
⌘R+, Llama 3, Phi-3, OpenAI Japan, etc - Generative AI 情報共有会 #16

今週、4月30日(火)にZENKIGEN社内で実施の「Generative AI最新情報共有会」でピックアップした生成AI関連の情報を共有します。
この連載の背景や方向性に関しては 第一回の記事 をご覧ください。
様々なLLM
4月も様々なLLMが発表されました。
Cohere、「Command R+」を発表。非商用ながら100B超えで重み公開。(2024/04/04)
RAGに最適化され、研究目的で重みも公開された104BのLLM。
性能でGPT-4-turboに匹敵し、コストは大幅に安価。

GPT-4-turboと同等程度の性能で、コストはGPT-4-turboに対してInputが30%、Outputが50%に抑えられている。
日本語にも対応(10言語対応)。
we built Command R+ to excel at 10 key languages of global business: English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, and Chinese.


Meta、「Llama 3」公開(2024/04/19)
オープンモデルのメインストリームの1つとなっていた、Meta社のLLM、”Llamaシリーズ”として「Llama 3」が公開。META LLAMA 3 COMMUNITY LICENSE AGREEMENTに従う限り商用利用可能。
昨年7月にLlama 2(noteでも紹介しました)が公開されて以降、日本語LLMも多くがこのLlama 2をベースに作成された(こちらを参考にリストアップ)。
Swallow(TokyoTech-LLM)
KARAKURI LM(カラクリ)
Japanese Stable LM Beta(Stability AI)
ELYZA-japanese-Llama-2(ELYZA)
Youri 7B(rinna)
houou-7b(マネーフォワード)
SambaLingo-Japanese(SambaNova Systems)
blue-lizard(Deepreneur)
今後、Llama 3をベースとした日本語LLMが数多く開発されていくか。
【モデル学習】
Llama 2の7倍のテキストデータと4倍のコード(計 15T token以上)で学習。このうち、5%以上が30以上の非英語データ。
【性能】
Llama 2との比較。
Llama 3 8B は、Llama 2 70B と比較して劣りはするが近い性能を達成しているベンチマークもある。Llama 2 13Bと比較すると上回るベンチマークも多い。

8Bモデルは既存のオープンな同程度サイズモデルと比較し高性能。
70Bモデルは、Gemini Pro 1.5やClaude 3 Sonnetに匹敵する性能。

400B超サイズのLlama 3モデルも開発中。

Microsoft、“SLM”(”small language model”)「Phi-3」発表(2024/04/23)
Phi-3-mini(3.8B)をまず公開。128Kコンテキストまで対応(このサイズのモデルで初とのこと)。
MITライセンス。
【性能】
3.8B(Phi-3-Mini-*)と小型のモデルながら、それより大きなモデルと張り合える性能となっている。

記事内で、「モデルサイズが小さいほど事実を保持する能力が低くなるため、事実知識と問うベンチマーク(TriviaQAなど)ではあまり良い結果を示さない」ことが明示されている。
Technical Reportのタイトルが ”Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone”であり、実際にiPhone上で動かしたスクリーンショットが掲載されている。

Apple、”ELM”(”efficient language model”)「OpenELM」発表(2024/04/24)
270M、450M、1.1B、3Bのモデルを公開。
【性能】
Microsoftの「Phi-3」の3.8Bの性能と比較すると(モデルサイズが近いOpenELM-3Bを見ても)MMLUやARC-cなど性能差があるように見える。

スマートフォンなどデバイス上に容易に載せられるような軽量モデルのリリースが活発になってきたか。
OpenAI Japan始動(2024/04/14)
東京にアジア初のオフィスを開設。
社長はAWS Japan前社長の長﨑忠雄氏。
2024/04/28 現在、Account Director、Customer Success Manager、Security Engineer, Detection & Response の採用情報がオープン。
日本語に最適化されたGPT-4カスタムモデルの提供。
3倍高速化。
数か月以内にAPIで広くリリースされる予定。
Microsft、1枚の写真と音声から自然な発話動画を生成する「VASA-1」を発表(2024/04/16)
1枚の写真と音声から自然な発話動画を生成。

