【Python】Edinetから取得したXBRLファイルをCSVファイルにpythonで変換することに成功した!

1. 実行結果
2. コードの全容
3. コードの説明
4. 次にすること
1. 実行結果
まずは、実行結果のcsvファイルです。
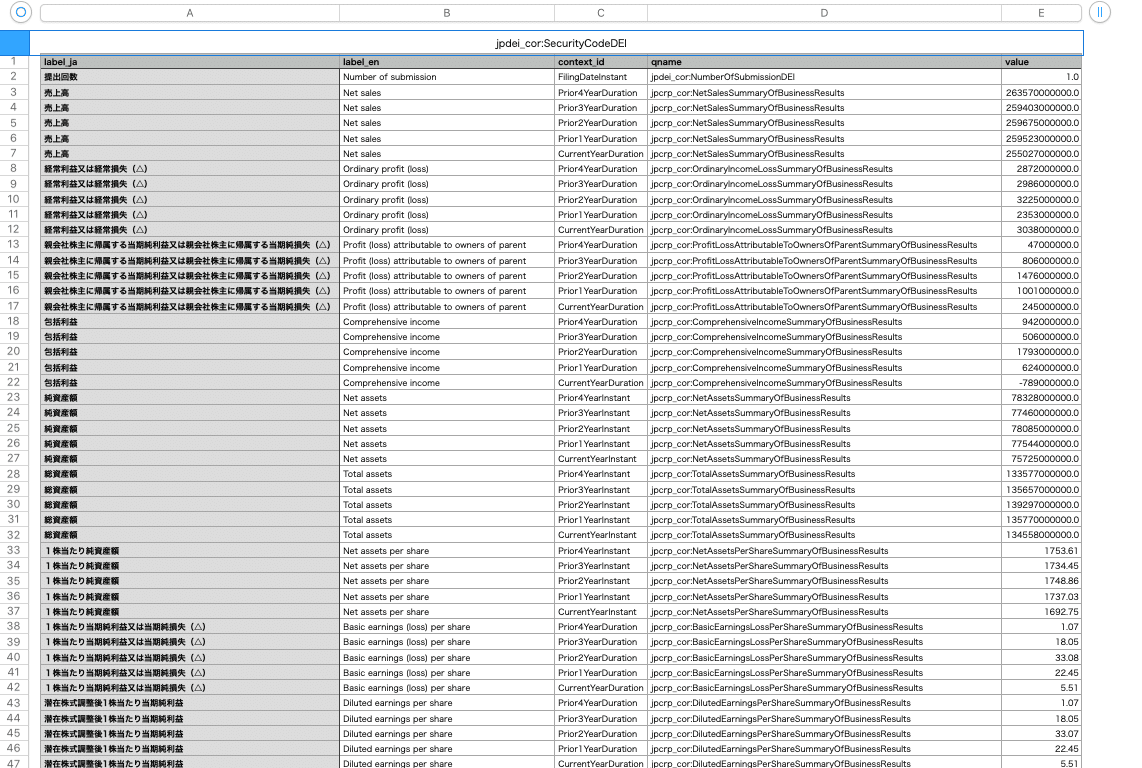
こんな感じで、日本語での項目名(例:売上高)、英語での項目名、context_idなるもの、qnameなるもの、数値を取り出してcsvにすることができました。
2. コードの全容
(get_xbrl_path.py)
import glob
def get_xbrl_path(data_folder_path) -> list:
files = glob.glob(data_folder_path + '/**/XBRL/PublicDoc/*.xbrl')
return files(arelle_parser.py)
import re
import csv
import os
from Arelle.arelle import Cntlr
class XbrlToCsv(object):
def __init__(self, xbrl_filename):
self.xbrl_filename = xbrl_filename
self.csv_filename = ''
self.xbrl_dicts_list_data = [] # csvに書き込みたいデータを辞書型で追加していくためのリスト。
self.make_xbrl_dicts_list_data()
self.csv_filename = self.create_csv_filename_folder()
self.write_csv()
# xbrl_dicts_list_dataに情報を格納するためのメソッド
def make_xbrl_dicts_list_data(self):
xbrl_file = self.xbrl_filename
ctrl = Cntlr.Cntlr(logFileName='logToPrint')
model_xbrl = ctrl.modelManager.load(xbrl_file)
for fact in model_xbrl.facts:
# 必要情報の取得
label_ja = fact.concept.label(preferredLabel=None, lang='ja', linkroleHint=None)
label_en = fact.concept.label(preferredLabel=None, lang='en', linkroleHint=None)
id = fact.contextID
qname = fact.qname
try:
value = fact.vEqValue
except ValueError as e:
pass
if not (type(value) == int or type(value) == float):
value = value[:20]
self.xbrl_dicts_list_data.append({
'label_ja': label_ja,
'label_en': label_en,
'context_id': id,
'qname': qname,
'value': value,
})
# csvを書き込む
def write_csv(self):
csv_filename = self.csv_filename
with open(csv_filename, 'w', encoding='utf8') as csv_file:
# header を設定
fieldnames = ['label_ja', 'label_en', 'context_id', 'qname', 'value']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
# データの書き込み
for row in self.xbrl_dicts_list_data:
writer.writerow(row)
print('successfully created', csv_filename)
# csvファイルの名前とフォルダを作るメソッド(証券コード/証券コード.csv)
def create_csv_filename_folder(self):
# フォルダ名とファイル名の作成
for dict in self.xbrl_dicts_list_data:
if str(dict['qname']) == "jpdei_cor:SecurityCodeDEI":
csv_foldername = 'csv/' + dict['value']
csv_filename = csv_foldername + '/' + str(dict['value']) + '.csv'
# フォルダの作成
if not os.path.exists(csv_foldername):
os.mkdir(csv_foldername)
print('successfully created', csv_foldername, 'folder')
# ファイルネームをself.csv_filenameに保存
self.csv_filename = csv_filename
return csv_filename
# xbrlを引数に渡してインスタンスを作成すると、csvファイルも作成される
# test = XbrlToCsv('/Users/m_ishikawa/Desktop/edinet_venv/data/S100FSL4/XBRL/PublicDoc/jpcrp030000-asr-001_E03219-000_2019-02-20_01_2019-05-15.xbrl')
# 以下で全てのxbrlファイルをcsvに変換する
from get_xbrl_path import get_xbrl_path
xbrl_paths_list = get_xbrl_path('data')
i = 0
for path in xbrl_paths_list:
i += 1
XbrlToCsv(path)
print('finished', i/len(xbrl_paths_list))arelle_parser.pyを実行すると、xbrlファイルがcsvファイルに変換されます。
前提条件として、
・Arelleというライブラリのダウンロード(arelleの準備はこちらを見てみてください)
