【第4章予測】練習問題4.5.1「賭博市場に基づく予測」

1.データセット
・第4章の練習問題を解く際に使うデータセットは、以下のリンク先からダウンロードできる。
2.練習問題4.5.1「賭博市場に基づく予測」
(1)選挙前日の賭博市場価格の予測精度
<2008年の選挙時に関する検証>
①選挙の予測が間違っていたのはIndiana,Missouriの2州
②世論データでの謝りはIndiana,Missouri,North Carolinaの3州
③賭博市場の方が予測精度が高い
> intrade08 <- read.csv("intrade08.csv")
> dim(intrade08)
[1] 36891 8
> intrade08.1103 <- subset(intrade08,subset = (day == "2008-11-03"))
> summary(intrade08.1103)
X day statename PriceD VolumeD PriceR
Min. :36771 2008-11-03:51 Alabama : 1 Min. : 2.60 Min. : 0.0 Min. : 1.30
1st Qu.:36784 2006-11-12: 0 Alaska : 1 1st Qu.: 8.05 1st Qu.: 0.0 1st Qu.: 4.70
Median :36796 2006-11-13: 0 Arizona : 1 Median :77.00 Median : 11.0 Median :23.40
Mean :36796 2006-11-14: 0 Arkansas : 1 Mean :56.56 Mean : 235.2 Mean :43.42
3rd Qu.:36808 2006-11-15: 0 California: 1 3rd Qu.:95.25 3rd Qu.: 144.5 3rd Qu.:90.55
Max. :36821 2006-11-16: 0 Colorado : 1 Max. :98.70 Max. :1711.0 Max. :97.00
(Other) : 0 (Other) :45
VolumeR state
Min. : 0.0 AK : 1
1st Qu.: 1.5 AL : 1
Median : 30.0 AR : 1
Mean : 222.1 AZ : 1
3rd Qu.: 121.0 CA : 1
Max. :2546.0 CO : 1
(Other):45
> intrade08.1103$Winner <- as.factor(ifelse(intrade08.1103$PriceD > intrade08.1103$PriceR,"Obama","McCain"))
> intrade08.1103 <- merge(intrade08.1103,pres08,by = "state")
> intrade08.1103$statename[intrade08.1103$Winner.x != intrade08.1103$Winner.y]
[1] Indiana Missouri
51 Levels: Alabama Alaska Arizona Arkansas California Colorado Connecticut ... Wyoming <2012年の選挙時に関する検証>
①選挙の予測が間違っていたのは、Floridaの1州のみ
②2008年よりも謝りの州が減ったため予測は改善している可能性がある
> intrade12 <- read.csv("intrade12.csv")
> dim(intrade12)
[1] 32623 8
> intrade12.1105 <- subset(intrade12,subset = (day == "2012-11-05"))
> summary(intrade12.1105)
X day statename PriceD VolumeD PriceR
Min. :32520 2012-11-05:50 Alabama : 1 Min. : 0.100 Min. : 0.0 Min. : 0.50
1st Qu.:32532 2011-01-24: 0 Alaska : 1 1st Qu.: 4.375 1st Qu.: 0.0 1st Qu.:12.88
Median :32544 2011-01-25: 0 Arizona : 1 Median :67.850 Median : 0.5 Median :77.50
Mean :32544 2011-01-26: 0 Arkansas : 1 Mean :52.025 Mean : 407.0 Mean :57.47
3rd Qu.:32557 2011-01-27: 0 California: 1 3rd Qu.:95.000 3rd Qu.: 105.0 3rd Qu.:94.78
Max. :32569 2011-01-28: 0 Colorado : 1 Max. :99.500 Max. :6306.0 Max. :99.50
(Other) : 0 (Other) :44 NA's :6 NA's :4
VolumeR state
Min. : 0.0 AK : 1
1st Qu.: 0.0 AL : 1
Median : 0.0 AR : 1
Mean : 410.6 AZ : 1
3rd Qu.: 383.2 CA : 1
Max. :3224.0 CO : 1
(Other):44
> intrade12.1105 <- na.omit(intrade12.1105)
