Python Pandas DataFrame データ抽出

Pandasで生成したデータフレームから必要なデータを抽出するときによく使う方法を列挙する。
モジュールインポート
print("実行環境")
import pandas as pd
import numpy as np
!python -V
print('pandas ' + pd.__version__)
print('numnpy ' + np.__version__)実行環境
Python 3.8.12
pandas 1.3.4
numnpy 1.21.2# 出力時の表示を指定の数値以下にする
pd.set_option('display.max_rows', 10)# データの準備
csv_data = pd.read_csv('iris_test.csv')
csv_data
列名、行名(index)指定でデータ抽出
列名指定で列抽出 単列
csv_data.petal_width0 0.2
1 0.2
2 0.2
3 0.2
4 0.2
...
145 2.3
146 1.9
147 2.0
148 2.3
149 1.8
Name: petal_width, Length: 150, dtype: float64列名指定で列抽出 複数列
csv_data[['sepal_width', 'petal_width']]
行名(index)で行抽出
csv_data[1:4]
行、列の両方をラベル名で抽出 loc
上で書いた行名、列名指定の抽出も含めて、すべてlocで対処が可能。
#単一データ
csv_data.loc[1,'sepal_width'] #[行名(index), 列名]3.0#複数データ
csv_data.loc[1:4,['sepal_width', 'petal_width']]
# 単一行を列として抽出
csv_data.loc[1,:]sepal_length 4.9
sepal_width 3.0
petal_length 1.4
petal_width 0.2
variety Setosa
Name: 1, dtype: object行、列の両方を番号で抽出 loc
csv_data.iloc[5:15,1:3]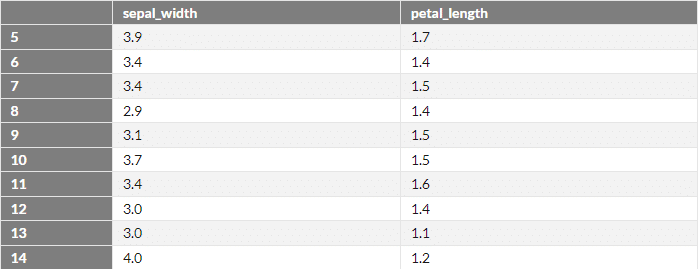
条件指定でデータ抽出
データ抽出 基本のフィルター設定
# 列'variety'の値が'Setosa'の行を抽出
csv_data[csv_data['variety'] == 'Setosa']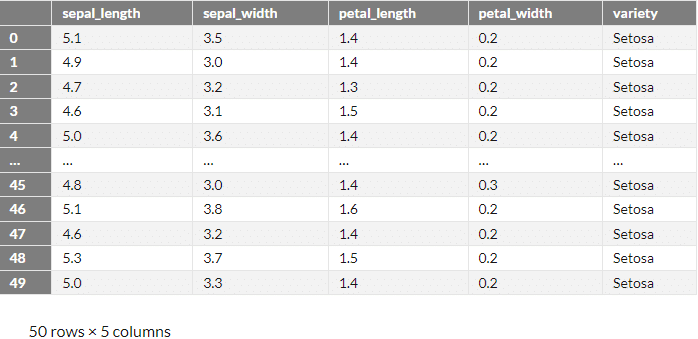
# 列'sepal_length'の値が5より大きい行を抽出
csv_data[csv_data['sepal_length'] > 5]
データ抽出 isinの利用
# 列'variety'の値が'Setosa'と'Versicolor'の行を抽出
csv_data[csv_data['variety'].isin(['Setosa', 'Versicolor'])]