
CoRAG:多段階質問応答において大幅な性能向上

こんにちはmakokonです。今日はCoRAG(Chain-of-Retrieval Augmented Generation)と呼ばれる新しいRAGモデルを紹介します。
特に多段階質問応答に対する性能向上に大きな期待をしています。
論文では、「ダークハザードのスターはどこで勉強しましたか?」という事例がありますが、これを1回のRAGでスターは誰で、どこで勉強したかなど2つ以上の連続した質問に答えるのはとても難しい。この論文はこの問題に対する一つの回答であると思います。
論文では、以下のようにまとめています。
CoRAGは柔軟なフレームワークであり、様々な状況に適応できる可能性を示しています。特に、質問の複雑さやリトリーバーの品質に応じて戦略を調整することが重要であることが示唆されました。CoRAGは、事実に基づいた信頼性の高いAIシステムを構築するための有望なアプローチです.

概要
複雑な質問に段階的に対応できる、CoRAG(Chain-of-Retrieval Augmented Generation)
従来のRAGモデルが一度の検索しか行わない
CoRAGは動的にクエリを再構築
複数ステップの検索と推論を可能
多段階質問応答において大幅な性能向上
既存のデータセットを拡張することで、効果的な学習を実現
性能と計算コストのバランスを取れることを実証
KILTベンチマークにおいて最先端の性能を達成
Introduction (はじめに) 多段階検索の必要性とは
RAGは事実に基づいた応答を生成するための重要な技術ですが、従来のRAGには複雑なクエリに対応できないという課題があります。この課題を解決するために、多段階検索と推論を行う能力が不可欠であり、この論文では、そのためのCoRAGというフレームワークが提案されています。
RAGの重要性
RAGは、大規模な基盤モデル(LLM) と 独自のデータソース を統合し、事実に基づいた信頼性の高い応答 を生成するために不可欠な技術である。
LLMは、膨大なデータで訓練されているにもかかわらず、長尾の事実知識を記憶するのが苦手であり、誤った情報を生成する(ハルシネーション)可能性がある。RAGは、検索された情報を利用して応答を補強することで、この課題を軽減する。
RAGは、最新の情報を取り込むことを可能にするため、リアルタイムデータに基づいた応答が求められる場合に重要である。
長尾の事実知識とは
最近LLMの分野では、その限界を示す文脈で使われるようになっている言葉です。その主な特徴は
希少性、特異性、網羅性の困難さ、動的変化にあり、LLMのベース学習では押さえることが困難な知識分野です。
従来のRAGの課題
検索と生成を1回ずつ行うパイプラインを採用しており、検索された情報の品質に大きく依存
複雑なクエリの場合、一度の検索では必要な情報をすべて取得できない
多段階の推論を必要とする質問では、最初に何を検索すべきか不明確
推論プロセスの進展に伴って検索を動的に行う必要がある
検索モデルは、効率性を優先して設計
複雑なクエリに対応するための表現能力が限られている。
例えば、固定サイズのベクトル表現を使用する密なリトリーバーは、高速な近似最近傍探索を可能にする一方で、複雑なクエリを処理する能力を制限する。
多段階検索の必要性
約すると、RAGは事実に基づいた応答を生成するための重要な技術ですが、従来のRAGには複
従来のRAGの課題を克服するために、検索ステップを動的に計画し、現在の状態に基づいて次の検索ステップを決定するフレームワークが必要である。
複数の検索ステップを踏むことで、モデルはクエリの様々な側面を探索し、検索結果が役立たない場合には、異なるクエリの書き換え戦略を試すことができる。
このパラダイムは、人間が複雑な問題に取り組む際に、反復的に情報を探すプロセスを模倣している。
モデルのインコンテキスト学習能力や、プロプライエタリモデルからの蒸留に頼るのではなく、言語モデルを段階的に検索するように明示的に訓練することが重要である。
リジェクションサンプリングを用いて、中間的な検索連鎖を自動的に生成し、既存のRAGデータセットを拡張することが有効である。
Related Work (関連研究) 本研究に向けて
従来のRAG研究で課題となっていた、検索品質のボトルネックを解消し、よりロバストで信頼性の高いRAGシステムを構築することを目指し、既存のRAGの課題を克服し、より複雑なクエリに対応できるように、LLMを明示的に訓練し、検索プロセスを柔軟に制御するための新しいフレームワーク、CoRAGを提案しています。
従来研究の主なレビュー
Retrieval-Augmented Generation (RAG):
RAGは、情報検索技術と生成モデルを統合し、生成されたコンテンツの品質と事実の正確性を向上させる技術。
LLMがWebを閲覧する能力を持つことで、RAGシステムはリアルタイムデータにアクセスでき、最新の情報に基づいた回答可能
検索された情報の関連性と品質が、RAGシステムの有効性の鍵
汎用的なテキスト埋め込みに関する開発する研究が盛ん
テキスト埋め込みは固定サイズのベクトル表現を使用
複雑なクエリに対応するのが難しいという制約
Multi-step iterative retrieval and generation (多段階反復検索と生成):
単一検索ステップと生成のパラダイムを拡張し、複数ステップの反復的な検索と生成を行う
FLARE は、LLMが生成プロセス中にいつ、何を検索するかを積極的に決定するよう促す。
ITER-RETGEN は、検索拡張生成と生成拡張検索を交互に行うことで、多段階QAタスクにおける性能向上を示す。
IRCoT は、連鎖思考(chain-of-thought)の手法を用いて、後続の検索ステップのために推論を再帰的に洗練
Self-RAG は、LLMが自己反省を通じて適応的に検索、生成、批判を行うことで、オープンなドメインのQAタスクや長文生成タスクにおける事実の正確性と引用精度を向上させます。
Auto-RAG は、ヒューリスティックルールと正確な回答マッチングを利用して中間的な検索ステップを構築しますが、その性能は最先端のモデルに比べて大幅に劣ります。
本研究へのつながり
この論文で提案するCoRAG(Chain-of-Retrieval Augmented Generation)は、これらの関連研究を基盤としつつ、以下の点で独自性を打ち出しています。
明示的な学習: 従来のfew-shotプロンプティングやプロプライエタリモデルからの蒸留ではなく、LLMを段階的に検索と推論を行うように明示的に訓練します。
リジェクションサンプリング: 既存のRAGデータセットを、中間的な検索連鎖で拡張するために、リジェクションサンプリング を使用します。これにより、多段階の検索を学習するためのデータセットを自動的に生成できます。
テスト時の計算量スケーリング: テスト時に複数のデコーディング戦略(greedy decoding, best-of-N sampling, tree search)を用いて、計算量と性能のトレードオフを調整する方法を提案しています。
多段階推論への対応: 従来のRAGシステムが苦手とする多段階推論を必要とする質問に対して、クエリを分解し、必要に応じてリライトすることで、より正確な回答を生成することを目指します。
CoRAGの手法の定性的な説明
CoRAGの全体像
CoRAG(Chain-of-Retrieval Augmented Generation)は、複雑な質問に対して、複数回の検索と推論を繰り返すことで回答精度を高めるためのフレームワークです。従来のRAGが1回の検索で得られた情報に基づいて回答を生成するのに対し、CoRAGは質問を段階的に分解し、各段階で適切な情報を検索することで、より深い推論を可能にします。
CoRAGは、リジェクションサンプリングで中間的な検索連鎖を生成し、そのデータでLLMを訓練することで、複雑な質問に対して多段階の検索と推論を可能にするフレームワークです。このフレームワークは、データ生成、モデル訓練、推論の3つの段階から構成され、それぞれが密接に関連しています。

