
(備忘録)RAGの教科書的な/RAGアーキテクチャの進歩と概要

こんにちはmakokonです。皆さんRAGを使っていますか。
makokonは、普段のチャットでは、いつもシンプルなRAGにお世話になっています。このRAG技術、AIエージェントと絡んで進歩が激しく概要が理解できなくなっていて、一度まとめないといけないなあと考えていたのですが、手頃な論文が見つかったので、これに合わせて備忘録的にまとめました。
テーマはRAGアーキテクチャの進歩と概要です。
ついでに知らなかったベンチマークの紹介もあったのでラッキーでした。
(長いので、興味があるところだけ読んでいただければ)
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
AIエージェントとRAGのよくまとまった教科書です。
様々な構成が説明されています。
RAGとはなんですか
Retrieval-Augmented Generation (RAG)は、大規模言語モデル(LLM)の生成能力とリアルタイムデータ検索を組み合わせたAI技術です。LLMの静的な知識の限界を、外部データ検索で補い、文脈に沿った最新情報を含んだ出力を生成します。
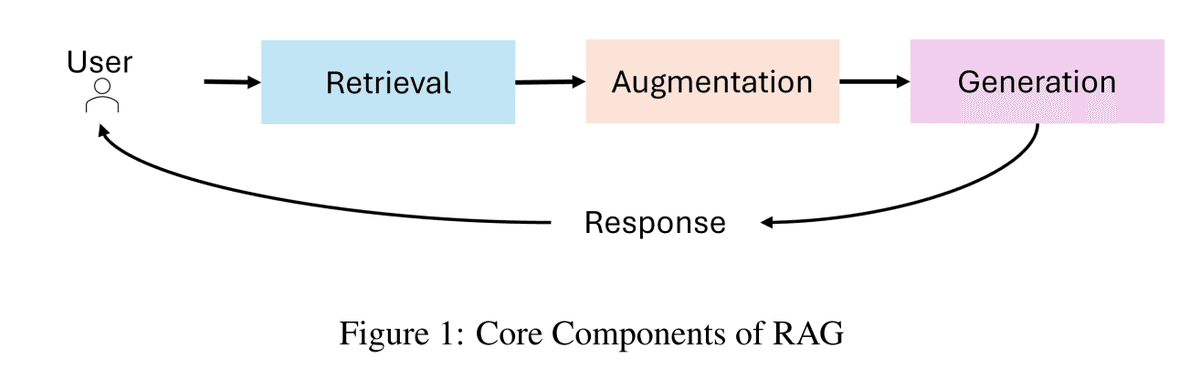
RAGのコアコンポーネント 図1
RAGシステムは、主に3つのコンポーネントで構成されます。
検索(Retrieval): 知識ベース、API、ベクトルデータベース等の外部データソースへの問い合わせを行います。高精度な検索システムは、密ベクトル検索やTransformerベースモデルを活用し、検索精度と意味的関連性を向上させます。
補強(Augmentation): 検索されたデータから、クエリに関連する情報を抽出し要約します。
生成(Generation): 取得した情報とLLMが持つ知識を組み合わせ、首尾一貫した文脈に沿った応答を生成します。
様々なRAGパラダイムの進歩を確認します
RAGは、文脈の正確さ、スケーラビリティ、多段階推論が重要な現実世界のアプリケーションの複雑化に対応するため、大きく進化しました。RAGシステムが複雑なクエリを効率的かつ効果的に処理するための、RAGの進歩を確認してみましょう。

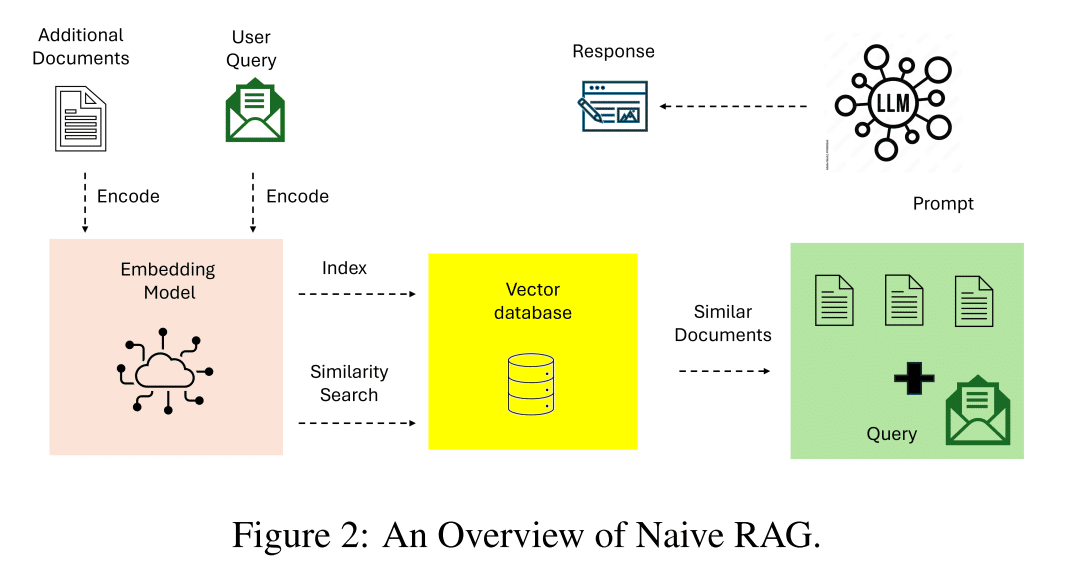
基本的なRAG Naive RAG 図2
Naive RAG は、Retrieval-Augmented Generation の基本的な実装です。キーワードベースの検索と静的データセットに焦点を当てた、単純な取得-読み取りワークフローを使用します。単純なキーワードベースの検索技術を用いて、静的データセットから文書を取得します。取得した文書は、言語モデルの生成能力を向上させるために使用されます。
Naive RAG システムは、検索と生成を統合するための重要な概念実証を提供し、より洗練されたパラダイムの基礎を築きました。
Naive RAG システムの制限事項
文脈認識の欠如: 語彙の一致に依存し、意味理解に基づいていないため、検索された文書はクエリの微妙な意味合いを捉えることができません。
断片的な出力: 高度な前処理や文脈統合がないため、多くの場合、バラバラな応答や一般的すぎる応答が生成されます。
スケーラビリティの問題: キーワードベースの検索技術は、大規模なデータセットでは苦労し、最も関連性の高い情報を特定できないことがよくあります。
意味検索可能なAdvanced RAG 図3
Advanced RAGは、Naive RAGの制限事項を踏まえ、意味理解と高度な検索技術を組み込んでいます。高密度検索モデルとニューラルランキングアルゴリズムを活用して、検索精度を向上させます。
Advanced RAGは、研究の統合やパーソナライズされた推奨など、高精度で微妙な理解を必要とするアプリケーションに適しています。

