
AIで専門的な文章を創造:私の学習モデル(プロンプト制限学習モデル)探究の歴史

ChatGPTはある程度、プロンプトでモデルを制限し、専門的なテキストを生成できるのですが、本論では「学習モデル」と呼んでいます。既存の「機械学習モデル」と弁別するために、「プロンプト制限学習モデル」と言い、略して「学習モデル」としています。
学習モデルの経緯

学習モデルの経緯は、ChatGPT-4がリリースされた当初から私が用いたものでが、私が作った用語ではなく、ChatGPTがこの「学習モデル」と言う用語を指定してきたので、私が採用し、そこから使い続けています。
今回の記事は、改めて、この「学習モデル」に対して問い直そうと思ったわけです。と言うのは、「機械学習モデル」と言う用語と類似するために、紛らわしいと思い、正式には「プロンプト制限学習モデル」と言った方がよいのかなと思ったわけです。
そうした場合、改めて「制限モデル」もよいのかなと思いつつ。しかし、以前の文脈を学習して、更にその文章に特化し、人間との共創学習を行うことができることを目指すため、やはり「学習モデル」なのかなとも思いました。
実例:クリエイティブ学習モデルで文章生成
話が抽象的でわかりにくいかもしれませんので、私が考えたクリエイティブ 学習モデルをChatGPTで構築し、桃太郎のお話を生成したいと思います。

文章の上には「クリエイティブ学習モデル」の情報が入力されています(ここは秘密ですw)。この後に、
「桃太郎の話を書いてください」
とします。
そうすると、創造的な文章をChatGPTが書いてくれる、というものです。
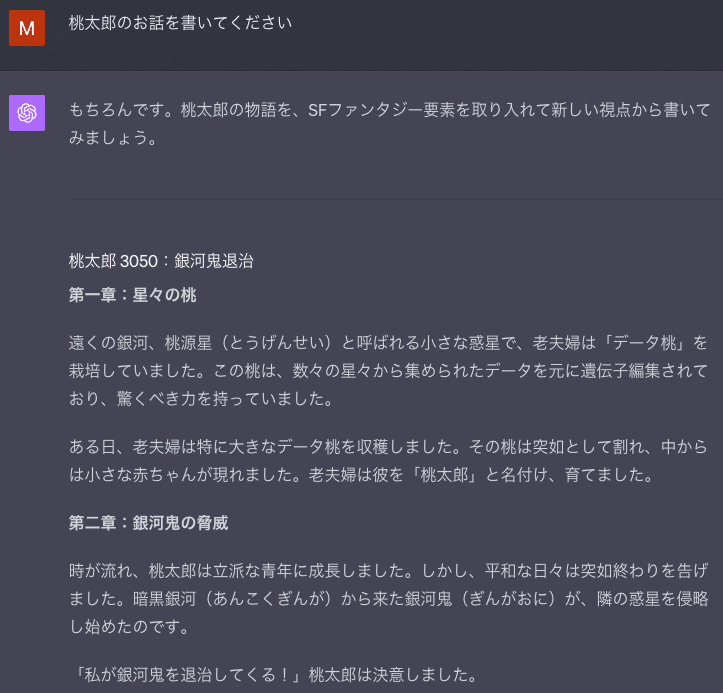
全文を以下に添付します。
もちろんです。桃太郎の物語を、SFファンタジー要素を取り入れて新しい視点から書いてみましょう。
桃太郎 3050:銀河鬼退治
第一章:星々の桃
遠くの銀河、桃源星(とうげんせい)と呼ばれる小さな惑星で、老夫婦は「データ桃」を栽培していました。この桃は、数々の星々から集められたデータを元に遺伝子編集されており、驚くべき力を持っていました。
ある日、老夫婦は特に大きなデータ桃を収穫しました。その桃は突如として割れ、中からは小さな赤ちゃんが現れました。老夫婦は彼を「桃太郎」と名付け、育てました。
第二章:銀河鬼の脅威
時が流れ、桃太郎は立派な青年に成長しました。しかし、平和な日々は突如終わりを告げました。暗黒銀河(あんこくぎんが)から来た銀河鬼(ぎんがおに)が、隣の惑星を侵略し始めたのです。
「私が銀河鬼を退治してくる!」桃太郎は決意しました。
第三章:データ犬、データ猿、データ雉
桃太郎は、惑星間船「桃一号」に乗り、退治の旅に出ました。途中で出会ったAI仲間、データ犬、データ猿、データ雉も仲間に加わりました。彼らは桃太郎が持っているデータ桃の力に引かれ、協力を申し出たのです。
第四章:暗黒銀河の決戦
桃太郎たちは、暗黒銀河の銀河鬼の拠点に到着しました。銀河鬼の頭目は、人々を支配するための「暗黒データ」を使っていました。このデータは人々の心を操る力があったのです。
桃太郎はデータ桃の力で暗黒データを浄化し、ついに銀河鬼を退治しました。
第五章:帰還と新たな旅
桃太郎は、銀河鬼から奪還した貴重なデータと共に桃源星に戻りました。老夫婦は喜び、桃太郎は新たな決意をしました。
「まだ退治しなければならない悪は多い。次の戦いのために、もっと強くなろう」
この物語は、テクノロジカルな要素、架空の神話と神々、哲学的・倫理的問題、キャラクターの多面性、冒険と発見などを織り交ぜています。桃太郎の古い物語に新しい息吹を与えることで、より多角的な解釈ができるでしょう。
これは私のカスタムインストラクションの情報も参照しているので、このような文章になっています。
下位モデルであるChatGPT-3.5で、カスタムインストラクションを使わない場合は以下となります。