自然なリップシンクだけでなく、表情豊かな顔のニュアンスや自然な頭の動きを生成可能。任意の長さの音声を扱うことが可能。
生成動画例
主注視方向や頭部距離、感情などのオプションを設定して動画生成可能。
トレーニングデータに存在しない様々な画像や音声入力(絵画、歌声、英語以外の音声)に対応する能力を示した。
生成動画例(モナリザに歌わせる)
生成動画例
生成動画例(中国語?での発話動画)
外見、頭部、顔の動きを個別に分離し、制御や編集が可能。
同じモーションで異なる外見 生成動画例
頭の動きや表情の分離 生成動画例
NVIDIA RTX 4090 GPU 1枚を搭載したデスクトップPCでスムーズに動作
デモ動画
※ 冒頭に注意書きがされており、この技術に対する非常に慎重な姿勢が見て取れる。
Note: all portrait images on this page are virtual, non-existing identities generated by StyleGAN2 or DALL·E-3 (except for Mona Lisa). We are exploring visual affective skill generation for virtual, interactive characters, NOT impersonating any person in the real world. This is only a research demonstration and there's no product or API release plan. See also the bottom of this page for more of our Responsible AI considerations.
注:このページに掲載されている全ての肖像画像は、StyleGAN2 または DALL-E-3 によって生成されたバーチャルな、実在しないアイデンティティです(モナリザを除く)。私たちはバーチャルな対話型キャラクターのための視覚的な感情スキル生成を探求しており、現実世界のいかなる人物にもなりすましているわけではありません。これはあくまで研究デモンストレーションであり、製品やAPIのリリース予定はありません。私たちの責任あるAIの考察については、このページの一番下もご覧ください。
経産省・総務省、「AI事業者ガイドライン」を公表(2024/04/19)
https://www.meti.go.jp/press/2024/04/20240419004/20240419004.html
「基本理念」と、AIを活用した事業活動を担う主体を3つ(「AI開発者」「AI提供者」「AI利用者」)に大別しどのような取り組みをすべきかの「指針」を示したもの。
【基本理念】
以下の3つの価値を「基本理念」として尊重し、「その実現を追求する社会を構築していくべき」

【指針】
3主体「AI開発者」「AI提供者」「AI利用者」の対応
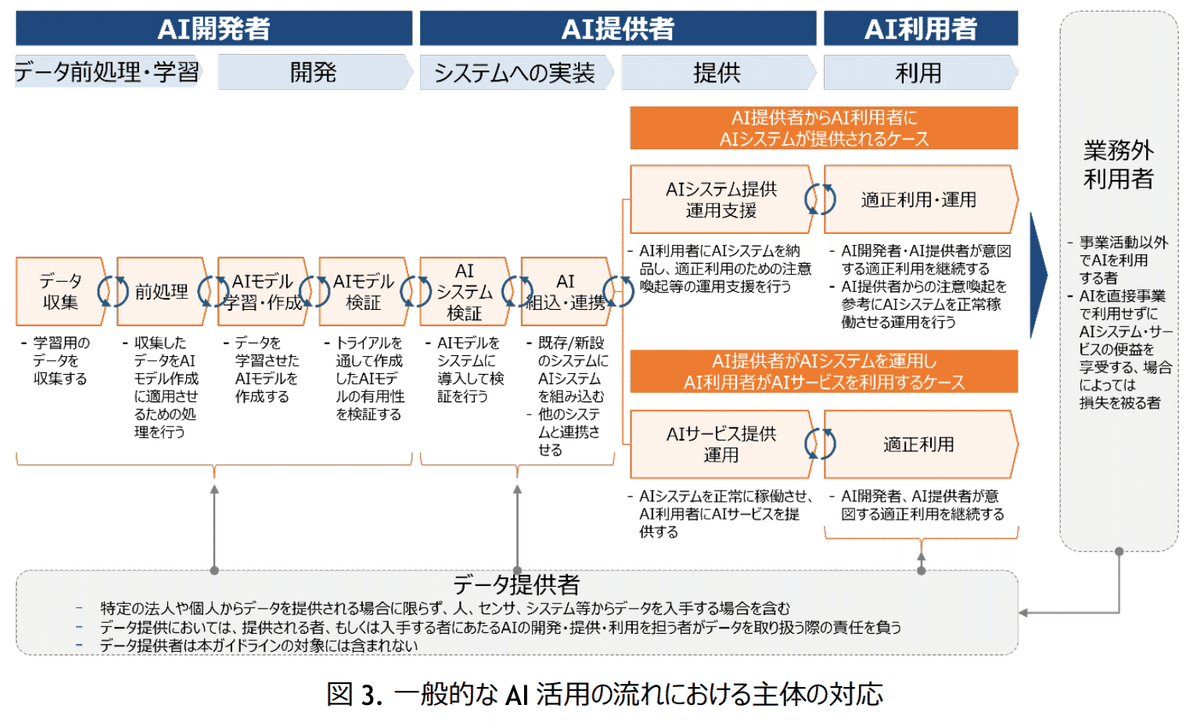
3主体「共通の指針」と主体毎に重要な事項

AI 事業者ガイドライン(第 1.0 版) 別添(付属資料)でAIガバナンス実践のための解説や各主体の具体的な取り組み事項としての「行動目標」や各主体を想定した仮想的な「実践例」が記載されている(157ページ)。
AIガバナンスの構築
経営層によるAIガバナンスの構築及びモニタリング
AIガバナンスの構築に関する実際の取組事例
「AI開発者向け」、「AI提供者向け」、「AI利用者向け」のそれぞれに対する「共通の指針」と「重要となる事項」の解説
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。