図1: CoRAGの概要:CoRAGのフレームワーク全体を示しています。この図から、CoRAGが以下の3つの主要な段階で構成されていることがわかります。
リジェクションサンプリングによる検索連鎖生成 (Rejection Sampling):
既存のQAデータセットには、質問と最終的な回答のみが含まれています。CoRAGでは、このデータセットを拡張するために、リジェクションサンプリングを用いて中間的な検索ステップ(サブクエリとサブアンサーの連鎖)を自動的に生成します。
LLM を使用して、元の質問と、それまでのサブクエリとサブアンサーに基づいて、新しいサブクエリを生成します。
生成されたサブクエリを用いて、テキストリトリーバーで関連文書を検索し、その文書に基づいてLLMでサブアンサーを生成します。
このプロセスを、事前に定めた最大連鎖長に達するか、サブアンサーが最終的な正解と一致するまで繰り返します。
連鎖の品質は、最終的な正解の条件付き対数尤度によって評価され、最も高いスコアの連鎖が選択されます。
拡張データセットを用いたモデル学習 (Training):
リジェクションサンプリングで生成された検索連鎖を用いて、LLMをファインチューニングします。
学習データは、質問、最終回答、サブクエリ連鎖、サブアンサー連鎖、そして各クエリに対応する上位k個の検索文書で構成されます。
LLMは、次のサブクエリの予測、サブアンサーの予測、最終回答の予測の3つのタスクで同時に訓練されます。
各タスクは、同じプロンプトテンプレートを使用して学習されます。
テスト時の計算量スケーリング (Inference):
学習済みのCoRAGモデルを用いて、様々なデコーディング戦略(greedy decoding, best-of-N sampling, tree search)で回答を生成します。
Greedy Decoding は、サブクエリとサブアンサーを順番に生成し、最終的な回答を生成します。
Best-of-N Sampling は、N個の検索連鎖をサンプリングし、最もペナルティスコアが低い連鎖を選択して最終回答を生成します。ペナルティスコアは、「関連情報が見つかりませんでした」という回答の条件付き対数尤度を基に計算します。
Tree Search は、**幅優先探索(BFS)**を用いて、検索連鎖の候補を探索し、最も平均ペナルティスコアが低い状態を保持します。
これらのデコーディング戦略と、検索連鎖の最大長L、サンプリング数Nなどのハイパーパラメータを調整することで、テスト時の計算量とモデルの性能のトレードオフを制御できます。
CoRAGの定性的な説明
CoRAGは、複雑な質問を解決するために、人間が情報を段階的に収集し、推論を深めていくプロセスを模倣しています。
従来のRAGが、質問に対して1回だけ情報を検索して回答するのに対し、CoRAGは質問をより小さなサブクエリに分割し、各サブクエリに対して必要な情報を検索することで、より正確で信頼性の高い回答を生成します。

