
VinDr-Mammo: 2万枚の画像が拓く乳がんAI診断の新時代

記事執筆者:稲森 瑠星(医療AIコミュニティ運営者)
レビュアー:大塚(バックエンドエンジニア)
3つの要点
大規模なデータセット
ベトナムの2病院から収集した5,000件の検査(20,000枚の画像)からなる大規模なデジタルマンモグラフィーデータセット高品質なアノテーションと多様な病変情報
経験豊富な放射線科医による二重読影による高品質なアノテーション。乳房レベルのBI-RADS評価、乳腺密度、詳細な病変情報などの多様な情報を含むデータセットの構造と優位性
トレーニングセットとテストセットに分割済みで、研究目的での無料利用が可能。他のオープンデータセットと比較して、画像枚数や情報量が多い点が特徴。
VinDr-Mammo: A large-scale benchmark dataset for computer-aided diagnosis in full-field digital mammography
Hieu T. Nguyen, Ha Q. Nguyen, Hieu H. Pham, Khanh Lam, Linh T. Le, Minh Dao & Van Vu. Sci Data 10, 277 (2023).
Published Online:May 12 2023 https://doi.org/10.1038/s41597-023-02100-7
この記事に含まれる画像は、論文や紹介スライド、またはそれらを参考に作成されたものです。
はじめに
乳がんは世界中の女性にとって最も一般的ながんの一つである。2020年の統計によると、世界で約220万人が新たに乳がんと診断された。この数字は、乳がんが如何に広範囲に及ぶ問題であるかを示している。しかし、乳がんは早期に発見されれば、治療の成功率が大きく向上することが分かっている。実際、2年に1回の定期検診を受けることで、乳がんによる死亡率を30%も低下させることができる。
乳がんの診断には様々な方法がありますが、その中でもマンモグラフィー検査が最も推奨される検査方法である。超音波検査やMRI検査なども使用されますが、スクリーニング検査としてはマンモグラフィーが標準となっている。しかし、マンモグラフィーの読影は決して容易ではない。現状では、マンモグラフィー検査を受けた人のうち約11%が再検査を求められますが、そのうち実際にがんが見つかるのは1,000人中約5人程度である。つまり、多くの人が不必要な再検査や精神的負担を経験していることになる。
この課題を解決するため、近年では人工知能(AI)を活用した画像診断支援システムの開発が進んでいる。深層学習と呼ばれる先進的なAI技術を用いることで、マンモグラフィーの読影精度を向上させる試みが行われている。研究結果によると、AIを用いた画像診断支援システムは、平均的な放射線科医と同等の性能を発揮することが示されている。また、AIと人間の医師が協力することで、単独の場合よりも高い診断精度を実現できることも分かってきた。
これらの研究成果は、AIを活用することで、より正確で効率的な診断を可能にし、不要な再検査を減らし、患者の負担を軽減する可能性を示している。しかし、AIを用いた高精度な画像診断支援システムの実現には質の高い大規模なデータセットが不可欠である。そこで次に、新たに公開された「VinDr-Mammo」データセットの重要性について解説する。
データセットの概要