Advanced RAGの主な特徴
密ベクトル検索: クエリと文書を高次元ベクトル空間で表現することで、ユーザーのクエリと取得された文書間の意味的な整合性を高めます。
文脈に基づく再ランキング: ニューラルモデルは、取得された文書を再ランク付けし、文脈的に最も関連性の高い情報を優先します。
反復検索: Advanced RAGは、マルチホップ検索メカニズムを導入し、複雑なクエリに対して複数の文書を横断した推論を可能にします。
最適化に適した柔軟性を持つModular RAG 図4
Modular RAG は、RAG パラダイムの最新の進化形であり、柔軟性とカスタマイズ性を重視しています。 検索および生成パイプラインを独立した再利用可能なコンポーネントに分解することで、ドメイン固有の最適化とタスクへの適応性を実現します。
このモジュール性とカスタマイズ性により、Modular RAG は複雑なマルチドメインタスクに最適であり、スケーラビリティと精度を提供します。

Modular RAG の主な革新点
ハイブリッド検索戦略: スパース検索手法 (例: スパースエンコーダー-BM25) とデンス検索手法 (例: DPR - Dense Passage Retrieval) を組み合わせることで、多様なクエリタイプにわたる精度を最大化します。
ツール統合: 外部API、データベース、または計算ツールを組み込んで、リアルタイムデータ分析やドメイン固有の計算などの特殊なタスクを処理します。
構成可能なパイプライン: Modular RAG では、検索、生成、およびその他のコンポーネントを個別に交換、強化、または再構成できるため、特定のユースケースへの高い適応性を実現できます。
グラフベースのデータ構造 Graph RAG 図5
Graph RAG は、グラフベースのデータ構造を統合することで、従来のRetrieval-Augmented Generationシステムを拡張します。このシステムは、グラフデータ内の関係と階層を活用して、マルチホップ推論とコンテキストの強化を行います。グラフベースの検索を組み込むことで、Graph RAGは、特に関係の理解を必要とするタスクにおいて、より豊富で正確な生成出力を可能にします。
Graph RAGは、医療診断、法律調査など構造化された関係に基づく推論が重要なドメインのアプリケーションに適しています。

Graph RAGの特徴
ノード接続性: エンティティ間の関係を把握し、推論します。
階層型知識管理: グラフベースの階層を通じて、構造化データと非構造化データを処理します。
コンテキスト強化: グラフベースのパスを活用して、関係に基づいた理解を追加します。
Graph RAGの制限事項
スケーラビリティの制限: グラフ構造への依存により、特に大規模なデータソースではスケーラビリティが制限される可能性があります。
データ依存性: 意味のある出力を得るには、高品質のグラフデータが不可欠であり、非構造化データセットや注釈が不十分なデータセットへの適用性が制限されます。
統合の複雑さ: グラフデータを非構造化検索システムと統合すると、設計と実装の複雑さが増します。
自立エージェント+RAG Agentic RAG
Agentic RAGは、動的な意思決定とワークフローの最適化が可能な自律エージェントを導入することにより、パラダイムシフトを表しています。静的システムとは異なり、Agentic RAGは反復的な改善と適応型の検索戦略を採用して、複雑なリアルタイムのマルチドメインクエリに対応します。このパラダイムは、検索と生成プロセスのモジュール性を活用しながら、エージェントベースの自律性を導入します。
Agentic RAGは、カスタマーサポート、金融分析、適応学習プラットフォームなど、動的な適応性とコンテキストの精度が最重要なドメインで優れています。
Agentic RAGの主な特徴 後で詳しく説明します。
自律的な意思決定: エージェントは、クエリの複雑さに基づいて検索戦略を独立して評価および管理します。
反復的な改善: フィードバックループを組み込んで、検索精度と応答の関連性を向上させます。
ワークフローの最適化: タスクを動的に調整し、リアルタイムアプリケーションの効率性を向上させます。
Agentic RAGの課題
調整の複雑さ: エージェント間の相互作用を管理するには、高度なオーケストレーションメカニズムが必要です。
計算オーバーヘッド: 複数のエージェントを使用すると、複雑なワークフローのリソース要件が増加します。
スケーラビリティの制限: スケーラブルですが、システムの動的な性質により、クエリ量が多い場合に計算リソースに負担がかかる可能性があります。
従来のRAGシステムの限界と挑戦
静的なワークフローと限られた適応性を備えた従来のRetrieval-Augmented Generation (RAG) システムは、複雑な現実世界のアプリケーションでの有効性を阻害する重大な課題を有しています。
複数テキストの統合
複数ステップの推論
スケーラビリティとレイテンシ
Agentic RAGは、動的な意思決定、反復推論、および適応型検索戦略が可能な自律エージェントを組み込むことでこれらの課題を解決できる可能性があります。
エージェントラグのコアコンポーネント 図6
Agentic Intelligence(AI)を備えたAgentic RAGの中核を探ります。

LLM(役割とタスクが定義されている): エージェントの主要な推論エンジンおよび対話インターフェースとして機能します。ユーザーのクエリを解釈し、応答を生成し、一貫性を維持します。
メモリ(短期および長期): 相互作用全体のコンテキストと関連データをキャプチャします。短期メモリは直接の会話状態を追跡し、長期メモリは蓄積された知識とエージェントの経験を保存します。
計画(熟考と自己批判): 熟考、クエリルーティング、または自己批判[26]を通じてエージェントの反復推論プロセスをガイドし、複雑なタスクが効果的に分解されるようにします。
ツール(ベクトル検索、Web検索、APIなど): テキスト生成を超えてエージェントの機能を拡張し、外部リソース、リアルタイムデータ、または特殊な計算へのアクセスを可能にします。
反復 Reflection 熟考 図7
熟考は、エージェントが自身の出力を反復的に評価および改善する仕組みです。
自己フィードバックメカニズムを組み込むことで、エージェントはエラー、不整合、および改善領域を特定して対処することが可能になります。
実際には、熟考とは、エージェントに correctness、style、efficiency についての出力を批評するように促し、このフィードバックを後続の反復に組み込むことを指します。

計画 複雑なタスクを管理しやすいサブタスクに分解する 図8
計画は、エージェントが複雑なタスクをより小さく管理しやすいサブタスクに自律的に分解できるようにします。この機能は、動的で不確実なシナリオでのマルチホップ推論と反復的な問題解決に不可欠です。
計画を活用することで、エージェントはより大きな目標を達成するために必要なステップの順序を動的に決定できます。この適応性により、エージェントは事前定義できないタスクを処理できるようになり、意思決定の柔軟性が確保されます。