例えば、図(b) に示されている例では、「Dark Hazardのスターはどこで勉強しましたか?」という質問に対して、CoRAGは以下のように段階的に処理します。
「Dark Hazardのスターの名前は何でしたか?」と分解し、回答「Edward G. Robinson」を得ます。
「Edward G. Robinsonはどこの大学に行きましたか?」と質問を書き換えます。
「Edward G. Robinsonはどこの大学に行きましたか?」に対する回答として「関連情報が見つかりませんでした」と判断し、
「Edward G. Robinsonが通った大学は何ですか?」と質問を再度書き換え、回答「City College of New York」を得ます。
最終的に、「City College of New York」が回答となります。
この例からもわかるように、CoRAGは、検索結果が不十分な場合、質問を動的に変更することで、より適切な情報を取得することができます。
CoRAGの利点
複雑なクエリへの対応: 複数の検索ステップを踏むことで、多段階の推論が必要な質問にも対応できます。
検索品質の向上: サブクエリを生成することで、元の質問よりも具体的な情報を検索できます。
柔軟なクエリ書き換え: 検索結果に基づいて質問を動的に書き換えることで、検索の失敗を減らすことができます。
テスト時の計算量調整: デコーディング戦略やハイパーパラメータを調整することで、計算量と性能のトレードオフを柔軟に制御できます。
評価実験
ここでは、CoRAGの評価結果について、説明します。
実験結果から、CoRAGは、複雑な質問応答タスクや多様な知識集約型タスクにおいて、非常に有効な手法であると言えます。また、テスト時の計算量を調整することで、様々なニーズに対応できる柔軟性も持ち合わせていることが示されました。
評価実験手法
実験は、主に以下の2つの観点から行われました。
マルチホップQAタスク: 複数のステップを必要とする複雑な質問応答タスクにおけるCoRAGの性能評価
KILTベンチマーク: より多様な知識集約型タスクにおけるCoRAGの汎化性能評価
実験設定
データセット:
マルチホップQAデータセット: 2WikiMultihopQA, HotpotQA, Bamboogle, MuSiQue を使用し、多段階の推論能力を評価。
KILTベンチマーク: 幅広い知識集約型タスクを網羅し、モデルの汎化能力を評価。
モデル:
Llama-3.1-8B-Instruct をベースモデルとして使用し、リジェクションサンプリングで生成したデータでファインチューニング。
E5-large をテキストリトリーバーとして使用。
KILTベンチマークでは、E5-Mistral リトリーバーと RankLLaMA リランカーをファインチューニングして使用。
評価指標:
マルチホップQAタスクでは、Exact Match (EM) スコアと F1スコア を使用。
KILTベンチマークでは、公式の評価サーバーに予測を提出し、タスク固有の評価指標を使用。
主な結果
表1, 2: CoRAGが、様々なタスクにおいて、他の既存モデルを上回るか、それに匹敵する性能を達成したことを示しています。
図2: テスト時の計算量と性能の関係を示しており、計算量を増やせば性能が向上する傾向がある一方で、限界があることを示唆しています。
CoRAGは、多段階の推論を必要とする複雑な質問応答タスクにおいて、高い性能を発揮しました。
CoRAGは、多様な知識集約型タスクに対しても高い汎化能力を持つことが示されました。
テスト時の計算量を調整することで、性能と計算コストのバランスを取ることが可能であることが示されました。
検索連鎖の長さやサンプリング数を増やすことで、性能が向上する傾向があることを示されました。
これらの実験結果は、CoRAGが従来のRAGシステムと比較して、より高度な質問応答タスクに対応できる可能性を示唆しています。