VinDr-Mammoは、ベトナムの2つの主要病院(ハノイ医科大学病院と108病院)から収集された5,000件のマンモグラフィー検査、計20,000枚の画像からなる大規模データセットである。このデータセットの主な特徴を以下に示す。
規模と多様性:
5,000人の患者(20,000枚)のデジタルマンモグラフィ(FFDM)画像
各検査は標準的な4つのビュー(左右の乳房それぞれCC方向とMLO方向)
アジア人女性のデータを豊富に含む、地理的に多様なデータセット
高品質な注釈:
3名の放射線科医によるアノテーションを行った。2名の放射線科医が読影を行い、読影結果が不一致の場合、経験年数の長い3人目の決定に従う。3名とも10年以上の経験があり、平均19年(範囲14〜22年)であった。
乳房レベルのBI-RADS評価(0〜5)と乳腺密度(A〜D)の情報
病変レベルの詳細な注釈(位置、種類、BI-RADS評価)
多様な病変タイプ:
腫瘤、石灰化、非対称性、構築の乱れなどの主要な異常所見
その他の関連所見(疑わしいリンパ節、皮膚肥厚、皮膚陥凹、乳頭陥凹)
データの構造と利用:
トレーニングセット(4,000検査)とテストセット(1,000検査)に分割済
研究目的での無料利用が可能
画像データとアノテーションデータが別々のファイルで提供
データ作成のプロセスの概要
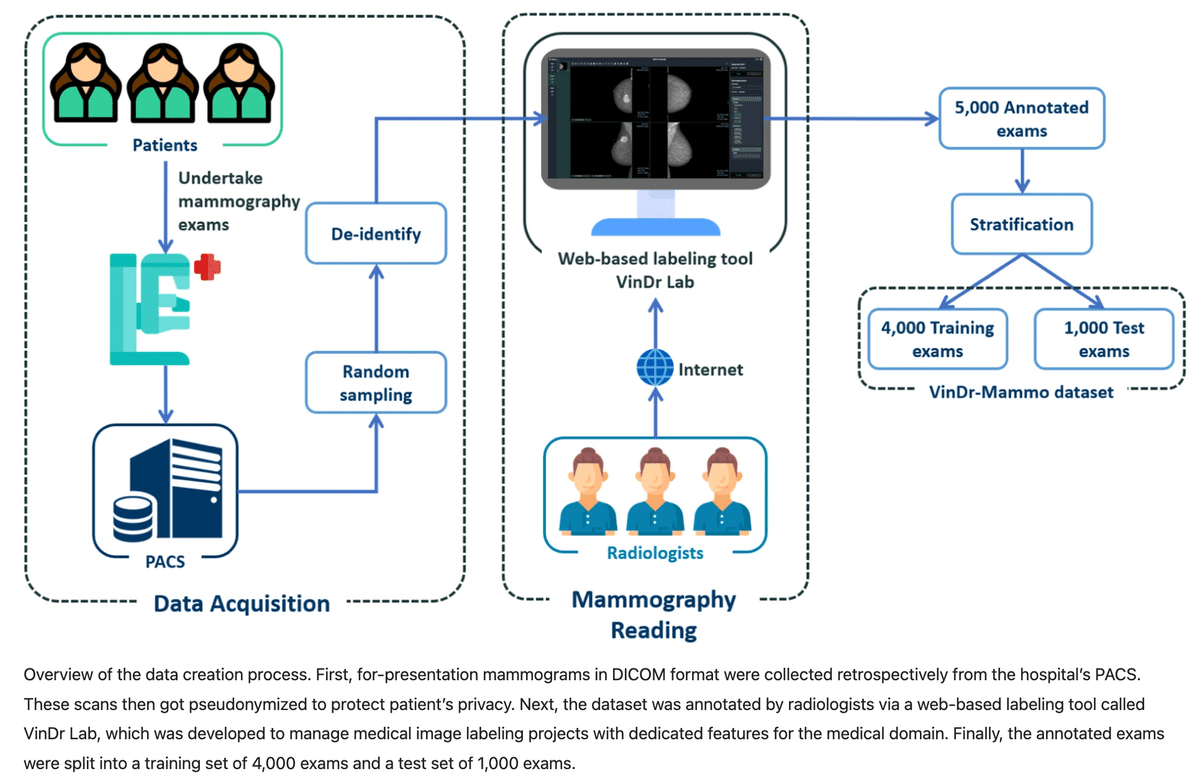
PACSから、2病院で2018年から2020年の間に行われたすべてのマンモグラフィ検査について、5,000件のマンモグラフィ検査、DICOM形式のマンモグラフィ画像20,000枚がランダムに抽出された。
これらの画像は、患者のプライバシーを保護するために仮名化された。
データセットは、放射線科医3名によって注釈付けされた。
注釈付けされたデータセットは、4,000 件の検査のトレーニングセットと 1,000 件の検査のテストセットに分割された。
データセットの分布
BI-RADSの内訳

BI-RADS1 13406
BI-RADS2 4676
BI-RADS3 930
BI-RADS4 762
BI-RADS5 226
TrainingとTestに分割されており、ラベルの割合は各カテゴリとTrainingとTestの間で同程度の割合に調整されている。
病変の内訳(所見数と所見率)

データセット内の病変の内訳は上表に示す通りである。
各病変について、学習用とテスト用のデータセット内に同程度の割合になるように、分割されている。
その他オープンデータとの比較

画像枚数が多く、画像所見や乳腺濃度、アノテーションなどデータセットに含まれる情報量が多い点が異なる点である。
しかし、
病変の輪郭をなぞるようなアノテーションがないこと
病理結果がなくBI-RADSのみであり、真の正解ラベルが分からないこと
これら2点については、注意すべき点である。
補足:病変の輪郭をなぞるアノテーション

アノテーションとは、上図のように病変の輪郭をなぞるようにして、病変部分を綺麗に抽出する作業である。


上図からも分かるように、学習用とテスト用のデータセットの比率や分布など細部までこだわっており、その点では、整備された非常に使いやすいデータセットである。
記事執筆者 稲森 瑠星(医療AIコミュニティ運営者)の感想
データ数が制限されている医療画像において、大規模なオープンデータセットが公開されることの意義は大きい。これまで公開されているその他のオープンデータセットと合わせて、活用していくことで、より良い研究へ繋がる可能性がある。データセット作成として、事前に学習データとテストデータに分割してくれている点、学習とテストにデータ分割を行う際に、マルチラベルの分布にまで同じくらいになるように、気を配って分割した点は非常に丁寧なデータセットである。
レビュワー 大塚(バックエンドエンジニア)の感想
アノテーションの労力がかなりかかっているデータセットであり、データセットの振り分けなども行われている点は、非常に丁寧なデータセットである印象。しかし、病理などによる確定診断が無い点は大きな懸念点になると考えられる。また、診断レポートのデータなどがあれば、NLP研究にも応用可能であり、より良いデータセットであると思う。
この記事が気に入ったらサポートをしてみませんか?