
AWSのPMが来た!AWS DMSを使ってOracleとMySQLを同期する

オリジナル投稿日:2019-08-08
IPGの木村です。
今回は、AWS DMS(Database Migration Service)を使った話を紹介していきたいと思います。
実は、使い始めてわかったのですが、あまり DMS を使った事例や Tips がネットに乗っておらず、 1つの事例として参考になれば嬉しいなと思っています。
先日、AWSさんの本国のプロダクトマネージャが来社されて、AWSのDMSのBest Practiceに沿った素晴らしい事例、 と太鼓判押してもらいましたので、自信をもって紹介させてもらいたいと思います。
※ 追記 ※
この話は、本国のAWS Blogでも事例紹介して頂いています。
また、本内容はAWS Japan主催のセミナーでも講演させて頂いています。そのときの内容はこちらでスライドでも紹介させて頂いています。
Introduction
弊社は、日本全国の放送局様よりお預かりした様々な番組データを元に、番組情報をわかりやすく整え、コンテンツデータやメタ情報を加え、テレビやスマートフォーンなどのアプリに対応した番組表を作成しています。

これらを実現しているインフラシステムとして、Amazon RDS for Oracle を利用したデータベースシステムがあります。この Oracle データベース に、番組情報と、それに関わる様々な番組関連情報が入力されて管理しています。
入力データ:
番組情報: 約 25 万番組 (地上波、BS、CS100°、新4K8K衛星放送の未来8日間の番組情報)
放送局: 約 200 局、約 1000 チャンネル
コンテンツプロバイダー: 約 10 社
出力先:
サービスプロバイダー: 約 30 社
これらのサービスを運営するために、可動しているソフトウェアは、以下の通りです。
バッチプログラム: 約 40 programs
オペレーションUI: 約 10 programs
APIサービス: 約 40 programs
これらのシステムは、堅牢で安定的に稼働しています。
しかしながら、以下の課題を内在していました。
システムが密結合となっており変更に対する影響範囲が大きい 社内に Oracle に精通しているエンジニアが少ない
こういった課題を抱えつつも、様変わりするビジネス要件に即座に対応できる体制も必要でした。
検討
一番いい方法は、システム全体をリプレースするというプランですが、これほどのシステムをリプレースしようとすると、莫大な開発リソースと期間を要することが明白でした。
そのため、既存システムは、安定的に維持をしながら、新たな環境で既存データを利用したAPIサービスやコンシューマサービスの開発ができないかと模索しているとき AWS Database Migration Service(DMS)で、継続的にデータをレプリケーションして運用できるということを知りました。
これは、異なるデータベースシステムでデータレプリケーションができるということで、このソリューションの導入を検討しました。
ターゲットデータベース の選定
Oracle からの移行先として、機能互換性の観点から一般的には PostgreSQL が選ばれるケースが多いようです。一方で、社内でよく利用していた データベースエンジン は、MySQL でした。
そこで、移行対象であったシステムで利用している Oracle データベースを AWS Schema Conversion Tool(SCT) でチェックし、それぞれのエンジンの互換性を確認し、移行ターゲットを決めることにしました。
AWS SCT の結果、
Database Storage Object(s):100 %
Database Code Object(s)
View: 100 %
Function: 67 %
を、AWS SCT により自動で変換できることがわかりました。
この結果から、移行先のターゲットデータベースのデータベースエンジンとして、 MySQL を選択し、パフォーマンスとスケーラビリティに優れている Amazon Aurora with MySQL Compatibility に決定しました。