ツール使用 外部のツールリソースと対話する 図9
ツール使用は、エージェントが外部ツール、API、または計算リソースと対話することにより、機能を拡張できるようにします。このパターンにより、エージェントは事前学習済みの知識を超えて情報を収集し、計算を実行し、データを操作できます。
最新のagenticワークフローは、情報検索、計算推論、外部システムとのインターフェースなど、さまざまなアプリケーションにツール使用を組み込んでいます。このパターンの実装は、GPT-4の関数呼び出し機能や多数のツールへのアクセスを管理できるシステムなどの進歩に伴い、大幅に進化しました。

マルチエージェント 図10
マルチエージェントコラボレーションは、タスクの専門化と並列処理を可能にします。
中間結果を共有し、ワークフロー全体の効率性と一貫性を確保
特殊化されたエージェント間でサブタスクを分散
複雑なワークフローのスケーラビリティと適応性を向上
複雑なタスクを、異なるエージェントに割り当てられたより小さく管理しやすいサブタスクに分解可能
タスクのパフォーマンスを向上させるだけでなく、複雑な相互作用を管理するための堅牢なフレームワークも提供
各エージェントは独自のメモリとワークフローで動作
ツール、熟考、または計画の使用を含めるのが可能
動的でコラボレーションによる問題解決を可能にします

Agentic RAGのアーキテクチャ
複雑さと設計原則に基づいて、異なるアーキテクチャに分類できる。今回紹介するのは以下のアーキテクチャ。
単一エージェントアーキテクチャ
マルチエージェントシステム
階層型エージェントアーキテクチャ
グラフRAG
単一エージェントアーキテクチャ 図11
単一のエージェントが情報の取得、ルーティング、および統合を管理する集中型の意思決定システムとして機能します。
これらのタスクを1つの統合エージェントに統合することでシステムを簡素化するため、ツールまたはデータソースの数が限られている設定で特に効果的です。

ワークフロー
クエリの送信と評価: ユーザーがクエリを送信するとプロセスが開始されます。調整エージェント(またはマスター検索エージェント)がクエリを受信し、分析して最適な情報源を決定します。
知識ソースの選択: クエリの種類に基づいて、調整エージェントはさまざまな検索オプションから選択します。
構造化データベース: 表形式データアクセスが必要なクエリの場合、システムはPostgreSQLやMySQLなどのデータベースと対話するText-to-SQLエンジンを使用できます。
セマンティック検索: 非構造化情報を扱う場合、ベクトルベースの検索を使用して関連ドキュメント(PDF、書籍、組織レコードなど)を取得します。
Web検索: リアルタイムまたは幅広いコンテキスト情報の場合、システムはWeb検索ツールを活用して最新のオンラインデータにアクセスします。
レコメンデーションシステム: パーソナライズされたクエリまたはコンテキストクエリの場合、システムは調整された提案を提供するレコメンデーションエンジンを利用します。
データ統合とLLM合成: 選択したソースから関連データが取得されると、大規模言語モデル(LLM)に渡されます。LLMは収集された情報を合成し、複数のソースからの洞察を首尾貫一でコンテキストに関連する応答に統合します。
出力生成: 最後に、システムは元のクエリに対処する包括的なユーザー向け回答を提供します。この応答は、実用的で簡潔な形式で提示され、必要に応じて使用されたソースへの参照または引用を含めることができます。
主な機能と利点
集中型のシンプルさ: 単一のエージェントがすべての取得およびルーティングタスクを処理するため、アーキテクチャの設計、実装、および保守が簡単。
効率性とリソースの最適化: エージェントが少なく、調整が簡単なので、システムは必要な計算リソースが少なく、クエリをより迅速に処理できる。
動的ルーティング: エージェントは各クエリをリアルタイムで評価し、最も適切な知識ソース(構造化DB、セマンティック検索、Web検索など)を選択します。
ツール間の汎用性: 構造化ワークフローと非構造化ワークフローの両方を可能にする、さまざまなデータソースと外部APIをサポートします。
よりシンプルなシステムに最適: 明確に定義されたタスクまたは限られた統合要件を持つアプリケーション(ドキュメント検索、SQLベースのワークフローなど)に適しています。

マルチエージェントシステム 図12
マルチエージェントRAG は、複数の特殊化されたエージェントを活用することで、複雑なワークフローと多様なクエリタイプを処理するように設計されています。このシステムは、すべてのタスク(推論、検索、応答生成)を管理するために単一のエージェントに依存する代わりに、特定の役割またはデータソースに最適化された複数のエージェント間で責任を分散します。

ワークフロー
クエリの送信: プロセスはユーザーのクエリから始まり、コーディネーターエージェントまたはマスター検索エージェントによって受信されます。このエージェントは中央オーケストレーターとして機能し、クエリの要件に基づいて特殊化された検索エージェントにクエリを委任します。
特殊化された検索エージェント: クエリは、それぞれが特定の種類のデータソースまたはタスクに焦点を当てた複数の検索エージェントに分散されます。例としては、次のものがあります。
エージェント1:データベースとの対話など、構造化クエリを処理
エージェント2:非構造化データを取得するためのセマンティック検索を管理
エージェント3:Web検索またはAPIからのリアルタイムの公開情報の取得
エージェント4:ユーザーの行動やプロフィールに基づいてコンテキストに応じた提案を提供するレコメンデーションシステム
ツールアクセスとデータ取得: 各エージェントは、ドメイン内の適切なツールまたはデータソースにクエリをルーティングします。取得プロセスは並行して実行されるため、多様なクエリタイプを効率的に処理できます。
ベクトル検索:セマンティック関連性のため。
Text-to-SQL:構造化データのため。
Web検索:リアルタイムの公開情報のため。
API:外部サービスまたは独自のシステムにアクセスするため。
データ統合とLLM合成: 検索が完了すると、すべてのエージェントからのデータがLLM(大規模言語モデル)に渡されます。LLMは、取得された情報を首尾一貫したコンテキストに関連する応答に合成し、複数のソースからの洞察をシームレスに統合します。
出力生成: システムは包括的な応答を生成し、実用的で簡潔な形式でユーザーに返送されます。
主な機能と利点
モジュール性: 各エージェントは独立して動作するため、システム要件に基づいてエージェントをシームレスに追加または削除できます。
スケーラビリティ: 複数のエージェントによる並列処理により、システムは大量のクエリを効率的に処理できます。
タスクの専門化: 各エージェントは特定の種類のクエリまたはデータソースに最適化されているため、精度と検索の関連性が向上します。
効率性: 特殊化されたエージェント間でタスクを分散することにより、システムはボトルネックを最小限に抑え、複雑なワークフローのパフォーマンスを向上させます。
汎用性: 研究、分析、意思決定、カスタマーサポートなど、複数のドメインにわたるアプリケーションに適しています。

階層型エージェントアーキテクチャ 図13
階層型エージェントRAGシステムは、情報検索と処理に構造化された多層アプローチを採用し、効率性と戦略的意思決定の両方を強化します。
エージェントは階層的に編成され、上位レベルのエージェントが下位レベルのエージェントを監督および指示します。この構造により、マルチレベルの意思決定が可能になり、クエリが最も適切なリソースによって処理されることが保証されます。

