
Photo by
mjuberry
Python データ構造整理[heapq][deque]

■本記事について
今回の記事ではいつもAtcoder中にpythonの普通のリストだと計算量的に間に合わないけどなんかデータ型使えば上手く行けたはず,,,ってのを記事にしてまとめておきます.
■リスト型の計算量について
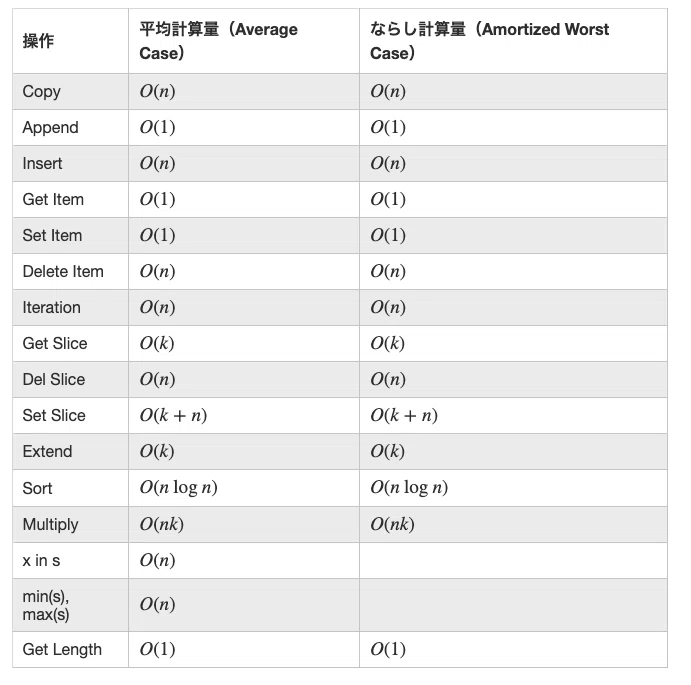
リスト型については上の記事を大変参考にさせて頂きました.下の図は上の記事より引用させて頂いております.要素の挿入や,削除,要素の探索,特定範囲のリストの取り出しはO(n)掛かってしまうことが分かります.
■優先度付きキュー(Priprity queue)[heapq]
優先度付きキューは,
・最小値(最大値)をO(logN)で取り出す
・要素をO(logN)で挿入する
ことができるデータ構造で,Pythonではheapqとして標準ライブラリに用意されています.
主に使うメソッドは3つで,
・heapq.heapify(リスト)でリストを優先度付きキューに変換。
・heapq.heappop(優先度付きキュー (=リスト) )で優先度付きキューから最 小値を取り出す。
・heapq.heappush(優先度付きキュー (=リスト) , 挿入したい要素)で優先度付きキューに要素を挿入。
import heapq # heapqライブラリのimport
a = [1, 6, 8, 0, -1]
heapq.heapify(a) # リストを優先度付きキューへ
print(a)
# 出力: [-1, 0, 8, 1, 6] (優先度付きキューとなった a)
print(heapq.heappop(a)) # 最小値の取り出し
# 出力: -1 (a の最小値)
print(a)
# 出力: [0, 1, 8, 6] (最小値を取り出した後の a)
heapq.heappush(a, -2) # 要素の挿入
print(a)
# 出力: [-2, 0, 1, 8, 6] (-2 を挿入後の a)■collections.deque
dequeはスタックとキューを一般化したデータ構造である.リスト型だと,先頭の要素を取り出したり,追加する時はpop(0), insert(0,x)としたりするが,これは計算量がO(N)かかる.
dequeを使えば,このように前から,後ろから入れたら取り出したりする処理をO(1)でできる.主に幅優先探索,深さ優先探索で使われます.
from collections import deque
l = [0,1,2,3]
q = deque(l)
q.append(4) # 後ろから4を挿入, l=deque([0,1,2,3,4])
q.appendleft(5)#前から5を挿入, l=deque([5,0,1,2,3,4])
x = q.pop() #後ろの要素を取り出す, x=4, l=deque([5,0,1,2,3])
y = q.popleft() # 前の要素を取り出す, y=5, l = deque([0,1,2,3])