際のキーワードを質問文から抽出する必要がある
#TODO:文間ベクトル類似度とキーワード検索のアンサンブルができないかを考える
def kendra_search(event, context):
query_text = question
# 自分のKendra インデックス ID に置き換え
index_id = 'Kendra-index_id'
response = kendra.query(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendraの応答のうち、最初の3つの結果を抽出
results = response['ResultItems'][:3] if response['ResultItems'] else []
# 結果からドキュメントの抜粋部分のテキストを抽出
for i in range(len(results)):
results[i] = results[i].get("DocumentExcerpt", {}).get("Text", "").replace('\\n', ' ')
# ログ出力
print("Received results:" + json.dumps(results, ensure_ascii=False))
return results
#return json.dumps(results, ensure_ascii=False)
def lambda_handler(event, context):
# プロンプトに設定する内容を取得
information = kendra_search(event, context)
information_prompts = ""
for i in information:
information_prompts = information_prompts + "情報:「" + i + "」\n"
prompt = f"""
Human:
あなたは株式会社Yoiiの社内の規則やメンバーの情報などを説明するチャットbotです。
以下の情報を参考に、社内のメンバーからの質問について答えてください。
情報:「{information_prompts}」
質問:「{question}」
与えられたデータの中に質問に対する答えがない場合、
もしくはわからない場合、不確かな情報は決して答えないでください。
わからない場合は正直に「わかりませんでした」と答えてください。
また、一度Assistantの応答が終わった場合、その後新たな質問などは出力せずに終了してください。
Assistant: """
print("プロンプト : ",prompt)
# モデルの設定
modelId = 'anthropic.claude-v2'
accept = 'application/json'
contentType = 'application/json'
# リクエストBODYの指定
body = json.dumps({
"prompt": prompt,
"max_tokens_to_sample":600,
})
# Bedrock APIの呼び出し
response = bedrock_runtime.invoke_model(
modelId=modelId,
accept=accept,
contentType=contentType,
body=body
)
# APIレスポンスからBODYを取り出す
response_body = json.loads(response.get('body').read())
return response_body実際のnotionで、ElroyさんはHokkaido University(北海道大学)でPhDを取得していることが確認できます。

以下がLambdaからの応答です。
Response
{
"completion": " 情報の中に、Elroy Galbraithさんの大学名についての記載がありました。\n\n「I obtained from Hokkaido University.」\n\nという記載から、Elroy Galbraithさんの大学は北海道大学であることがわかります。\n\n以上で回答を終了します。ご質問ありがとうございました。",
"stop_reason": "stop_sequence",
"stop": "\n\nHuman:"
}適切に実行されていることが確認できました。
後はAPI Gatewayの設定などを行えば、一番初めの画像のようにslack上でLLM-bot化させたりすることができると思います。
今後の展望
1.ユーザーの質問文から、検索クエリを別途作成
ユーザーの質問文をそのままKendraなどの検索エンジンに投げると、質問口調や雑談がノイズとなって検索の精度が高くならない可能性が考えられます。
先に一度、LLMに質問文を元にした検索クエリを生成させ、それをベクトル検索に投げてやる、等の処理を行えば、精度が上がる可能性が高いと考えられます。
2.日英の対応
Yoiiの社内公用語は英語ですが、ドキュメントによっては日本語で作成されたものもあります。学習方法やベクトルDBによっては日本語のクエリから対応する英語情報を取得することもできますが、検索精度においてしばしば問題が発生することもあると感じています(RAG全般における課題の話であり、Kendraがどの程度のクオリティなのかは未検証です)
対応策としては、
-あらかじめ文書データをすべて機械翻訳にかけておく
-二つの言語が両立した状態のままデータベースを作り、質問文が与えられるたび、もう一方の言語に翻訳させて二通りの検索を行わせる
等が考えられます。
3.ユーザーのフィードバックの収集
応答の精度について、都度ユーザーのフィードバックをもらうことで、以降の参考にしたり、学習データに用いたりすることができます。
また、KendraではFAQという項目があり、個別QAを追加することができます。
誤答があった場合、都度ユーザー(社員)にコーナーケースの答えを入力してもらえれば、それだけで以後の応答精度の向上が見込めます。
ユーザーの会話データを集めたり、FAQを拡張したりすることで、更にカスタマイズされた検索エンジンになるのではないかと考えています。
4.データセットの更新・データの信頼度の担保
データベースが常に最新のものでなければ、古い情報・間違った情報を参照し、ハルシネーションのような現象が起こる可能性があります。
そのため、定期的にクローリングを行うことは必須であると考えられます。
また、notionやjiraなどの「古いドキュメントが残り続ける」ようなデータソースを用いる場合、各ドキュメントの閲覧数やlast update dateを参照して重み付けをする、などの対応によって検索精度が上がるのか、今後検証を続けたいです。
まとめ
Kendraは簡単にセットアップができ、チャンクの大きさや検索アルゴリズムなどを自分で考慮せずとも、かなりハイレベルな検索が行われるという点に魅力を感じました。
また、すべてをAWS上のサービスで完結させられる、という点も非常にありがたいです。
近年、LLMやRAGを利用するためのサービスが大量に出現していますが、BedrockやKendraはかなり信頼度の高いサービスなので、試してみる価値があると思います。
We’re hiring!
株式会社Yoiiでは一緒に働く仲間を募集しています。
データエンジニアやソフトウェアエンジニアをはじめ、様々な職種での募集を随時行っていますので、興味がある方は上記の求人一覧をご覧ください。