ワークフロー
クエリの受信: ユーザーはクエリを送信し、初期評価と委任を担当する最上位エージェントによって受信されます。
戦略的意思決定: 最上位エージェントはクエリの複雑さを評価し、どの下位エージェントまたはデータソースを優先するかを決定します。
下位エージェントへの委任: 最上位エージェントは、特定の検索方法(SQLデータベース、Web検索、または独自のシステムなど)を専門とする下位レベルのエージェントにタスクを割り当てます。これらのエージェントは、割り当てられたタスクを独立して実行します。
集約と合成: 下位エージェントからの結果は、上位レベルのエージェントによって収集および統合され、情報を首尾一貫した応答に合成します。
応答の配信: 最終的な合成された回答はユーザーに返され、応答が包括的でコンテキストに関連していることが保証されます。
主な機能と利点
戦略的優先順位付け: 最上位エージェントは、クエリの複雑さ、信頼性、またはコンテキストに基づいてデータソースまたはタスクの優先順位を付けることができます。
スケーラビリティ: 複数のエージェント層にタスクを分散することで、非常に複雑なクエリまたは多面的なクエリを処理できます。
意思決定の強化: 上位レベルのエージェントは戦略的監督を適用して、応答の全体的な精度と一貫性を向上させます。
課題
調整の複雑さ: 複数のレベルにわたる堅牢なエージェント間通信を維持すると、オーケストレーションのオーバーヘッドが増加する可能性があります。
リソースの割り当て: ボトルネックを回避するために層間でタスクを効率的に分散することは簡単ではありません

さらなる機能の追加エージェント
これまでの基本のエージェント構造を踏まえて、追加の機能を実現する事例を紹介します。
Corrective RAG 検索結果を自己修正 図14
Corrective RAGは、検索結果を自己修正するメカニズムを導入し、ドキュメントの活用と応答生成品質を向上させます。ワークフローにインテリジェントエージェントを組み込むことにより、Corrective RAGはコンテキストドキュメントと応答の反復的な改良を保証し、エラーを最小限に抑え、関連性を最大化します。

Corrective RAGの主要なアイデア:
Corrective RAGの中核となる原則は、取得されたドキュメントを動的に評価し、修正アクションを実行し、クエリを改良して、生成された応答の品質を向上させる能力にあります。Corrective RAGは、次のようにアプローチを調整します。
ドキュメント関連性評価: 取得されたドキュメントは、関連性評価エージェントによって関連性について評価されます。関連性のしきい値を下回るドキュメントは、修正手順をトリガーします。
クエリの改良と拡張: クエリは、クエリ改良エージェントによって改良され、セマンティック理解を活用して検索を最適化し、より良い結果を得ます。
外部ソースからの動的検索: コンテキストが不十分な場合、外部知識検索エージェントはWeb検索を実行するか、代替データソースにアクセスして、取得されたドキュメントを補足します。
応答合成: 検証および改良されたすべての情報は、最終的な応答生成のために応答合成エージェントに渡されます。
ワークフロー:
Corrective RAGシステムは、5つの主要なエージェントに基づいて構築されています。
コンテキスト検索エージェント: ベクトルデータベースから初期コンテキストドキュメントを取得する責任があります。
関連性評価エージェント: 取得されたドキュメントの関連性を評価し、関連性のない、またはあいまいなドキュメントに修正アクションのフラグを立てます。
クエリ改良エージェント: 検索を改善するためにクエリを書き直し、セマンティック理解を活用して結果を最適化します。
外部知識検索エージェント: コンテキストドキュメントが不十分な場合、Web検索を実行するか、代替データソースにアクセスします。
応答合成エージェント: 検証されたすべての情報を首尾一貫した正確な応答に合成します。
主な機能と利点:
反復修正: 関連性のない、またはあいまいな検索結果を動的に識別および修正することにより、高い応答精度を保証します。
動的適応性: リアルタイムのWeb検索とクエリの改良を組み込んで、検索精度を向上させます。
エージェントのモジュール性: 各エージェントは特殊なタスクを実行し、効率的かつスケーラブルな運用を保証します。
事実性の保証: 取得および生成されたすべてのコンテンツを検証することにより、Corrective RAGはハルシネーションまたは誤情報のリスクを最小限に抑えます。

クエリ戦略を動的に調整するAdaptive RAG 図15
Adaptive Retrieval-Augmented Generation (Adaptive RAG) は、受信クエリの複雑さに基づいてクエリ処理戦略を動的に調整することにより、大規模言語モデル (LLM) の柔軟性と効率性を向上させます。
分類子を使用してクエリの複雑さを評価し、単一ステップ検索から複数ステップ推論、または単純なクエリの場合は検索を完全にバイパスするなど、最適なアプローチを決定します。

Adaptive RAGの主要なアイデア:
Adaptive RAGの中核となる原則は、クエリの複雑さに基づいて検索戦略を動的に調整する能力にあります。Adaptive RAGは、次のようにアプローチを調整します。
単純なクエリ: 追加の検索を必要としない事実ベースの質問(例:「水の沸点は?」)の場合、システムは既存の知識を使用して直接回答を生成します。
簡単なクエリ: 最小限のコンテキストを必要とする中程度の複雑さのタスク(例:「最新の電気料金請求書のステータスは?」)の場合、システムは単一ステップ検索を実行して関連する詳細を取得します。
複雑なクエリ: 反復的な推論を必要とする複数層のクエリ(例:「過去10年間で都市Xの人口はどのように変化しましたか?また、その要因は何ですか?」)の場合、システムは複数ステップ検索を採用し、中間結果を段階的に絞り込んで包括的な回答を提供します。
ワークフロー:
Adaptive RAGシステムは、3つの主要コンポーネントに基づいて構築されています。
分類子の役割:
小規模な言語モデルがクエリを分析して、その複雑さを予測します。
分類子は、過去のモデルの結果とクエリパターンから導出された、自動的にラベル付けされたデータセットを使用してトレーニングされます。
動的戦略選択:
単純なクエリの場合、システムは不要な検索を回避し、LLMを直接活用して応答を生成します。
簡単なクエリの場合、単一ステップ検索プロセスを採用して関連するコンテキストを取得します。
複雑なクエリの場合、複数ステップ検索をアクティブ化して、反復的な改良と強化された推論を保証します。
LLM統合:
LLMは、取得された情報を首尾一貫した応答に合成します。
LLMと分類子間の反復的な相互作用により、複雑なクエリの改良が可能になります。
主な機能と利点
動的適応性: クエリの複雑さに基づいて検索戦略を調整し、計算効率と応答精度の両方を最適化します。
リソース効率: 複雑なクエリの徹底的な処理を保証しながら、単純なクエリの不要なオーバーヘッドを最小限に抑えます。
精度の向上: 反復的な改良により、複雑なクエリが高精度で解決されます。
柔軟性: ドメイン固有のツールや外部APIなど、追加のパスウェイを組み込むように拡張できます。

