
文化を覗く新しい望遠鏡 〜NgramViewer, Word2vec, DALL·E〜

イントロ
近年、ビッグデータや人工知能の発展により、文化や社会を解像度高く分析する方法が提案されてきました。データ分析によって、今まで定性的に分析されてきた文化や社会が定量的に分析され、新しいわくわくするような知見がたくさん出てきています。
文化や社会の分析には、テキスト解析の手法が主に用いられていますが、最近、画像解析の手法の発展も著しく、今後は画像を利用した分析も広がっていくように思います。その中でも、DALL·Eと呼ばれる人工知能の性能は凄まじく、文化や社会を解き明かす新しい分析ツールになりうる可能性を秘めています。
DALL·Eは、文章を入力すると画像を生成してくれる人工知能です。この記事上部の画像は、DALL·Eに「日本のウェルビーイングをテーマにしたピカソ風のアート」を入力して、描いてもらったものです。画像のクオリティはとても高く、人間が描いたのか、人工知能が描いたのかの見極めがつきません。人工知能が「ピカソ風」や「日本のウェルビーイング」という概念を理解して、描いているように見えてしまいます。DALL·Eの登場が、今後、芸術やビジネスなどの幅広い分野に大きな影響を与えていくように思います。過去に、カメラの登場が写実主義に影響を与えたり、写真家という新しい職ができたりしたように。
この記事では、データ分析による文化や社会についてのデータ分析手法を紹介します。まずは、NgramViewer、 Word2vecというテキスト解析の2つの手法を、最後に画像生成手法のDALL·Eを紹介したいと思います。DALL·Eは、芸術やビジネスなどの分野で活用されていくと思いますが、人文社会の研究においても文化を解明する重要なツールとして利用されていくように思います。
Ngram Viewer
Ngram Viewerは、Googleが開発したシステムです。Googleは過去数世紀の書籍をデジタル化しており、Ngram Viewerでは、単語が書籍の中にどれだけ出現していたのかを、簡単に調べられます。例えば、インターネット、テレビ、ラジオの出現回数を調べてみましょう。

ラジオ、テレビ、インターネットの順に盛り上がっていることが、可視化されています。このように、新しい言葉がいつ頃から社会に浸透してきたのか、いつ頃に衰退してしまったのかを定量的に分析することができます。
「カルチャロミクス:文化をビッグデータで計測する」は、このNgram Viewerを作った研究者の書籍です。彼らは、ビッグデータを活用して文化を解析する方法に「カルチャロミクス」と名付けて、書籍内で実例をいくつも紹介しています。例えば、「天安門」などの言葉が検閲により本から消えていることを分析したり、「Merry Christmas」というクリスマスの挨拶がいつから使われるようになったかを分析したりしています。
このようにNgram Viewerという望遠鏡を使って、文化や社会を覗けるようになりました。
Word2vec
Ngram Viewerは、書籍をデジタル化して、単語を集計したもので、アルゴリズムとしては、とてもシンプルなものでした。2013年に発表されたword2vecという手法は、さらに、文化や社会の解析を推し進めるものでした。word2vecは、単語の意味をベクトル化するというもので、単語の足し算引き算を可能にしています。例えば、王様 - 男性 + 女性 = ?をword2vecに解かせると、女王という結果が返ってきます。
word2vecを簡単に使用できるツールやライブラリが整備されたことによって、人文系でも幅広く活用されています。word2vecを活用した面白い研究を3つ紹介したいと思います。
1. 昔と今の単語をつなげる研究
1つ目は、昔の単語に対応する今の単語が何かを見つける研究です。例えば、ウォークマンという単語は、今でいうiPodに対応して、カセットは今でいうmp3に対応することをword2vecを活用して見つけるというものです。まず、今と昔の新聞のデータを利用して、それぞれでword2vecで単語をベクトル化します。そして、今も昔も両方に現れる単語を手がかりにして、片方にしかでてない単語と対応する単語を見つけるという方法です。
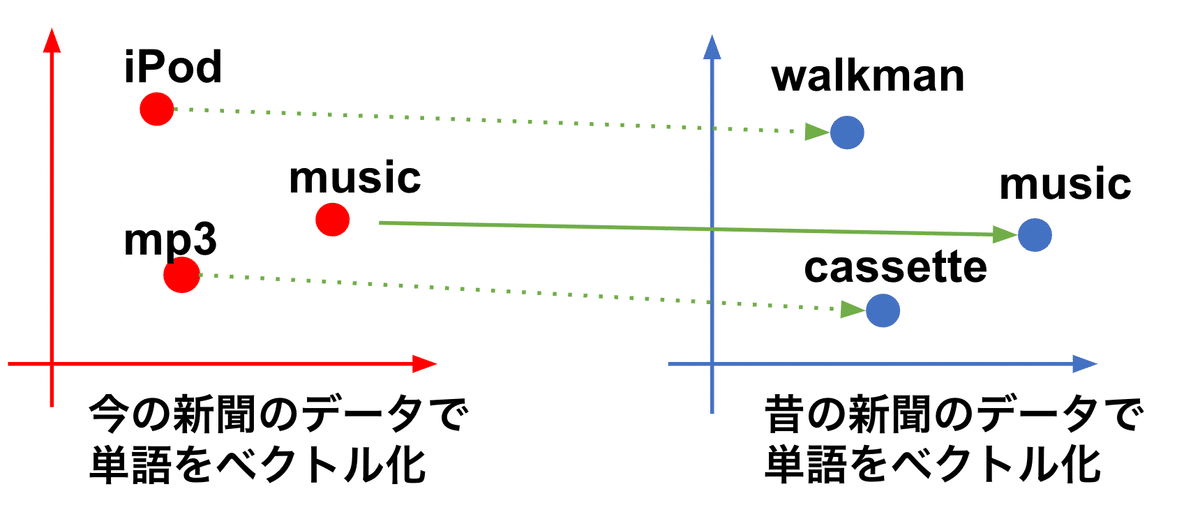
この手法を日本語に適用すれば、昔の「あはれ」は今の「エモい」に対応しているということを機械的に示せるかもしれません。
2. 意味の変化を追う研究
2つ目は、単語の意味の変化を追う研究です。各時代ごとに1つの単語の持つ意味合いがどのように変化したかをword2vecで分析する研究です。例えば、amazonという単語の意味合い変化を見てみましょう。

