
文系プログラミング初心者が大阪の翌日の気温予測をしてみました!

1. はじめに
私は4月からオンラインプログラムスクールのAidemy Premiumで「データ分析コース」を3ヶ月受講しており、今回は学習してきた中でより身近な事象をテーマにしたいと考え、気象庁のHPから大阪における過去10年間の気温データから明日の平均気温の予測をしてみました。
2. 私の環境
Python3
Windows13
Google Colaboratory
3. 私のレベル
プログラミング初心者
4.データの取得
大阪府の平均気温の予測をするために必要となる、学習に使う過去データを気象庁のサイトから取得します。サイトでは県や地域の指定や、期間も設定できます。今回は、大阪府における過去10年間の日ごとの平均気温のCSVデータをダウンロードしました。
下記のような2012年6月12日~2022年6月11日までのcsvデータが取得できました。
参考:気象庁HP(https://www.data.jma.go.jp/obd/stats/etrn/index.php)

・
・
10yearsdata.csv
ここからは Google Colaboratoryを使って Python のコードを書いていきます。
5. データの読み込み
先ほどダウンロードしたCSVデータ(10yearsdata.csv)を読み込み、新しく作成するデータを(temperature.csv)として指定し、データを成形します。
なお、(10yearsdata.csv)データは、”r”として読み込み専用、文字コードは、Shift-JIS(日本語文字コード)を 指定をして開いています。
in_file = "10yearsdata.csv"
out_file = "temperature.csv"
with open(in_file, "r", encoding="shift_jis") as fr:
lines = fr.readlines()6. データの整理
データを使いやすくするために、ヘッダー名を編集し、日付部分をスラッシュ(/)区切りではなく、カンマ(,)区切りに変更します。
lines = ["年,月,日,気温,品質,均質¥n"] + lines[5:]
lines = map(lambda v: v.replace('/', ','), lines)
result = "".join(lines).strip()実行した結果を出力し、先ほど設定していた(temperature.csv)ファイルに保存します。
with open(out_file, "w", encoding="utf-8") as fw:
fw.write(result)7. データの形成
まずは、先ほど保存した気温データ(temperature.csv)を読み込み、確認のため、一度表示してみます。
import pandas as pd
df = pd.read_csv("temperature.csv", encoding="utf-8")
print(df)すると、下記のように、6個のカテゴリが3652行表示されました。
さらに、上記データをグラフにして可視化してみようと思います。上の表では、「年」「月」「日」がそれぞれ分かれたカラムになっているため、「年月日」として結合します。さらに桁数を揃え、スラッシュ(/)区切りで見やすくし、グラフ用にデータを整えます。
df['年月日'] = df['年'].astype(str)+"/"+df['月'].astype(str).str.zfill(2)+"/"+df['日'].astype(str).str.zfill(2)
df以下のように、「年月日」の列が追加できました。
ここから、グラフ化していきます。
ラベルが日本語だと文字化けするため英語表記に変換し、また、10年間の日別データをプロットしているため情報量が膨大なので、サイズを大きく設定しました。
df2 = df
df2.index = df2["年月日"]
df2["temperature"] = df2["気温"]
df2.index.names = ['days']
df2[["temperature"]].plot(figsize=(32,16))
8. データを学習用とテスト用に分ける
今回は2012年~2021年までのデータを学習用、2022年のデータをテストデータとして設定します。
さらに、interval = 6として、平均気温を求めたい日の直前 6日のデータから予測するということにします。
train_data = (df["年"] <= 2021)
test_data = (df["年"] >= 2022)
interval = 6そして、直前6日間分を学習するためにデータを整理します。
直前 6 日間のデータと7日目のデータに分け、6 つ毎に区切っては代入を繰り返す学習データを作りました。
def make_data(data):
x = []
y = []
temps = list(data["気温"])
for i in range(len(temps)):
if i < interval: continue
y.append(temps[i])
xa = []
for j in range(interval):
d = i + j - interval
xa.append(temps[d])
x.append(xa)
return(x, y)
train_x, train_y = make_data(df[train_data])ここから、直線回帰分析を使って学習を行います。
どれだけ過去 6 日間のデータを強く反映すれば、当日(7日目)のデータに近い数値を得ることができるのかを計算します。
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(train_x, train_y)
coef = list(model.coef_)
intercept = model.intercept_9. データの検証と予測
引き続き、データの検証テストを行い、その精度を確認します。
test_x, test_y = make_data(df[test_data])
score = model.score(test_x, test_y)
print(score)出力確認すると、今回は0.9358193974387662という高い精度を確認できました。
予測値を返すpredict関数を使って検証データによる予測を行います。
last6d = (df[test_data].iloc[-6:])
last6d_temps = list(last6d["気温"])
pred = model.predict([last6d_temps])
print("明日の大阪の平均気温は " + str(pred[0]) + " 度になるでしょう。")結果として、以下の通り出力されました。
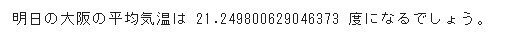
10. まとめ
後日、実際の6/12の大阪の平均気温を確かめてみると、22.6度でした。

高い精度が確認できていましたが、誤差は約1.4度という結果になりました。今回、実際に予測してみて、これまで学習してきた内容について、どのようにデータの分析を行っていくのかイメージができたのが面白く、とても勉強になりました。
まだまだ知識不足で初心者ですが、今後は、降雨の有無など様々な天気予測にも挑戦してみたいと思います。
この記事が気に入ったらサポートをしてみませんか?