> intrade12.1105$Winner <- as.factor(ifelse(intrade12.1105$PriceD > intrade12.1105$PriceR,"Obama","Romney"))
> pres12 <- read.csv("pres12.csv")
> pres12$Winner <- as.factor(ifelse(pres12$Obama > pres12$Romney,"Obama","Romney"))
> intrade12.1105 <- merge(intrade12.1105,pres12,by = "state")
> intrade12.1105$statename[intrade12.1105$Winner.x != intrade12.1105$Winner.y]
[1] Florida
50 Levels: Alabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida ... Wyoming (2)直近90日間の民主党候補者の選挙人票数予測値の推移
①選挙90〜60日前頃まで、予測値は300人程度のまま横ばい推移
②50日前頃に一時的に予測値が260人程度まで減少し、その後再び上昇
③20日前頃には360人程度に到達し、その後継続して横ばい推移
> intrade08$day <- as.Date(intrade08$day)
> intrade08$DaysToElection <- as.Date("2008-11-04") - intrade08$day
> intrade08 <- merge(intrade08,pres08,by = "state")
> intrade08.90 <- subset(intrade08,subset = ((DaysToElection <= 90) & (DaysToElection > 0) ))
> dem.EV <- tapply(intrade08.90$EV[intrade08.90$Winner.x == "Obama"],intrade08.90$day[intrade08.90$Winner.x == "Obama"],sum)
> plot(90:1,dem.EV,xlim = c(90,0),ylim = c(200,400),col="blue",xlab = "DaysToElection",ylab = "dem.EV",main = "predict dem EV")
> abline(v = 0)
> points(0,365,pch = 19,col ="blue")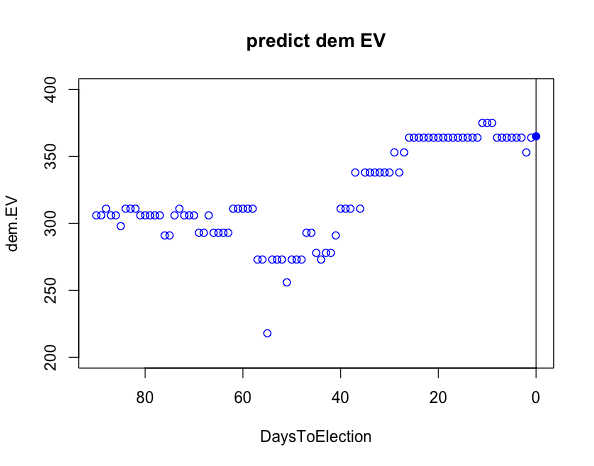
(3)7日移動平均による民主党候補の選挙人予測値の推移
①日ごとの価格に基づく予測よりも値が滑らかなグラフになっている
> MA7.pred <- rep(NA,90)
> for (i in 1:90) {
+ week.data2 <- subset(intrade08,subset = ((DaysToElection <= (90 - i + 7)) & (DaysToElection > (90 - i))))
+ PriceD.MA7 <- tapply(week.data2$PriceD,week.data2$state,mean)
+ PriceR.MA7 <- tapply(week.data2$PriceR,week.data2$state,mean)
+ Price.MA7 <-data.frame(state = names(PriceD.MA7),Diff.Price = (PriceD.MA7-PriceR.MA7))
+ Price.MA7 <- merge(Price.MA7,pres08,by = "state")
+ MA7.pred[i] <- sum(Price.MA7$EV[Price.MA7$Diff.Price > 0])
+ }
> MA7.pred
[1] 311 311 311 311 306 311 311 311 311 311 306 306 306 306 306 306 306 306 306 306 306 306 306 306 306
[26] 306 293 293 293 293 311 311 311 311 311 291 273 273 273 273 273 273 273 273 273 273 273 273 273 278
[51] 278 291 291 291 311 311 311 338 338 338 338 338 338 338 353 353 353 353 364 364 364 364 364 364 364
[76] 364 364 364 364 364 364 364 364 364 364 364 364 364 364 364
> par(mfrow=c(1,1))
> plot(90:1,MA7.pred,xlim = c(90,0),ylim = c(200,400),col="red",xlab = "DaysToElection",ylab = "dem.EV",main = "predict dem EV by MA7")
> abline(v = 0)
> points(0,365,pch = 19,col ="red")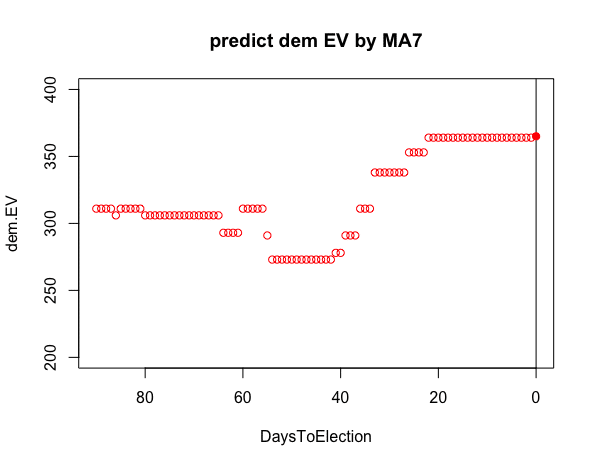
(4)世論調査による民主党候補の選挙人予測値の推移
①選挙90〜60日前頃まで、予測値は340人付近のまま横ばい推移
②50日前頃に予測値が上昇し、20日前頃まで360人付近で推移
