
マイナス金利解除が4月にされると仮定し、今後の動向をpythonで予測してみる。

目的
金利が上昇するという話がさまざまなニュースサイトなどで見かけるようになったため、その影響が日経平均にどのような影響があるのか予測するのが今回の目的であり、今後の参考になれば良いのですが、、、
前準備
と、いうことでまずは今回に大事な準備となり、全てはここがきちんとできないと正確なデータを拾えません。以下の通り日経平均の時系列データと日本の金利を取得していきます。
データを用意する-日経平均
こちらはサクッとpythonのyfinanceライブラリで取得します。取得日は1990年1月から2023年12月まで。
import yfinance as yf
# 日経平均のデータを取得
nikkei_data_for_csv = yf.download("^N225", start="1990-01-01", end="2024-01-01")
# CSVファイルに保存するパスを指定
nikkeidata = 'nikkeidata.csv' # 保存先のパスを適宜設定してください
# CSVファイルに保存
nikkei_data_for_csv.to_csv(nikkeidata)
# 保存したファイルのパスを出力(確認用)
print(f'日経平均のデータは"{nikkeidata}"に保存されました。')データを用意する-金利
今度は金利です。日本銀行の時系列統計データ 検索サイト 様より金利のデータを1990年からcsvファイルでダウンロードができたので、今回はこちらを使わせていただきます。
データの統合
二つのcsvファイルを使いやすいように日付データを合わせて統合します。
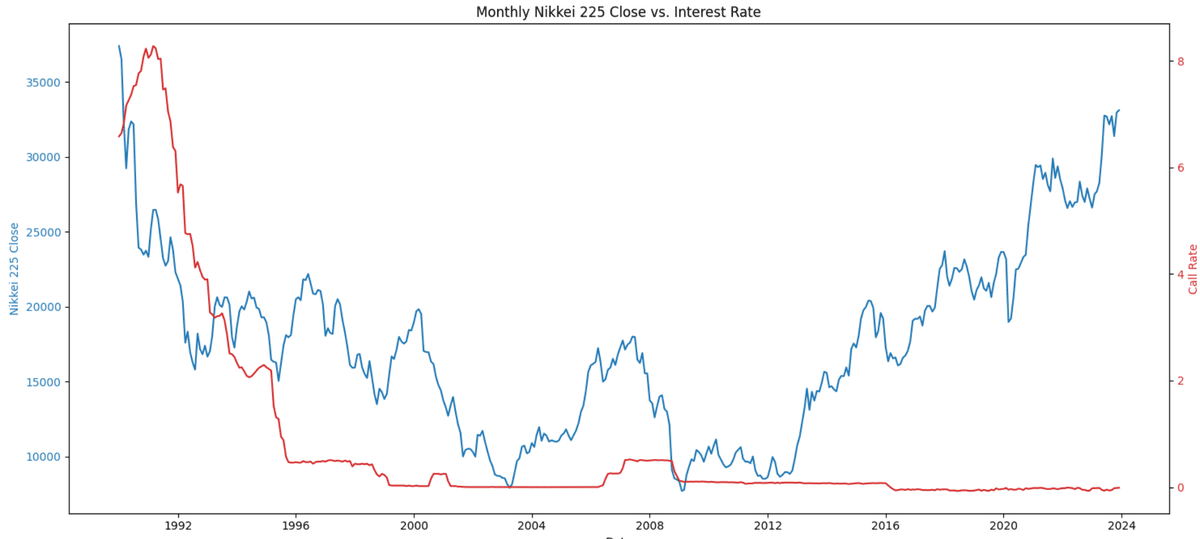
日経平均の終値と金利が日付順でわかるようにし、とりあえずチャートで動きを確認します。
import pandas as pd
import matplotlib.pyplot as plt
# CSVファイルのパス
file_path = 'merged_nikkei_interest_rate_data.csv' # ここに統合されたCSVファイルのパスを入力してください
# CSVファイルを読み込む
data = pd.read_csv(file_path)
# 'Date'列をdatetime型に変換
data['Date'] = pd.to_datetime(data['Date'])
# 正しい列名に置き換えた後のコード
# 月単位でデータを集約するために、日付の列を月の初日に変更
data['Month'] = data['Date'].dt.to_period('M').dt.to_timestamp()
# 正しい列名を確認した後、それに合わせて集計
monthly_data = data.groupby('Month').agg({'Close': 'mean', 'Call Rate': 'mean'}).reset_index()
# チャートの描画
fig, ax1 = plt.subplots(figsize=(15, 7))
color = 'tab:blue'
ax1.set_xlabel('Date')
ax1.set_ylabel('Nikkei 225 Close', color=color)
ax1.plot(monthly_data['Month'], monthly_data['Close'], color=color)
ax1.tick_params(axis='y', labelcolor=color)
# 金利をプロットするために別のY軸を作成
ax2 = ax1.twinx()
color = 'tab:red'
ax2.set_ylabel('Call Rate', color=color) # 正しい金利の列名に置き換えてください
ax2.plot(monthly_data['Month'], monthly_data['Call Rate'], color=color) # 正しい金利の列名に置き換えてください
ax2.tick_params(axis='y', labelcolor=color)
plt.title('Monthly Nikkei 225 Close vs. Interest Rate')
fig.tight_layout()
plt.show()なお、統合に関してはchatGPTに作業してもらいました。手ですると時間がかかってしょうがないので💦そのため、merged_nikkei_interest_rate_data.csvが統合されたものです。興味あればブログの最後にダウンロードリンクを貼っていますので活用ください。
※なお、有料ページとなっているため寄付として購入いただけると幸いです。
ここから本番、機械学習 回帰分析結果
OLS Regression Results
==============================================================================
Dep. Variable: Close R-squared: 0.022
Model: OLS Adj. R-squared: 0.019
Method: Least Squares F-statistic: 8.929
Date: Thu, 14 Mar 2024 Prob (F-statistic): 0.00298
Time: 15:17:05 Log-Likelihood: -4134.9
No. Observations: 408 AIC: 8274.