グラフベースのエージェントRAG 図16
グラフ知識ベースと非構造化ドキュメント検索を統合することで、従来のRAGシステムの推論能力と検索精度を向上させることができます。
Agent-Gは、このグラフベースRAGを実現するアーキテクチャであり、モジュール式レトリーバーバンク、動的なエージェントインタラクション、フィードバックループによって高品質の出力を保証します。
GeARのグラフ拡張モジュールの追加によって、グラフ構造データを利用した検索を可能にします。
Agent-GにGeARのグラフ拡張機能を統合することで、より高度な推論と、複雑なクエリへの対応を実現する、強力なグラフベースRAGシステムを構築できます。
Agent-Gの主要なアイデア:
Agent-Gの中核となる原則は、グラフ知識ベースとテキストドキュメントの両方を活用して、検索タスクを特殊化されたエージェントに動的に割り当てる機能にあります。

図16をベースとした、GeARによる拡張機能を含むグラフベースRAGの説明:
Agent-Gのアーキテクチャは、以下の主要コンポーネントで構成されます。
レトリーバーバンク: グラフベースデータと非構造化データそれぞれに特化した検索エージェントのモジュール群です。クエリに応じて、適切なエージェントが動的に選択され、データソースにアクセスします。
GeARのグラフ拡張モジュール(追加機能): このバンク内に、GeARのグラフ拡張モジュールを組み込みます。このモジュールは、ベースレトリーバー(例:BM25)を強化し、グラフ構造データを利用した検索を可能にします。これにより、エンティティ間の複雑な関係や依存性を考慮した検索が可能となり、マルチホップクエリへの対応力が向上します。(図17)
批評モジュール: 取得されたデータの関連性と品質を検証し、信頼度の低い結果にフラグを立てます。このフィードバックは、レトリーバーバンクの選択やクエリの改良に利用されます。
動的エージェントインタラクション: タスクに応じて、グラフベース検索エージェントと非構造化データ検索エージェントが連携し、多様なデータタイプの統合を図ります。それぞれのエージェントは、GeARのグラフ拡張モジュールからの情報も利用可能です。
LLM統合: 検証されたデータに基づき、LLMが首尾一貫した応答を生成します。批評モジュールからのフィードバックは、クエリの意図に沿った応答生成を促します。
GeARのグラフ拡張機能を統合したことで得られる利点:
マルチホップ質問への対応力向上: 関係性を辿ることで、直接的なキーワードマッチングでは得られない情報を取得可能になります。
検索精度の向上: グラフ構造に基づく関係性を利用することで、より関連性の高い情報を取得できます。
説明性の向上: 回答の根拠となる情報をグラフ構造で示すことで、ユーザーにとって理解しやすい説明が可能になります。


エンドツーエンドの知識作業の自動化 ADW 図18
Agentic Document Workflows (ADW)は、エンドツーエンドの知識作業の自動化を可能にすることで、従来のRetrieval-Augmented Generation (RAG) パラダイムを拡張します。
これらのワークフローは、ドキュメントの解析、取得、推論、および構造化出力をインテリジェントエージェントと統合し、複雑なドキュメント中心のプロセスを調整します。
ADWシステムは、状態の維持、マルチステップワークフローの調整、ドキュメントへのドメイン固有ロジックの適用によって、Intelligent Document Processing (IDP) およびRAGの制限に対処します。

ワークフロー
ドキュメント解析と情報構造化:
エンタープライズグレードのツール(例:LlamaParse)を使用してドキュメントを解析し、請求書番号、日付、ベンダー情報、明細項目、支払い条件などの関連データフィールドを抽出します。
構造化データは、ダウンストリーム処理のために整理されます。
プロセス全体の状態維持:
システムはドキュメントコンテキストに関する状態を維持し、マルチステップワークフロー全体の一貫性と関連性を確保します。
さまざまな処理段階を通してドキュメントの進行状況を追跡します。
知識の取得:
関連する参照は、外部知識ベース(例:LlamaCloud)またはベクトルインデックスから取得されます。
強化された意思決定のために、リアルタイムのドメイン固有のガイドラインを取得します。
エージェントによるオーケストレーション:
インテリジェントエージェントは、ビジネスルールを適用し、マルチホップ推論を実行し、実用的な推奨事項を生成します。
シームレスな統合のために、パーサー、レトリーバー、外部APIなどのコンポーネントを調整します。
実用的な出力生成:
出力は、特定のユースケースに合わせて調整された構造化形式で提示されます。
推奨事項と抽出された洞察は、簡潔で実用的なレポートに統合されます。
主な機能と利点
状態維持: ドキュメントコンテキストとワークフローステージを追跡し、プロセス全体の一貫性を確保します。
マルチステップオーケストレーション: 複数のコンポーネントと外部ツールを含む複雑なワークフローを処理します。
ドメイン固有のインテリジェンス: 正確な推奨事項のために、調整されたビジネスルールとガイドラインを適用します。
スケーラビリティ: モジュール式で動的なエージェント統合により、大規模なドキュメント処理をサポートします。
生産性の向上: 意思決定における人間の専門知識を強化しながら、反復的なタスクを自動化します。

比較分析 表2
従来のRAG、エージェントRAG、およびエージェントドキュメントワークフロー(ADW)の3つのアーキテクチャフレームワークの包括的な比較分析を提供しています。
比較分析は、従来のRAGからエージェントRAG、さらにエージェントドキュメントワークフロー(ADW)への進化の軌跡を明確に示しています。

