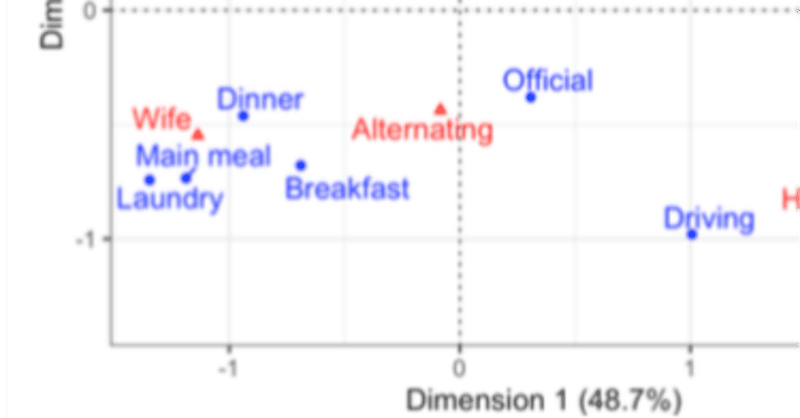
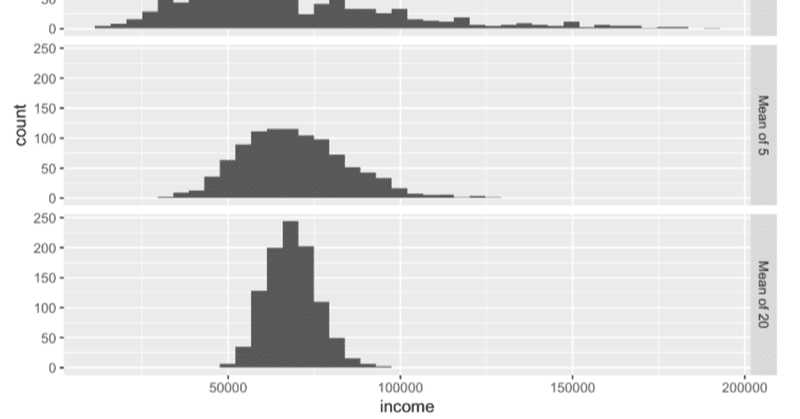
シェア
Rを使い始めた頃に参照していたものの1つは『データ解析環境「R」』(工学社発行)という本であった。著者は、舟尾暢男・高浪洋平の2氏。本に書き込みをしながら読んだ。有意義な本であった。 まず、その本に書き込んだメモを見ながら、Rの使い方を復習してみようと思う。そうすることで、しばらく使わないでいたあとにまごつかないようにすることができるだろう。 別の本(注)も、昔真剣に取り組んだことがある。その本の巻末に「補遺 RとS-PLUSの備忘録」というものがあり、これも復習してみ
『データサイエンスのための統計学入門 第2版』は、副題が「予測、分類、統計モデリング、統計的機械学習とR/Pythonプログラミング」となっている。原著が「Practical Statistics for Data Scientists」であることからもわかるように、内容が、データを扱うサイエンティストにとってたいへんに実用的なものであり、統計分析の有用な手引き書になっている。しかし、よく読んでみると、意味の通らないところなどが各所に見られる。 「作業割り当ての判断」とコ
「カイ二乗検定:リサンプリング方式」の項目を読んでみた。 訳書129ページに、リサンプリングのアルゴリズムの説明(注1)の中で、1から3までのステップがあり、4番目に「2から3のステップを1,000回繰り返す」とある。なぜ1,000回なのかと疑問に思った。その回数にどのような意味があるのかと思って英文を確認してみると、「say」という単語が省略されて訳されてることがわかった。 「2から3のステップを、たとえば、1,000回繰り返す」ということであった。 訳書の次の
「式を用いた統計推論の対象、仮説検定、p値、t検定その他」という表現があった(注1)。なぜここに「対象」と言う言葉が出てくるのか不思議に思った。原文を見ると、「the subject of formal statistical inference」という主語から始まっており、これを「式を用いた統計推論の対象」と訳しているようだ。 原文では、主語のあとにダッシュ記号が続き、「仮説検定、p値、t検定その他」となって、これは例示である。 「式を用いた統計推論の対象」という訳は
B.エベリット『RとS-PLUSによる多変量解析』(シュプリンガー・ジャパン) $${y_n}$$となるべき所が、$${y_q}$$となっていた。 訳書168ページの「コラム8.1:重回帰モデル」の本文1行目。 「目的変数$${y}$$の観測値を$${y_{1},y_{2}, . . . , y_{q}, }$$また$${q}$$個の説明変数$${x_1,x_2, . . . , x_q}$$の観測値を$${x_{i1}}$$, $${x_{i2}}$$, $${. .
『データサイエンスのための統計学入門・第2版』(オライリー・ジャパン)を読んでいる。訳書の63ページに以下のような文がある。 原文は、前後を含めて引用すると以下の通り。ファクタ化するのは、income$typeであって、データフレームincomeの全体ではない。 データフレームをバインドすることと、そのバインドされたデータフレームの1項目(変数名はtypeである)をファクタに型変換することとは別のことである。訳文では、「型変換」という語が使われているが、typeという