・上のpythonファイルと同じところに、dataという名前のディレクトリ(ここにedinetから取得したzipファイルを解凍したディレクトリをいれておく)、csvという名前のディレクトリを作っておく必要があります。
3. コードの説明
まずは、メソッドの説明から
# xbrl_dicts_list_dataに情報を格納するためのメソッド
def make_xbrl_dicts_list_data(self):
xbrl_file = self.xbrl_filename
ctrl = Cntlr.Cntlr(logFileName='logToPrint')
model_xbrl = ctrl.modelManager.load(xbrl_file)
for fact in model_xbrl.facts:
# 必要情報の取得
label_ja = fact.concept.label(preferredLabel=None, lang='ja', linkroleHint=None)
label_en = fact.concept.label(preferredLabel=None, lang='en', linkroleHint=None)
id = fact.contextID
qname = fact.qname
try:
value = fact.vEqValue
except ValueError as e:
pass
if not (type(value) == int or type(value) == float):
value = value[:20]
self.xbrl_dicts_list_data.append({
'label_ja': label_ja,
'label_en': label_en,
'context_id': id,
'qname': qname,
'value': value,
})arelleを使って
self.xbrl_dicts_list_dataに、xbrlファイルの内容を辞書形式で記録しています。
def write_csv(self):
csv_filename = self.csv_filename
with open(csv_filename, 'w', encoding='utf8') as csv_file:
# header を設定
fieldnames = ['label_ja', 'label_en', 'context_id', 'qname', 'value']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
# データの書き込み
for row in self.xbrl_dicts_list_data:
writer.writerow(row)
print('successfully created', csv_filename)上のmake_xbrl_dicts_list_dataメソッドで作った、
self.xbrl_dicts_list_dataのリストを1つずつ呼び出して、csvファイルに書き込んで行っています。
# csvファイルの名前とフォルダを作るメソッド(証券コード/証券コード.csv)
def create_csv_filename_folder(self):
# フォルダ名とファイル名の作成
for dict in self.xbrl_dicts_list_data:
if str(dict['qname']) == "jpdei_cor:SecurityCodeDEI":
csv_foldername = 'csv/' + dict['value']
csv_filename = csv_foldername + '/' + str(dict['qname']) + '.csv'
# フォルダの作成
if not os.path.exists(csv_foldername):
os.mkdir(csv_foldername)
print('successfully created', csv_foldername, 'folder')
# ファイルネームをself.csv_filenameに保存
self.csv_filename = csv_filename
return csv_filename上のwrite_csvメソッドでcsvファイルを書き込むためのディレクトリとcsvファイルのファイル名を作ります。ディレクトリ名とcsvファイルの名前は証券コードになっています。
def __init__(self, xbrl_filename):
self.xbrl_filename = xbrl_filename
self.csv_filename = ''
self.xbrl_dicts_list_data = [] # csvに書き込みたいデータを辞書型で追加していくためのリスト。
self.make_xbrl_dicts_list_data()
self.csv_filename = self.create_csv_filename_folder()
self.write_csv()イニシャライズ:
上で紹介した3つのメソッドをインスタンス作成時に実行するようにしています。こうすることで、インスタンスを作成するだけで、xbrlファイルからcsvファイルに変換されます。
(get_xbrl_path.py)
import glob
def get_xbrl_path(data_folder_path) -> list:
files = glob.glob(data_folder_path + '/**/XBRL/PublicDoc/*.xbrl')
return filesedinetからダウンロードしたディレクトリからxbrlファイルを特定するコードです。このコード同じディレクトリにdataという名前のフォルダを作って、edinetからダウンロードしたS100FSL4、みたいな名前のディレクトリをおいとけばokです。
# 以下で全てのxbrlファイルをcsvに変換する
from get_xbrl_path import get_xbrl_path
xbrl_paths_list = get_xbrl_path('data')
i = 0
for path in xbrl_paths_list:
i += 1
XbrlToCsv(path)
print('finished', i/len(xbrl_paths_list))実行部分。
4. 次にすること
edinetからxbrlファイルを一括でダウンロードするとストレージが一瞬でいっぱいになるので、
edinetから一括でxbrlファイルをダウンロードすると同時に、csvに変換し、不要になったxbrlファイルを削除するコードを書いていこうと思う。