検証
AWS Japan で無償で開催して頂いているハンズオンに参加し、基本的な DMS の操作方法を習得しました。
このハンズオンは、 AWS CloudFormation を利用していて、とても簡単に習得することが可能です。
次に、ステージングシステムで試してみたところ、以下の問題が顕在化しました。
(a) 初期ロードであるフルロード時にソースデータベース(Oracle) の負荷が上がることで業務影響が発生
▶ 原因としては、ソースデータベースのリードスループットが上がったことで、 Network 帯域の上限に達し影響を及ぼしたことが判明
(b) フルロードが、10時間を経過しても終わらない
▶ 原因としては、以下の3点が影響していることが判明
(ア) AWS SCTで自動作成されるスキーマは、外部キーやインデックスが設定されたままのため、フルロードの長時間化を引き起こしていた
(ィ) テーブルマッピングを明示的に指定しなかったため、テンポラリのテーブルなども自動で作成されターゲットテーブルでエラーになっていた
(ゥ) ターゲットデータベースのインスタンスサイズが、小さかったため書き込みにかかる処理速度に影響を与えた
導入
上記の問題が顕在化したことで、改めて以下整理の上、導入構成の検討を実施しました。
今回の我々のユースケースでは、既存の Oracle 環境を維持しながら、 新しい MySQL 環境も並行で運用するというものです。そのため、インフラに関しては、ダブルコストになることが明白です。新しい環境は、できる限り最低限のインフラ構成でランニングコストを抑えるという点を考えなければなりません。
既存の Oracle 環境は、システム停止や構成変更が容易には行えないという点も考慮すべき重要なファクターです。
障害などが発生して、初期ロードから再実行が必要になったようなケースでも、 Oracle 環境には最低限の影響で実行ができることが要求されます。
また、初期ロードの時間が短くなることは、障害復旧におけるRTO(Recovery Time Objective)を短くし、サービスレベルを向上させることに寄与します。
これら念頭におき、以下の調整を実施していきました。
(1) 移行テーブルの明示化
▶ ソースデータベースのデータ量としては、約 500 テーブル/ 約 15 億行のデータが存在していました。サービス利用に必要なテーブルを選別することで、約 160 テーブル/ 約 3.5 億行 に削減しました。
移行タスクに設定する Mapping rule で、すべてのテーブルに対してルールを作成し、各テーブルの "rule-action" として "include"(移行する) or "exclude"(移行しない) を明示的に設定しました。
(2) ターゲットデータベースでの外部キーとインデックスの調整
▶ フルロード時のターゲットデータベースのスキーマから、外部キー制約及びインデックスをすべて外しフルロードを実施しました。
(3) ソース/レプリケーション/ターゲットのそれぞれのインスタンスサイズの調整
▶ 求められるインフラ構成としては、フルロード時は大きなインスタンスサイズで構成しフルロードにかかる時間を短縮。差分適用であるCDC(Change Data Capture)では、必要最低限のインスタンスサイズで構成することでランニングコストを低減することが必要となります。フルロード時に Oracle 環境のインスタンスの構成変更ができないという制限があります。
これらを解決し効率的に運用するために、以降のようなステップで構築をする形としました。
Step1:ソースデータベース(Oracle)の Snapshot を取得し、Snapshot から フルロード専用Oracleインスタンスを復元する。
- Snapshotの作成開始時刻を記録する。
- 復元した Oracle インスタンスには、既存の業務系から接続されない状態とする。
- フルロード専用 Oracle インスタンスのインスタンスサイズは、大きなサイズを選択する。

Step2:フルロード専用Oracleインスタンスをソースデータベースとして、フルロードタスクを実行する。
- レプリケーション/ターゲットデータベースインスタンスのインスタンスサイズは、大きなサイズを選択する。

Step3:フルロード完了後、フルロード専用インスタンス削除、DMSインスタンス及びターゲットデータベースインスタンスサイズの変更
- フルロード専用Oracleインスタンスを削除
- レプリケーション/ターゲットデータベースインスタンスのインスタンスサイズをスケールダウン
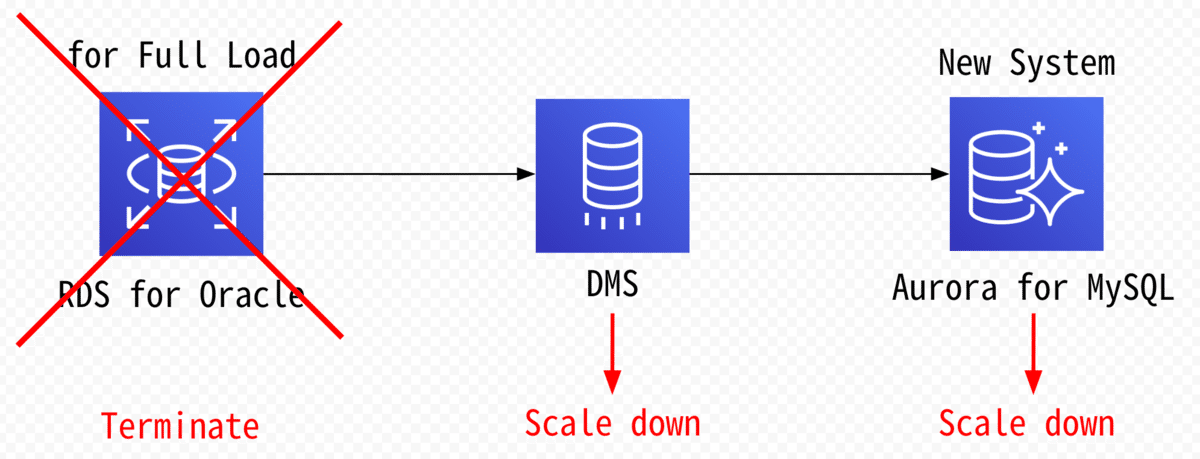
Step4:既存環境の Oracleインスタンスをソースデータベースとして、CDCタスクを実行する。
- Step1で取得した Snapshotの作成時刻から、SCN(system change number)を割り出す。
ex)
SELECT timestamp_to_scn(to_timestamp('16/04/2019 13:46:51','DD/MM/YYYY HH24:MI:SS')) as scn from dual;
SCN
------------
12345678
- CDC start mode に、”Specify log sequence number”を選択し、上記で割り出したSCNをセットする。