③20日前から選挙直近まで予測値は低下し、実績値と乖離
> polls08 <- read.csv("polls08.csv")
> polls08$DaysToElection <- as.Date("2008-11-04") - as.Date(polls08$middate)
> polls08 <- merge(polls08,pres08,by ="state")
> state.unique <- unique(polls08$state)
> n <- length(state.unique)
> m <- 90
> result.pred <- matrix(NA,nrow = n,ncol = m)
> rownames(result.pred) <- state.unique
> for (i in 1:n) {
+ state.data <- subset(polls08,subset = (state == state.unique[i]))
+ state.EV <- unique(polls08$EV[polls08$state == state.unique[i]])
+ for (j in 1:m) {
+ day.data <-subset(state.data,subset = (DaysToElection <= (m-j) ))
+ if (length(day.data$state) >= 1) {
+ Obama.pred <- mean(day.data$Obama.x)
+ McCain.pred <- mean(day.data$McCain.x)
+ result.pred[i,j] <- ifelse(Obama.pred > McCain.pred,state.EV,0)
+ }else{
+ near.day.num <- which(abs(state.data$DaysToElection - m + j) == min(abs(state.data$DaysToElection - m + j)))
+ near.day <- state.data$DaysToElection[near.day.num]
+ day.data2 <-subset(state.data,subset = (DaysToElection %in% near.day))
+ Obama.pred <- mean(day.data2$Obama.x)
+ McCain.pred <- mean(day.data2$McCain.x)
+ result.pred[i,j] <- ifelse(Obama.pred > McCain.pred,state.EV,0)
+ }
+ }
+ }
> result.pred.total <- apply(result.pred,2,sum)
> par(mfrow=c(1,1))
> plot(90:1,result.pred.total,xlim = c(90,0),ylim = c(300,400),col="yellow",xlab = "DaysToElection",ylab = "dem.EV",main = "predict dem EV by poll")
> abline(v = 0)
> points(0,365,pch = 19,col ="yellow")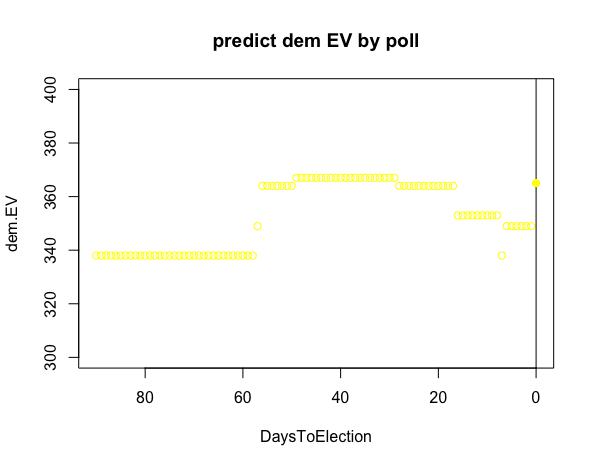
(5)賭博市場の価格又は世論調査での線形回帰
①賭博市場のデータを用いた場合、回帰モデルの決定係数は0.729
②一方、世論調査のデータの場合、決定係数は0.936
③どちらも場合も説明力が高いが、特に世論調査は精度が高い
> intrade08.1103$pre.margin <- intrade08.1103$PriceD - intrade08.1103$PriceR
> intrade08.1103$margin <- intrade08.1103$Obama - intrade08.1103$McCain
> fit.intrade <- lm(margin ~ pre.margin,data = intrade08.1103)
> fit.intrade
Call:
lm(formula = margin ~ pre.margin, data = intrade08.1103)
Coefficients:
(Intercept) pre.margin
1.3027 0.2291
> fit.intrade.summary <- summary(fit.intrade)
> fit.intrade.summary$r.squared
[1] 0.7290092
> polls08$pre.margin <- polls08$Obama.x - polls08$McCain.x
> polls08$margin <- polls08$Obama.y - polls08$McCain.y
> state.polls.day <- tapply(polls08$DaysToElection,polls08$state,min)
> n <- length(state.polls.day)
> state.data2 <- NA
> for (i in 1:n) {
+ state.data <- subset(polls08,subset = (state == names(state.polls.day[i])&(DaysToElection == state.polls.day[i])))
