シェア
「式を用いた統計推論の対象、仮説検定、p値、t検定その他」という表現があった(注1)。なぜここに「対象」と言う言葉が出てくるのか不思議に思った。原文を見ると、「the subject of formal statistical inference」という主語から始まっており、これを「式を用いた統計推論の対象」と訳しているようだ。 原文では、主語のあとにダッシュ記号が続き、「仮説検定、p値、t検定その他」となって、これは例示である。 「式を用いた統計推論の対象」という訳は
B.エベリット『RとS-PLUSによる多変量解析』(シュプリンガー・ジャパン) $${y_n}$$となるべき所が、$${y_q}$$となっていた。 訳書168ページの「コラム8.1:重回帰モデル」の本文1行目。 「目的変数$${y}$$の観測値を$${y_{1},y_{2}, . . . , y_{q}, }$$また$${q}$$個の説明変数$${x_1,x_2, . . . , x_q}$$の観測値を$${x_{i1}}$$, $${x_{i2}}$$, $${. .
「収入に対する(抵当権を除いた)債務支払い比dtiと、収入に対するローン支払い比payment_inc_ratioの2つの予測変数だけの非常に単純なモデルを考える。」と書いてある(注1)。これでは意味が分からない。「抵当権を除いた」ということがどう意味なのだろうか思って原文を調べてみると、抵当権ではなく「住宅ローン」であった。「収入に対する(住宅ローンを除いた)債務支払い比」ということであれば理解できる。 newloan <- loan200[1, 2:3, drop=F
60パーセントの方が50パーセントの方よりもの多いと統計的にいえるか。 p1=0.60、p2=0.50としてeffect_sizeを計算し、サンプルサイズ(n)を算出する。 effect_size = ES.h(p1=0.60, p2=0.50)pwr.2p.test(h=effect_size, sig.level=0.05, power=0.75,alternative='greater') 0.8にすると、
単に私が最近の統計学の動向に疎いだけなのであるが、違和感を覚える用語がいくつかある。それについて調べてみたい。 (1) 機械学習 これは、statistical machine learningのこと。データに牽引される(data-driven)方法で、線形等の構造をデータに無理矢理に当てはめようとしない、ということのようだ。しかし、なぜ「機械」という言葉が入ってくるのだろうか。「学習」という言葉も。機械に学習させようというのであろうか。 (2) 教師なし学習
「正常な偶然変動の範囲を超えていること」という表現に出会った(注1)。原文は「beyond the range of normal chance variation」であった。 「偶然」とは何なのか考えてみた。少し前から私が関心を持っているスピノザは、『エチカ』(岩波文庫)のなかで「自然のうちには一つとして偶然なものがなく、すべては一定の仕方で存在し・作用するように神の本性の必然性から決定されている」(第1部定理29、畠中尚志氏訳)と書いている。統計学の確率論的世界観とス
グラフのコードの出所: グラフのスクリプト imanishi$Digit <- factor(imanishi$Digit)graph <- ggplot(imanishi, aes(x=Digit, y=Frequency)) + geom_bar(stat='identity') + theme_bw()graph カイ2乗検定の結果: library(ggplot2)x <- seq(0, +180, 0.1)dens <- data.frame(x=x,
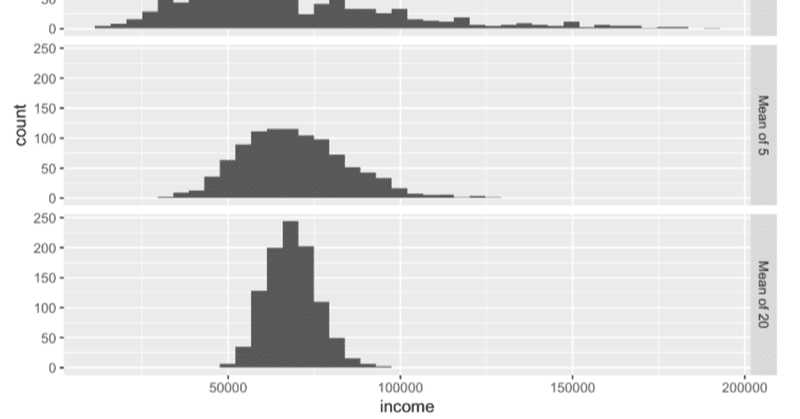
『データサイエンスのための統計学入門・第2版』(オライリー・ジャパン)を読んでいる。訳書の63ページに以下のような文がある。 原文は、前後を含めて引用すると以下の通り。ファクタ化するのは、income$typeであって、データフレームincomeの全体ではない。 データフレームをバインドすることと、そのバインドされたデータフレームの1項目(変数名はtypeである)をファクタに型変換することとは別のことである。訳文では、「型変換」という語が使われているが、typeという
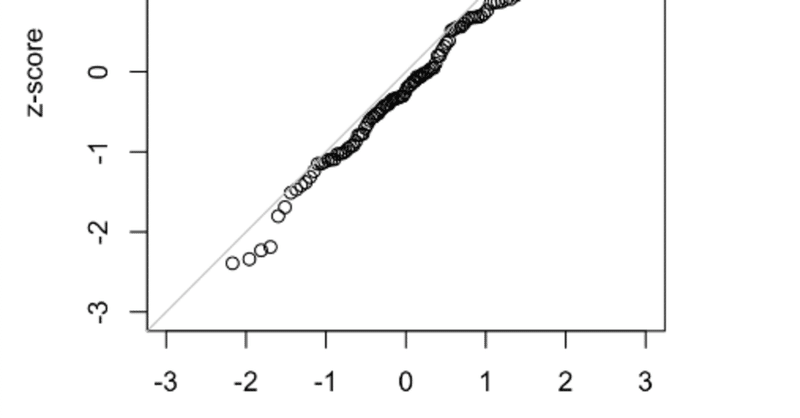
『データサイエンスのための統計学入門・第2版』(オライリー・ジャパン)の75ページに以下のような文章がある。ピンとこないところがあるので調べてみた。 「QQプロットではz値を低いものから高いものに並べ、値のz値をy軸に、値の順位の正規分布に対応する分位数をx軸にとる。データは正規化されるので、平均値から標準偏差単位でどのくらい離れているかがわかる。」 原文は以下の通り。 翻訳では、「データは正規化されるので」となっているが、「データは正規化されているので」でない