全体像

結果
以下に、それぞれの導入結果を記載します。
(1) 移行テーブルの明示化 による効果
▶ データ量の調整を行うことで、フルロード時間を約 3 時間短縮できました。
データ量調整有/無とフルロード時間
$$
\begin{array}{|l|l|} \hline
\text{データ量調整} & \text{所要時間} \\ \hline
\text{無し} & \text{12 時間} \\ \hline
\text{有り} & \text{7 時間} \\ \hline
\end{array}
$$
(2) ターゲットデータベースでの外部キーとインデックスの調整 による効果
▶ フルロード時間を約半分以下に削減できましたが、フルロード後に外部キー制約及びインデックスを付け直すための時間が、フルロードにかかる時間以上にかかってしまいました。
もしかすると、1テーブルあたりの行数が少ないケースでは有用かもしれませんが、我々のケースでは有用ではありませんでした。
そのため、今回は外部キー制約及びインデックスを付けたままフルロードを実施しました。
インデックスありフルロード時間
$$
\begin{array}{|l|l|} \hline
\text{実行方法} & \text{所要時間} \\ \hline
\text{インデックスを付けたままのフルロード} & \text{12 時間} \\ \hline
\end{array}
$$
インデックスなしフルロード時間
$$
\begin{array}{|l|l|} \hline
\text{実行方法} & \text{所要時間} \\ \hline
\text{インデックスをすべて外してフルロード} & \text{5 時間} \\ \hline
\text{インデックスをすべてに付与(8プロセス並列)} & \text{13 時間} \\ \hline
\end{array}
$$
(3) ソース/レプリケーション/ターゲットのそれぞれのインスタンスサイズの調整 による効果
▶ フルロード時のソースデータベースは、スナップショットから復元したインスタンスを利用し、かつ、それぞれのインスタンスサイズを大きくすることで、フルロード時間を約 6 時間短縮できました。フルロード時はそれぞれ 4xlarge を利用し、CDC実行時は、レプリケーションインスタンスを large に、ターゲットデータベースを 2xlarge にスケールダウンし運行できるようにしました。
インスタンスサイズとフルロード時間
$$
\begin{array}{|l:l|} \hline
\text{インスタンスサイズ} & \text{所要時間} \\ \hline
\text{ソースデータベース: large} & \text{} \\
\text{レプリケーションインスタンス: large} & \text{7 h 36 m} \\
\text{ターゲットデータベース: large} & \text{} \\ \hline
\text{ソースデータベース: 2xlarge} & \text{} \\
\text{レプリケーションインスタンス: 2xlarge} & \text{2 h 30 m} \\
\text{ターゲットデータベース: 2xlarge} & \text{} \\ \hline
\text{ソースデータベース: 4xlarge} & \text{} \\
\text{レプリケーションインスタンス: 4xlarge} & \text{1 h 46 m} \\
\text{ターゲットデータベース: 4xlarge} & \text{} \\ \hline
\end{array}
$$
結論
これらにより以下の実現ができました。
既存環境にフルロード時の負荷を与えない。
フルロード時に、インスタンスのリソースを多く取り、フルロードタスクを短い時間で実行することで、RTOを短くする。
CDC時には、最低限のインスタンスサイズに変更することで、ランニングコストを最小限に抑える。

今後の課題
(A) CDC の スタートポイントが曖昧
▶ DMS の機能には、CDC の start mode で SCN を使った移行が可能です。しかしながら、Oracle データベースの Snapshot 取得したタイミングの SCN を特定することができません。現状は、 上記 (3)の Step4 で示すように、Snapshot取得時間から SCN を特定していますが、秒オーダーの精度となるため、そのタイミングで発生した更新の状態が不定になり、データの消失やデータ重複が発生しえるという問題があります。
(B) 再フルロード時の対応
▶ 再フルロード実施時には、ターゲットデータベースのデータが1度クリアされてしまいます。これまでの手順により RTO を短くすることができているので、データが消失されている時間(フルロード中の期間)を短くすることはできましたが、できればこれをもっと短くしたいと考えています。 例えば、ターゲットデータベースには、 CDC が停止したタイミングのデータを保持しながらサービスを継続し、一方で、別クラスタでフルロードを実施させて完了した後に、クラスタを切り替えるなどの手法が取れないか、など。
こういった問題も解決できないか、AWSさんとも相談しつつ進めております。
今後の課題解決の状況も紹介していきますので、引き続き、宜しくお願いします。
エンジニア募集中!
現在IPGでは、機械学習エンジニア、アプリエンジニア、Webエンジニアを募集しています。
こんなエンジニア募集中です。気軽にオフィスに遊びに来てください!ご連絡はこちらまで
生涯エンジニアを希望している人。
何事も「変化すること」を前提に、変化を受け入れ、柔軟に物事を進める事ができる人。
常に新しい技術分野にチャレンジし、良い物はチームや世間に広げたい人。
ユーザーファーストで物事を思考している人。
チームワークを大事にしている人。
効率化のために何でも自動化したくなる人。