RAGに評価に適したベンチマークデータセットの紹介
エージェントベースやグラフベースの機能強化を含む、Retrieval-Augmented Generation (RAG) システムの評価に役立つベンチマークとデータセットが提供されています。RAG専用に設計されたものもあれば、さまざまなシナリオでの検索、推論、および生成機能をテストするために採用されたものもあります。データセットは、RAGシステムの検索、推論、および生成コンポーネントをテストするために不可欠です。
BEIR (Benchmarking Information Retrieval): バイオインフォマティクス、金融、質問応答など、さまざまな分野にわたる17のデータセットを含む、多様な情報検索タスクで埋め込みモデルを評価するために設計された汎用性の高いベンチマーク[54]。
MS MARCO (Microsoft Machine Reading Comprehension): パッセージランキングと質問応答に焦点を当てたこのベンチマークは、RAGシステムでの密な検索タスクに広く使用されています[55]。
TREC (Text REtrieval Conference, Deep Learning Track): パッセージとドキュメントの検索のためのデータセットを提供し、検索パイプラインにおけるランキングモデルの品質を重視しています[56]。
MuSiQue (Multihop Sequential Questioning): 複数のドキュメントにわたるマルチホップ推論のベンチマークであり、接続されていないコンテキストから情報を検索および合成することの重要性を強調しています[57]。
2WikiMultihopQA: 2つのWikipedia記事に対するマルチホップQAタスク用に設計されたデータセットで、複数のソースにわたる知識を接続する機能に焦点を当てています[58]。
AgentG (Agentic RAG for Knowledge Fusion): エージェントRAGタスクに合わせて調整されたこのベンチマークは、複数の知識ベースにわたる動的な情報合成を評価します[8]。
HotpotQA: 相互接続されたコンテキストに対する検索と推論を必要とするマルチホップQAベンチマークであり、複雑なRAGワークフローの評価に最適です[59]。
RAGBench: 業界ドメイン全体で100,000の例を備えた、大規模で説明可能なベンチマークであり、実用的なRAGメトリクスのためのTRACe評価フレームワークを備えています[60]。
BERGEN (Benchmarking Retrieval-Augmented Generation): 標準化された実験を使用してRAGシステムを体系的にベンチマークするためのライブラリ[61]。
FlashRAG Toolkit: 12のRAGメソッドを実装し、効率的かつ標準化されたRAG評価をサポートするために32のベンチマークデータセットを含んでいます[62]。
GNN-RAG: このベンチマークは、ノードレベルおよびエッジレベルの予測などのタスクでグラフベースのRAGシステムを評価し、知識グラフ質問応答(KGQA)における検索品質と推論パフォーマンスに焦点を当てています[63]。