+ state.data2 <- rbind(state.data2,state.data)
+ state.data2 <- na.omit(state.data2)
+ }
> fit.polls <- lm(margin ~ pre.margin,data = state.data2)
> fit.polls
Call:
lm(formula = margin ~ pre.margin, data = state.data2)
Coefficients:
(Intercept) pre.margin
0.6053 1.1100
> fit.polls.summary <- summary(fit.polls)
> fit.polls.summary$r.squared
[1] 0.9366272
> par(mfrow = c(1,2))
> plot(intrade08.1103$pre.margin,intrade08.1103$margin,xlim =c(-100,100),col ="blue",xlab = "pre margin",ylab = "margin",main = "predict margin by intarade")
> abline(fit.intrade)
> abline(v = 0 ,lty = "dashed")
> abline(h = 0 ,lty = "dashed")
> plot(state.data2$pre.margin,state.data2$margin,xlim =c(-100,100) ,col ="red",xlab = "pre margin",ylab = "margin",main = "predict margin by polls")
> abline(fit.polls)
> abline(v = 0 ,lty = "dashed")
> abline(h = 0 ,lty = "dashed")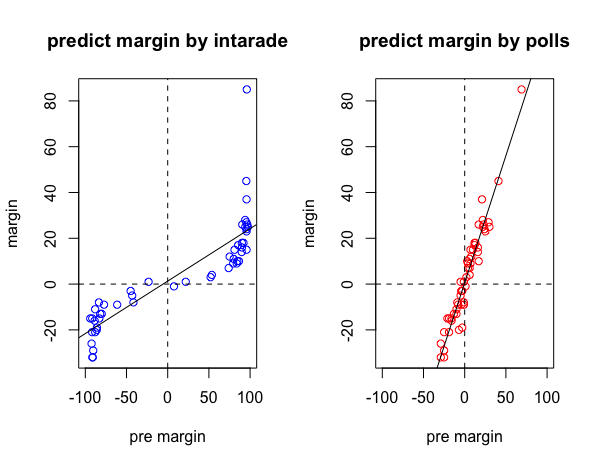
(6)2012年の選挙結果の予測
①世論調査のモデルは、2008年同様に2012年でも説明力が高い
②賭博市場のモデルも勝敗は概ね説明できている。但し実績のマージン
よりも過大に勝敗を予想しているようにみえる。
> intrade12.1105$pre.margin <- intrade12.1105$PriceD - intrade12.1105$PriceR
> intrade12.1105$margin <- intrade12.1105$Obama - intrade12.1105$Romney
> y2012.intrade <- predict(fit.intrade,newdata = intrade12.1105)
> par(mfrow =c(1,2))
> plot(intrade12.1105$pre.margin,intrade12.1105$margin,col ="blue",xlab = "pre margin",ylab = "margin",main = "predict margin by intarade")
> lines(intrade12.1105$pre.margin,y2012.intrade)
> abline(v = 0 ,lty = "dashed")
> abline(h = 0 ,lty = "dashed")
> polls12 <- read.csv("polls12.csv")
> polls12 <- merge(polls12,pres12,by = "state")
> polls12$DaysToElection <- as.Date("2012-11-06") - as.Date(polls12$middate)
> polls12$margin <- polls12$Obama.y - polls12$Romney.y
> polls12$pre.margin <- polls12$Obama.x - polls12$Romney.x
> state.new.day12 <- tapply(polls12$DaysToElection,polls12$state,min)
> n <- length(state.new.day12)
> state.data3 <- NA
> for (i in 1:n) {
+ state.data <- subset(polls12,subset = (state == names(state.new.day12[i])&(DaysToElection == state.new.day12[i])))
+ state.data3 <- rbind(state.data3,state.data)
+ state.data3 <- na.omit(state.data3)
+ }
> y2012.polls <- predict(fit.polls,newdata = state.data3)
> plot(state.data3$pre.margin,state.data3$margin,col ="red",xlab = "pre margin",ylab = "margin",main = "predict margin by polls")
> lines(state.data3$pre.margin,y2012.polls)
> abline(v = 0 ,lty = "dashed")
> abline(h = 0 ,lty = "dashed")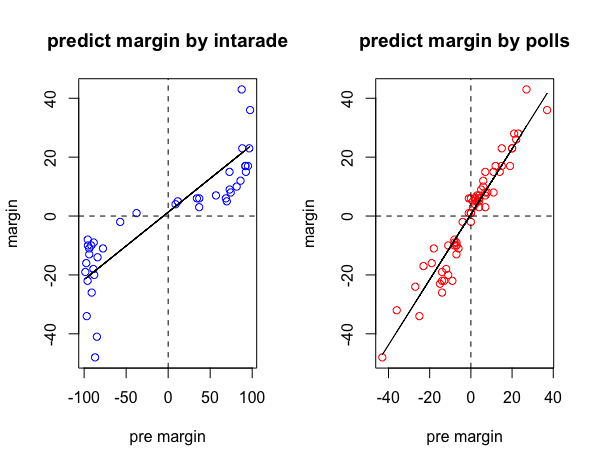
この記事が気に入ったらサポートをしてみませんか?