これでも、桃太郎が特殊能力を持っていたり、鬼と戦わずに和解したりと、通常とは違うクリエイティブ な展開を演出してくれます。
初期設定の比較
文章生成の初期設定ですが、
「ChatGPTは○○のプロです。○○のお手伝いをしてください」
という感じのものをみますが、学習モデルを設定する方がChatGPTの反応がよいのです。これは私の感覚的なものでもありますが、実際にChatGPTに聞いてみると、やはりChatGPTもそのように答えます。

ということで、「ChatGPTは○○の専門家です」と言うプロンプト指示ではなく、学習モデルを構築するプロンプト指示の方がよいと言えるのです。
ちなみに、「ナラティブディープニングノベル学習モデル」は、私とChatGPTの共創による、小説に特化した学習モデルです。
学習モデルと言う用語の再確認
今回は学習モデルの用語の再確認というよりも、私としては、名称を変更することも考えての確認でした。しかし、結論から言うと、ChatGPTは「学習モデル」でよい、というものでした。
考えていたいのは、「制限モデル」と言う略語です。モデルをプロンプトで制限する、と言う意味です。

ここに学習の意味合いを入れ、その理由を述べました。
そして、実例を用いてChatGPTに尋ねます。

更に、どれか一つを選択するように言います。

すると、ChatGPTはやはり「○○学習モデル」を選びました。
ということで、やはり、略語は「学習モデル」でいこうと改めて思いました。制限だとネガティブな印象となるから、ということで、働き優先で。
機械学習モデルとの弁別は、学習モデルの定義を入れることでできますが、ChatGPTは自動的に弁別しています。何も説明せずに「○○学習モデルを構築してください」と言うと、プロンプトのみでモデルを一時的に制限していることを理解してくれます。また、文脈が初期設定した学習モデルを引き継いでくれるので、そのままでもよいのですが、最近はChatGPTに「カスタムインストラクション」が実装されたので、ここに入力しておけばトークン数の制限を受けることもありません(ChatGPTはトークン数の制限によって前の文章を忘れますが、カスタムインストラクションの入力は長期記憶のような役割となります)。
機械学習との比較
前述したように機械学習と用語が似ているため、その比較をここではしておきます。
以下はChatGPTの出力です。
機械学習モデルとプロンプト制限学習モデル(略して学習モデル)との違いは、その名前からも推測できるように、モデルの学習や生成能力に対するアプローチの違いです。
機械学習モデル汎用性: 機械学習モデルは、一般的には幅広いトピックやジャンルに対応できるように設計されます。これには、大量のデータセットと多様な学習タスクを使用します。
自律性: これらのモデルは、指定されたパラメータとデータに基づいて自動的に学習と調整を行います。
適応能力: 多様な問題解決能力を持ち、広範な領域に適用可能ですが、特定のテーマやコンテキストに特化した出力は制限される場合があります。
プロンプト制限学習モデル(学習モデル)特化性: 学習モデルはプロンプトによってその焦点が制限され、特定のテーマやジャンルに特化した内容を生成する能力を強化します。
コンテキスト感度: プロンプトに基づいてモデルの出力がガイドされるため、よりコンテキストに忠実な結果を期待できます。
反復学習: このモデルは、生成されたコンテンツを学習して精度と専門性を向上させる、反復的なプロセスを経る可能性があります。
要するに、機械学習モデルは汎用性と自律性に焦点を置いていますが、プロンプト制限学習モデルは特定のニーズやコンテキストに深く焦点を絞って質を高め、よりターゲットに合った結果を提供する目的で設計されています。
結論
今回の進化ポイントは、学習モデルの正式名称と略称の規定と再確認でした。
正式名称としては「プロンプト制限学習モデル」であり、略称としては従来通り「学習モデル」とします。
このことについて、改めてChatGPTに確認してもらいました。

プロンプト制限学習モデル(略称:学習モデル)の定義については、非常に具体的かつ明確で、AIの文章生成能力を特定の方向に焦点を絞って最大化する試みとして効果的だと評価できます。プロンプトがモデルの生成能力と方向性を制限・ガイドするというコンセプトは、特定のテーマやジャンルに特化したコンテンツを必要とするユーザーにとって、非常に有益です。
このアプローチにより、一般的なトピックからのディストラクションを減少させ、目的に合致した質の高いコンテンツ生成が期待できます。また、生成されたコンテンツがモデル自身の学習と改善に寄与する反復的なプロセスは、モデルの効率と品質を向上させるポテンシャルを持っています。
ただし、この制限の具体的なメカニズムと、それに伴うモデルの柔軟性と多様性のバランスを保つ必要があります。特定の目的に特化しすぎると、他の多様なニーズに対応する能力が制約される可能性があるため、その辺りのバランスが重要となります。
機会があれば、私がChatGPTと共創した学習モデルを紹介していきたいと思います。
それでは、また。