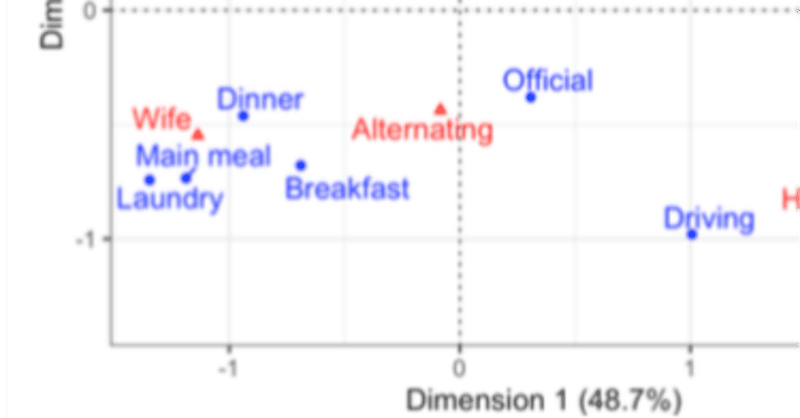
『データサイエンスのための統計学入門』と「say」
「カイ二乗検定:リサンプリング方式」の項目を読んでみた。
訳書129ページに、リサンプリングのアルゴリズムの説明(注1)の中で、1から3までのステップがあり、4番目に「2から3のステップを1,000回繰り返す」とある。なぜ1,000回なのかと疑問に思った。その回数にどのような意味があるのかと思って英文を確認してみると、「say」という単語が省略されて訳されてることがわかった。
「2から3のステップを、たとえば、1,000回繰り返す」ということであった。
訳書の次の