1993年には、ジャングルや森などの意味でありますが、2000年になるとEコマースなどの企業としてのAmazonの意味合いを持つことが可視化されています。
3. バイアスを明らかにする研究
3つ目の研究は、文化に潜むバイアスを明らかにする研究です。単語に含まれるジェンダーや人種、社会階級のバイアスを分析するものです。例えば、昔は政治家というと男性のイメージが強く、看護師というと女性のイメージが強いものでした。このように単語に暗黙的に含まれるバイアスを大量のデータとword2vecを使って明らかにするというものです。word2vecでは、単語を数百次元のベクトルで表現するのですが、そのベクトルからジェンダーベクトルの要素を抽出するというものです。(以前、ポッドキャストで話したものがありますので、ご興味ある方はこちらの第12回をお聞きください。また、手法をPythonで実装してみたコードがあるので、ご参考までに。)
日本語のデータで試しにやってみたのがこちらになります。
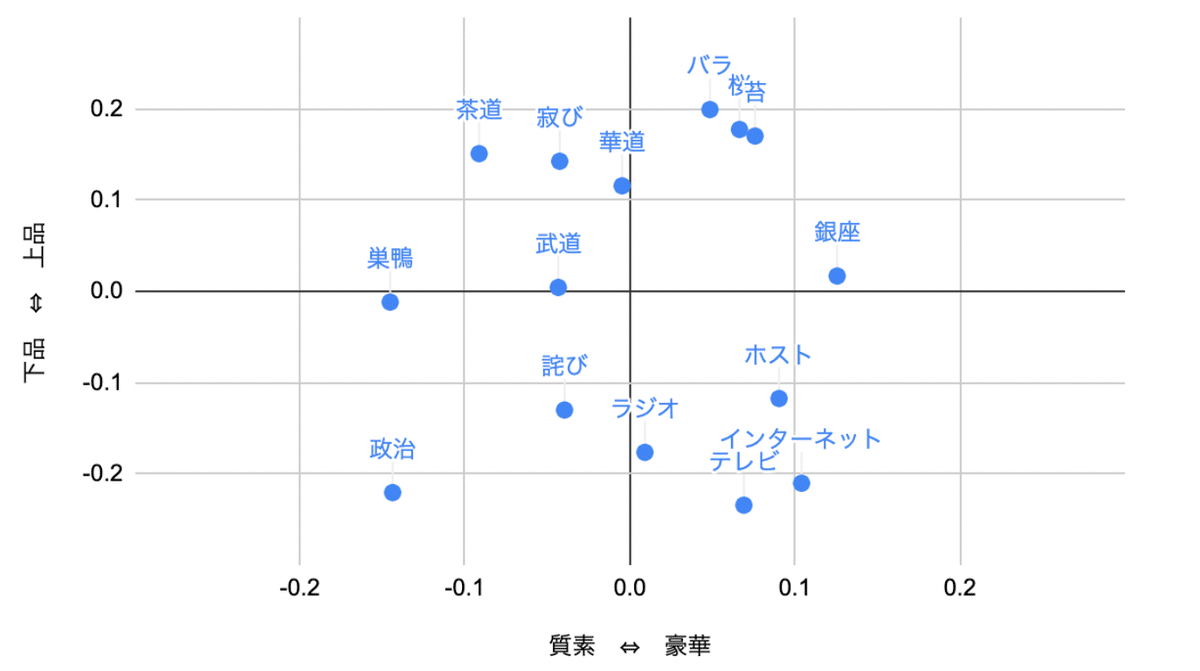
各単語に含まれる印象が可視化されています。
3つのword2vecの研究を紹介しました。どの研究も、今までの人文系の研究にはない切り口で、文化を解明しています。
DALL·E
DALL·Eは、OpenAIという企業が開発した人工知能です。2021年1月にバージョン1が公開されて、今年にバージョン2が公開されました。文章を入力すると画像を生成してくれるのですが、DALL·E2の性能があまりにもすごいので、インターネット上で話題になっています。DALL·E2の利用は無料ですが、申込みが殺到しており、利用開始まで数週間〜数ヶ月待ちになっています。DALL·E2が生成した画像をいくつか見てみましょう。