Df Residuals: 406 BIC: 8282.
Df Model: 1
Covariance Type: nonrobust
=================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------
const 359.1993 13.633 26.348 0.000 332.399 385.999
Time 40.0800 1.626 24.654 0.000 36.884 43.276
Expected Rate 2363.1935 89.727 26.338 0.000 2186.807 2539.580
==============================================================================
Omnibus: 14.986 Durbin-Watson: 0.023
Prob(Omnibus): 0.001 Jarque-Bera (JB): 15.982
Skew: 0.485 Prob(JB): 0.000338
Kurtosis: 2.983 Cond. No. 1.29e+18
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The smallest eigenvalue is 1.36e-29. This might indicate that there are
strong multicollinearity problems or that the design matrix is singular.よくわからないので、chatGPTに解説してもらいます。以下の通り
この回帰分析の結果を解釈してみましょう。回帰モデルは、日経平均の終値を目的変数(依存変数)として、時間(Time)と想定される金利の変化(Expected Rate)を説明変数(独立変数)としています。
R-squared (決定係数): 0.022。この値は、モデルがデータの変動をどれだけ説明できているかを示します。この場合、約2.2%の変動がモデルによって説明されています。これは比較的低い値であり、モデルがデータの変動をあまり説明できていないことを示しています。
Adj. R-squared (調整済み決定係数): 0.019。これは、モデルの複雑さに対するペナルティを考慮した決定係数です。この値も低く、同様にモデルがデータを十分に説明できていないことを示しています。
F-statistic (F統計量): 8.929。これはモデル全体の有意性をテストするために使用されます。Prob (F-statistic) が0.00298という値は、モデルが統計的に有意であることを示しています。
coef (係数): Timeの係数は40.0800で、Expected Rateの係数は2363.1935です。これは、時間と想定される金利の変化がそれぞれ日経平均の終値に与える影響の大きさを示しています。
P>|t|: 各係数のp値です。これらの値が小さい(通常は0.05未満)場合、係数が統計的に有意であることを示します。この結果では、両方の係数が統計的に有意であることが示されています。
[0.025 0.975]: これは係数の95%信頼区間です。係数の真の値がこの区間内にあると95%信頼できます。
Durbin-Watson: 0.023。この統計量は残差の自己相関をテストします。値が2に近い場合、残差間に自己相関はないとされます。このケースでは非常に低い値が示されており、正または負の自己相関がある可能性を示唆しています。
Cond. No.: 条件数で、多重共線性の問題を示唆しています。非常に大きな値(1.29e+18)が示されており、独立変数間に強い相関が存在する可能性があることを示しています。
この分析の結果、モデルがデータの全体的な変動をあまり説明できていない(R-squaredが低い)こと、そして多重共線性の可能性(Cond. No.が非常に大きい)が示されています。モデルの改善や他の変数の検討が必要かもしれません。
洞察と今回の反省
と、いうことでチャートを見てわかる通りあまり参考にならない可能性が高いです。しかし、1990年ごろの金利がかなり高かった頃を考えると、さらに昔の情報を引っ張ってきて同じようにする必要があるかもしれません。例えば、金利が上がっている期間だけに抜粋してみるのが良さそうです。ただし、バブル崩壊がその頃にあったことを考えると金利が上がり続けると同じことが起こっても良いように準備は必要ですね。ただ、日本銀行もそれを望んでいないはずなので、情報をしっかりと取得する必要がありそうです。
ディープラーニングで分析し、チャート表示

洞察と得られた教訓
日経平均の終値と2024年に金利が1%になる想定での結果です。日経平均が3万円ぐらいまで落ちると予測がされました。もちろんこれだけでは何の根拠もありませんが、金利の上昇に伴いポートフォリオの見直しはかけたほうが良いかもしれませんね。今後の反省点としてはもう少し詳細なデータを取得する必要があったかもしれません。それこそバブル崩壊の前のデータも取り入れてその頃の金利と日経平均の動きも考えるべきかもしれません。
今回使用したcsvファイルとディープラーニングのコード
下記有料区域とさせていただいておりますが、ご興味の方はぜひご参考にしてみてください。python初学者の方にはぜひうってつけのデータや参考コードになると思います。
ここから先は
¥ 500
この記事が気に入ったらサポートをしてみませんか?