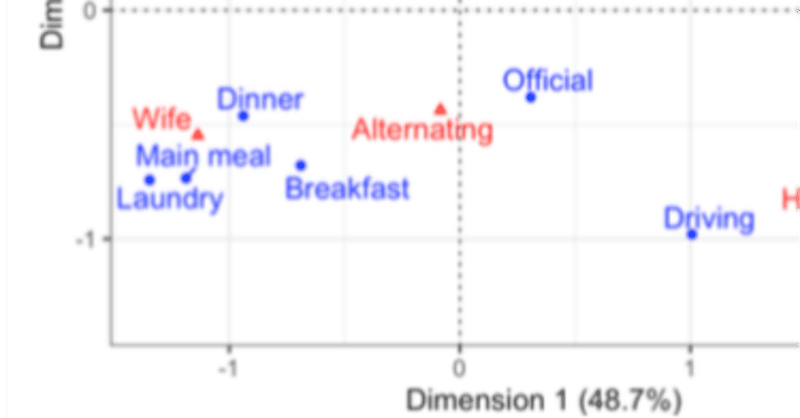
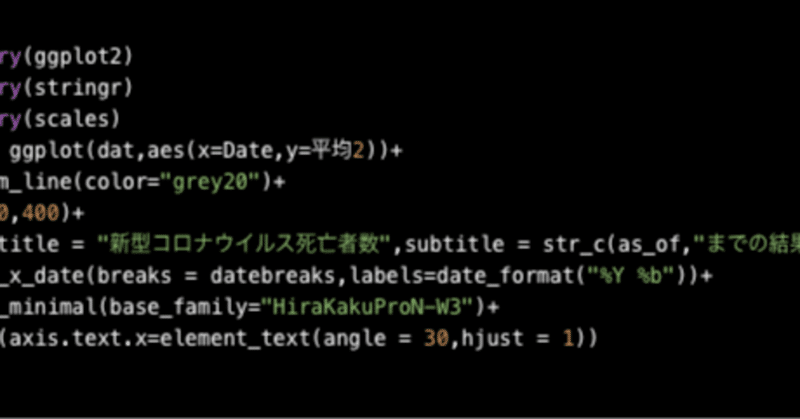
新型コロナ死亡者数のグラフ
データの出所:
https://covid19.mhlw.go.jp/public/opendata/deaths_cumulative_daily.csv
library(readr)death_total <- read_csv("https://covid19.mhlw.go.jp/public/opendata/deaths_cumulative_daily.csv")dat <- death_total[,c(1,2)]colnames(dat)[2] <- "