どの画像も、文章を理解した上で解像度高く生成されています。テディベアの画像では後ろがぼやけていたりと本物の写真のように見えます。人間が描いたのか、人工知能が作ったのかの区別がつかないレベルになっています。(DALL·E2の裏側の仕組みについては、yoheikikutaさんによるこちらの解説記事が分かりやすいです。)
さて、このDALL·E2を使って、文化や社会を覗いてみるとどうなるのでしょうか。DALL·E2の凄さは、単語の概念を的確に把握しているかのように、画像を生成しているところになります。そのため、文化や社会に関する単語をDALL·E2に描かせることで、その単語が持っているイメージを文字通り画像として生成してくれることを期待できます。それでは、実際にDALL·E2に描いてもらったものを見てみましょう。
各時代の成功者の所有物
まずは、各年代ごとの成功者のシンボルとなるような物が何なのかをDALL·E2に描いてもらいます。



2000年代は時計やブランド品が、1950年代には車が描かれています。各年代ごとに特徴的なアイテムが描かれているように思います。今回は「成功者が持っているもの」という切り口で、社会を覗いてみましたが、他にもいろんな切り口で、DALL·E2に描かせることで、分析できるように思います。
各国の文化
各国の文化について、DALL·E2に描いてもらいます。








生成された画像を見ると、日本とアメリカでは大きく違っています。そこに描かれている特徴から、それぞれの国の文化を大まかに解釈することもできそうです。
まとめ
NgramViewer, Word2vec, DALL·Eという3つの手法を紹介しました。それらを使って、文化や社会を覗く方法について解説しました。
この3つの手法を、デジタル化とアルゴリズムの観点で整理してみると、
NgramViewer: 書籍のデジタル化
Word2vec: 単語の意味を表現するアルゴリズム
DALL·E: 画像とテキストのペアのデータ + テキストから画像生成のアルゴリズム
という形で、発展してきたように思います。今後は、画像やテキスト以外のデータを活用した性能が高い手法がどんどん出てくるように思います。例えば、テーマを与えることで作曲したり、小説を与えるとドラマ動画を自動生成したりするものなど。
今後、データの種類や量、アルゴリズムの発展によって、文化や社会研究が進んでいくのが楽しみです。各国のウェルビーイングに関する捉え方が可視化されて、それらが共有されて、より良い社会が実現されていくかもしれません。
最後にデータの注意点をまとめて、終わりにしたいと思います。
データについては、西洋のデータがより蓄積されそれが解析される傾向にあります。DALL·Eにおいて、日本に関する画像生成がどこか古めかしい画像が多く、これは学習時に使われた画像の偏りに起因している可能性もあります。DALL·Eを文化や社会研究に使う場合は、学習時のデータに偏りがないかを確認することが必要になってくると思います。
従来の人文系の研究でも、調査対象が偏っている問題は、WEIRD samples (Western, Educated, Industrialized, Rich and Democratic)と呼ばれ課題となっています。今後、データを活用した研究においても、WEIRDでないデータをどう入れ込むかが重要だと思います。