参考文献
私は、今回の論文は必要に応じて参考文献を孫引きする事がありそうなので、転記しておきます。
References
[1] Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and
Jianfeng Gao. Large language models: A survey, 2024.
[2] Aditi Singh. Exploring language models: A comprehensive survey and analysis. In 2023 International Con-
ference on Research Methodologies in Knowledge Management, Artifi cial Intelligence and Telecommunication
Engineering (RMKMATE), pages 1–4, 2023.
[3] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang,
Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren,
Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language
models, 2024.
[4] Sumit Kumar Dam, Choong Seon Hong, Yu Qiao, and Chaoning Zhang. A complete survey on llm-based ai
chatbots, 2024.
[5] Aditi Singh. A survey of ai text-to-image and ai text-to-video generators. In 2023 4th International Conference
on Artifi cial Intelligence, Robotics and Control (AIRC), pages 32–36, 2023.
[6] Aditi Singh, Abul Ehtesham, Gaurav Kumar Gupta, Nikhil Kumar Chatta, Saket Kumar, and Tala Talaei Khoei.
Exploring prompt engineering: A systematic review with swot analysis, 2024.
[7] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua
Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles,
taxonomy, challenges, and open questions. ACM Transactions on Information Systems, November 2024.
[8] Meng-Chieh Lee, Qi Zhu, Costas Mavromatis, Zhen Han, Soji Adeshina, Vassilis N. Ioannidis, Huzefa Rangwala,
and Christos Faloutsos. Agent-g: An agentic framework for graph retrieval augmented generation, 2024.
[9] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao
Zhang, Jie Jiang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey, 2024.
[10] Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan,
and Graham Neubig. Active retrieval augmented generation, 2023.
[11] Yikun Han, Chunjiang Liu, and Pengfei Wang. A comprehensive survey on vector database: Storage and retrieval
technique, challenge, 2023.
[12] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang,
Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based
autonomous agents. Frontiers of Computer Science, 18(6), March 2024.
[13] Aditi Singh, Saket Kumar, Abul Ehtesham, Tala Talaei Khoei, and Deepshikha Bhati. Large language model-
driven immersive agent. In 2024 IEEE World AI IoT Congress (AIIoT), pages 0619–0624, 2024.
[14] Matthew Renze and Erhan Guven. Self-refl ection in llm agents: Effects on problem-solving performance, 2024.
[15] Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang,
and Enhong Chen. Understanding the planning of llm agents: A survey, 2024.
[16] Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and
Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges, 2024.
[17] Chidaksh Ravuru, Sagar Srinivas Sakhinana, and Venkataramana Runkana. Agentic retrieval-augmented
generation for time series analysis, 2024.
[18] Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey, 2023.
[19] Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang.
Graph retrieval-augmented generation: A survey, 2024.
[20] Aditi Singh, Abul Ehtesham, Saifuddin Mahmud, and Jong-Hoon Kim. Revolutionizing mental health care
through langchain: A journey with a large language model. In 2024 IEEE 14th Annual Computing and
Communication Workshop and Conference (CCWC), pages 0073–0078, 2024.
[21] Gaurav Kumar Gupta, Aditi Singh, Sijo Valayakkad Manikandan, and Abul Ehtesham. Digital diagnostics: The
potential of large language models in recognizing symptoms of common illnesses, 2024.
[22] Aditi Singh, Abul Ehtesham, Saket Kumar, Gaurav Kumar Gupta, and Tala Talaei Khoei. Encouraging responsible
use of generative ai in education: A reward-based learning approach. In Tim Schlippe, Eric C. K. Cheng, and
Tianchong Wang, editors, Artifi cial Intelligence in Education Technologies: New Development and Innovative
Practices, pages 404–413, Singapore, 2025. Springer Nature Singapore.
[23] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and
Haofen Wang. Retrieval-augmented generation for large language models: A survey, 2024.
[24] Vladimir Karpukhin, Barlas O˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen
tau Yih. Dense passage retrieval for open-domain question answering, 2020.
[25] Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong
Wen. A survey on the memory mechanism of large language model based agents, 2024.
[26] Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large
language models can self-correct with tool-interactive critiquing, 2024.
[27] Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. Enhancing ai systems with agentic workfl ows
patterns in large language model. In 2024 IEEE World AI IoT Congress (AIIoT), pages 527–532, 2024.
[28] DeepLearning.AI. How agents can improve llm performance. https://www.deeplearning.ai/the-batch/
how-agents-can-improve-llm-performance/?ref=dl-staging-website.ghost.io, 2024. Ac-
cessed: 2025-01-13.
[29] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha
Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann,
Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refi ne: Iterative refi nement with self-feedback, 2023.
[30] Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao.
Refl exion: Language agents with verbal reinforcement learning, 2023.
[31] Weaviate Blog. What is agentic rag? https://weaviate.io/blog/what-is-agentic-rag#:~:text=is%
20Agentic%20RAG%3F-,%E2%80%8B,of%20the%20non%2Dagentic%20pipeline. Accessed: 2025-01-14.
[32] Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation, 2024.
[33] LangGraph CRAG Tutorial. Langgraph crag: Contextualized retrieval-augmented generation tutorial. https:
//langchain-ai.github.io/langgraph/tutorials/rag/langgraph_crag/. Accessed: 2025-01-14.
[34] Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C. Park. Adaptive-rag: Learning to adapt
retrieval-augmented large language models through question complexity, 2024.
[35] LangGraph Adaptive RAG Tutorial. Langgraph adaptive rag: Adaptive retrieval-augmented generation tu-
torial. https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_adaptive_rag/.
Accessed: 2025-01-14.
[36] Zhili Shen, Chenxin Diao, Pavlos Vougiouklis, Pascual Merita, Shriram Piramanayagam, Damien Graux, Dandan
Tu, Zeren Jiang, Ruofei Lai, Yang Ren, and Jeff Z. Pan. Gear: Graph-enhanced agent for retrieval-augmented
generation, 2024.
[37] LlamaIndex. Introducing agentic document workfl ows. https://www.llamaindex.ai/blog/
introducing-agentic-document-workflows, 2025. Accessed: 2025-01-13.
[38] AWS Machine Learning Blog. How twitch used agentic workfl ow with rag on amazon
bedrock to supercharge ad sales. https://aws.amazon.com/blogs/machine-learning/
how-twitch-used-agentic-workflow-with-rag-on-amazon-bedrock-to-supercharge-ad-sales/,
2025. Accessed: 2025-01-13.
[39] LlamaCloud Demo Repository. Patient case summary workfl ow using llamacloud. https:
//github.com/run-llama/llamacloud-demo/blob/main/examples/document_workflows/
patient_case_summary/patient_case_summary.ipynb, 2025. Accessed: 2025-01-13.
[40] LlamaCloud Demo Repository. Contract review workfl ow using llamacloud. https://github.com/
run-llama/llamacloud-demo/blob/main/examples/document_workflows/contract_review/
contract_review.ipynb, 2025. Accessed: 2025-01-13.
[41] LlamaCloud Demo Repository. Auto insurance claims workfl ow using llamacloud. https:
//github.com/run-llama/llamacloud-demo/blob/main/examples/document_workflows/auto_
insurance_claims/auto_insurance_claims.ipynb, 2025. Accessed: 2025-01-13.
[42] LlamaCloud Demo Repository. Research paper report generation workfl ow using llamacloud.
https://github.com/run-llama/llamacloud-demo/blob/main/examples/report_generation/
research_paper_report_generation.ipynb, 2025. Accessed: 2025-01-13.
[43] LangGraph Agentic RAG Tutorial. Langgraph agentic rag: Nodes and edges tutorial. https://langchain-ai.
github.io/langgraph/tutorials/rag/langgraph_agentic_rag/#nodes-and-edges. Accessed:
2025-01-14.
[44] LlamaIndex Blog. Agentic rag with llamaindex. https://www.llamaindex.ai/blog/
agentic-rag-with-llamaindex-2721b8a49ff6. Accessed: 2025-01-14.
[45] Hugging Face Cookbook. Agentic rag: Turbocharge your retrieval-augmented generation with query reformula-
tion and self-query. https://huggingface.co/learn/cookbook/en/agent_rag. Accessed: 2025-01-14.
[46] Qdrant Blog. Agentic rag: Combining rag with agents for enhanced information retrieval. https://qdrant.
tech/articles/agentic-rag/. Accessed: 2025-01-14.
[47] crewAI Inc. crewai: A github repository for ai projects. https://github.com/crewAIInc/crewAI, 2025.
Accessed: 2025-01-15.
[48] AG2AI Contributors. Ag2: A github repository for advanced generative ai research. https://github.com/
ag2ai/ag2, 2025. Accessed: 2025-01-15.
[49] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun
Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Autogen: Enabling
next-gen llm applications via multi-agent conversation framework. 2023.
[50] Shaokun Zhang, Jieyu Zhang, Jiale Liu, Linxin Song, Chi Wang, Ranjay Krishna, and Qingyun Wu. Training
language model agents without modifying language models. ICML’24, 2024.
[51] OpenAI. Swarm: Lightweight multi-agent orchestration framework. https://github.com/openai/swarm.
Accessed: 2025-01-14.
[52] LlamaIndex Documentation. Agentic rag using vertex ai. https://docs.llamaindex.ai/en/stable/
examples/agent/agentic_rag_using_vertex_ai/. Accessed: 2025-01-14.
[53] IBM Granite Community. Agentic rag: Ai agents with ibm granite models. https://github.com/
ibm-granite-community/granite-snack-cookbook/blob/main/recipes/AI-Agents/Agentic_
RAG.ipynb. Accessed: 2025-01-14.
[54] Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous
benchmark for zero-shot evaluation of information retrieval models, 2021.
[55] Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew
McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong
Wang. Ms marco: A human generated machine reading comprehension dataset, 2018.
[56] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, Jimmy Lin, Ellen M. Voorhees, and Ian Soboroff.
Overview of the trec 2022 deep learning track. In Text REtrieval Conference (TREC). NIST, TREC, March 2023.
[57] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions
via single-hop question composition, 2022.
[58] Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset
for comprehensive evaluation of reasoning steps, 2020.
[59] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christo-
pher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering, 2018.
[60] Robert Friel, Masha Belyi, and Atindriyo Sanyal. Ragbench: Explainable benchmark for retrieval-augmented
generation systems, 2024.
[61] David Rau, Hervé Déjean, Nadezhda Chirkova, Thibault Formal, Shuai Wang, Vassilina Nikoulina, and Stéphane
Clinchant. Bergen: A benchmarking library for retrieval-augmented generation, 2024.
[62] Jiajie Jin, Yutao Zhu, Xinyu Yang, Chenghao Zhang, and Zhicheng Dou. Flashrag: A modular toolkit for effi cient
retrieval-augmented generation research, 2024.
[63] Costas Mavromatis and George Karypis. Gnn-rag: Graph neural retrieval for large language model reasoning,
2024.
[64] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfi eld, Michael Collins, Ankur Parikh, Chris Alberti, Danielle
Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei
Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question
answering research. Transactions of the Association for Computational Linguistics, 7:452–466, 2019.
[65] Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised
challenge dataset for reading comprehension, 2017.
[66] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine
comprehension of text, 2016.
[67] Jonathan Berant, Andrew K. Chou, Roy Frostig, and Percy Liang. Semantic parsing on freebase from question-
answer pairs. In Conference on Empirical Methods in Natural Language Processing, 2013.
[68] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to
trust language models: Investigating effectiveness of parametric and non-parametric memories. In Anna Rogers,
Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada, July 2023. Association
for Computational Linguistics.
[69] Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. Eli5: Long form
question answering, 2019.
[70] Tomáš Koˇciský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward
Grefenstette. The narrativeqa reading comprehension challenge. 2017.
[71] Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. Asqa: Factoid questions meet long-form
answers, 2023.
[72] Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli
Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir Radev. QMSum: A new benchmark for query-based
multi-domain meeting summarization. pages 5905–5921, June 2021.
[73] Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-
seeking questions and answers anchored in research papers. In Kristina Toutanova, Anna Rumshisky, Luke
Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao
Zhou, editors, Proceedings of the 2021 Conference of the North American Chapter of the Association for
Computational Linguistics: Human Language Technologies, pages 4599–4610, Online, June 2021. Association
for Computational Linguistics.
[74] Timo Möller, Anthony Reina, Raghavan Jayakumar, and Malte Pietsch. COVID-QA: A question answering
dataset for COVID-19. In ACL 2020 Workshop on Natural Language Processing for COVID-19 (NLP-COVID),
2020.
[75] Xidong Wang, Guiming Hardy Chen, Dingjie Song, Zhiyi Zhang, Zhihong Chen, Qingying Xiao, Feng Jiang,
Jianquan Li, Xiang Wan, Benyou Wang, and Haizhou Li. Cmb: A comprehensive medical benchmark in chinese,
2024.
[76] Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh
Padmakumar, Johnny Ma, Jana Thompson, He He, and Samuel R. Bowman. Quality: Question answering with
long input texts, yes!, 2022.
[77] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering
challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational
Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis,
Minnesota, June 2019. Association for Computational Linguistics.
[78] Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan
Hooi. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering,
2024.
[79] Sha Li, Heng Ji, and Jiawei Han. Document-level event argument extraction by conditional generation, 2021.
[80] Seth Ebner, Patrick Xia, Ryan Culkin, Kyle Rawlins, and Benjamin Van Durme. Multi-sentence argument
linking, 2020.
[81] Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli, and Jason Weston. Wizard of wikipedia:
Knowledge-powered conversational agents, 2019.
[82] Hongru Wang, Minda Hu, Yang Deng, Rui Wang, Fei Mi, Weichao Wang, Yasheng Wang, Wai-Chung Kwan,
Irwin King, and Kam-Fai Wong. Large language models as source planner for personalized knowledge-grounded
dialogue, 2023.
[83] Xinchao Xu, Zhibin Gou, Wenquan Wu, Zheng-Yu Niu, Hua Wu, Haifeng Wang, and Shihang Wang. Long time
no see! open-domain conversation with long-term persona memory, 2022.
[84] Tsung-Hsien Wen, Milica Gaši´c, Nikola Mrkši´c, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, David
Vandyke, and Steve Young. Conditional generation and snapshot learning in neural dialogue systems. In
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2153–2162,
Austin, Texas, November 2016. Association for Computational Linguistics.
[85] Ruining He and Julian McAuley. Ups and downs: Modeling the visual evolution of fashion trends with one-class
collaborative fi ltering. In Proceedings of the 25th International Conference on World Wide Web, WWW ’16, page
507–517, Republic and Canton of Geneva, CHE, 2016. International World Wide Web Conferences Steering
Committee.
[86] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really
fi nish your sentence? In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th
Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019.
Association for Computational Linguistics.
[87] Seungone Kim, Se June Joo, Doyoung Kim, Joel Jang, Seonghyeon Ye, Jamin Shin, and Minjoon Seo. The
cot collection: Improving zero-shot and few-shot learning of language models via chain-of-thought fi ne-tuning,
2023.
[88] Amrita Saha, Vardaan Pahuja, Mitesh M. Khapra, Karthik Sankaranarayanan, and Sarath Chandar. Complex
sequential question answering: Towards learning to converse over linked question answer pairs with a knowledge
graph. 2018.
[89] James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for
fact extraction and VERifi cation. In Marilyn Walker, Heng Ji, and Amanda Stent, editors, Proceedings of the 2018
Conference of the North American Chapter of the Association for Computational Linguistics: Human Language
Technologies, Volume 1 (Long Papers), pages 809–819, New Orleans, Louisiana, June 2018. Association for
Computational Linguistics.
[90] Neema Kotonya and Francesca Toni. Explainable automated fact-checking for public health claims, 2020.
[91] Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop?
a question answering benchmark with implicit reasoning strategies, 2021.
[92] Hiroaki Hayashi, Prashant Budania, Peng Wang, Chris Ackerson, Raj Neervannan, and Graham Neubig. Wikiasp:
A dataset for multi-domain aspect-based summarization, 2020.
[93] Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware
convolutional neural networks for extreme summarization, 2018.
[94] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher
Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In David Yarowsky,
Timothy Baldwin, Anna Korhonen, Karen Livescu, and Steven Bethard, editors, Proceedings of the 2013
Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington,
USA, October 2013. Association for Computational Linguistics.
[95] Sourav Saha, Jahedul Alam Junaed, Maryam Saleki, Arnab Sen Sharma, Mohammad Rashidujjaman Rifat,
Mohamed Rahouti, Syed Ishtiaque Ahmed, Nabeel Mohammed, and Mohammad Ruhul Amin. Vio-lens: A novel
dataset of annotated social network posts leading to different forms of communal violence and its evaluation. In
Firoj Alam, Sudipta Kar, Shammur Absar Chowdhury, Farig Sadeque, and Ruhul Amin, editors, Proceedings
of the First Workshop on Bangla Language Processing (BLP-2023), pages 72–84, Singapore, December 2023.
Association for Computational Linguistics.
[96] Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. Codesearchnet
challenge: Evaluating the state of semantic code search, 2020.
[97] Nandan Thakur, Luiz Bonifacio, Xinyu Zhang, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo,
Xiaoguang Li, Qun Liu, Boxing Chen, Mehdi Rezagholizadeh, and Jimmy Lin. "knowing when you don’t know":
A multilingual relevance assessment dataset for robust retrieval-augmented generation, 2024.
[98] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016.
[99] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert,
Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifi ers to
solve math word problems, 2021.
[100] Ralf Steinberger, Bruno Pouliquen, Anna Widiger, Camelia Ignat, Tomaž Erjavec, Dan Tufi ¸s, and Dániel Varga.
The JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages. In Nicoletta Calzolari, Khalid
Choukri, Aldo Gangemi, Bente Maegaard, Joseph Mariani, Jan Odijk, and Daniel Tapias, editors, Proceedings of
the Fifth International Conference on Language Resources and Evaluation (LREC‘06), Genoa, Italy, May 2006.
European Language Resources Association (ELRA).
#RAG #RetrievalAugmentedGeneration #LLM #大規模言語モデル #AdaptiveRAG #AgentG #GeAR #GraphRAG #グラフベースRAG #KnowledgeGraph #知識グラフ #DocumentWorkflow #ADW #AgenticDocumentWorkflows #InformationRetrieval #情報検索 #MultihopQA #MultihopReasoning #マルHop推論 #BM25 #LlamaParse #LlamaCloud #BEIR #MSMARCO #TREC #MuSiQue #2WikiMultihopQA #HotpotQA #RAGBench #BERGEN #FlashRAG #GNNRAG #KGQA #KnowledgeGraphQuestionAnswering