マルチホップQA
表1: 既存のモデル(few-shot Llama-3.1-8B-Instruct, GPT-4o, Self-RAG-7B, ITER-RETGEN, DRAG, IterDRAG, Search-o1-32B)と CoRAG-8B の性能を比較。
CoRAG-8B は、ほとんどのデータセットで他のベースラインモデルを大幅に上回る性能を示しました。特に、多段階の推論が必要なタスクにおいて、その効果が顕著でした。
検索連鎖の活用が、CoRAG-8B の性能向上に大きく貢献していることが示唆されました。
KILTベンチマーク
表2: KILTベンチマークにおける既存の強力なシステム(KILT-RAG, SEAL, Atlas-11B, RA-DIT 65B, FiD with RS)と CoRAG-8B の性能を比較。
CoRAG-8B は、ほとんどすべてのタスクにおいて、既存のモデルを上回る最高性能を達成しました。
この結果は、CoRAGが多様な知識集約型タスクに対して高い汎化能力を持つことを示しています。
FEVERタスクでは、より大規模なモデルにわずかに及ばなかったものの、全体として優れた性能を示しました。

テスト時の計算量スケーリング
図2: 複数ホップQAデータセットにおける、テスト時の計算量とモデル性能の関係を評価。
検索連鎖の長さLを長くすると、性能が向上する傾向が見られました。特に、Lが小さいときには顕著な性能向上が見られました。これは、より長い連鎖がより多くの推論ステップと、さまざまなクエリ書き換え戦略の試行を可能にすることを示唆しています。
Best-of-Nサンプリングにおいて、サンプリング数Nを増やすことは、データセットによって効果が異なりました。難しいデータセット(MuSiQue)ではNを増やすと性能が向上しましたが、比較的簡単なデータセット(2WikiMultihopQA)では、少ないNでも十分な性能が得られました。
これらの結果から、質問の複雑さや検索品質に応じてテスト時の計算量を調整することが有効であることが示唆されました。
平均トークン消費量と**モデル性能(EMスコア)**の関係は、ログ線形に近い関係にあることが示されました。これは、実務者が、要求される品質に基づいてテスト時の計算量を決定する際に役立つ可能性があります。
様々なデコーディング戦略とハイパーパラメータを調整することで、計算量と性能のトレードオフを制御できることを示唆しました。
分析(考察)
ここでの分析結果から、CoRAGは柔軟なアプローチであり、様々な状況に適応できる可能性があることが示唆されました。 特に、質問の複雑さやリトリーバーの品質に応じて戦略を調整する必要があるという重要な示唆が得られました。
具体的には、以下の内容を示しています。
CoRAGの自己改善効果は限定的であることが示唆されました。
CoRAGは、リトリーバーの性能に依存するものの、弱いリトリーバーでも計算量を増やせば一定の性能が得られることが示されました。
弱教師ありLLMでも、ある程度の性能を持つCoRAGを学習可能であることが示されました。
検索連鎖は、複雑な質問に対して有効であることが改めて示されました。
早期停止は、性能と計算コストのトレードオフとなることが示唆されました。
分析手法
CoRAGの性能をさらに深く理解するために、様々な角度からの分析が行われています。具体的には、以下の点に着目して分析が行われています。
反復リジェクションサンプリングの効果: CoRAGモデルをデータ生成に再利用することによる自己改善効果の検証
異なるリトリーバーの利用: テスト時に異なるリトリーバーを使用した場合のCoRAGのロバスト性評価
弱教師あり学習からの汎化: 弱教師ありLLMで生成したデータで学習させたCoRAGモデルの性能評価
検索連鎖の有効性: 検索連鎖が常に有効であるとは限らないケースの分析
テスト時における早期停止: テスト時に早期に停止するモデルの性能と計算コストの評価
反復リジェクションサンプリング
既存の命令調整済みLLMはすでに高品質な検索連鎖を生成する能力が高いことが示唆されました。つまり、CoRAGモデルを再利用しても、大幅な性能向上は期待できないと考えられます。

反復学習の効果が限定的であること、異なるリトリーバーを使用した場合の性能変化、弱教師あり学習の可能性など、様々な角度からCoRAGの性能を分析した結果が示されています。
表3: 学習済みのCoRAGモデルを新たな検索連鎖生成に再利用した結果が示されています。
2WikiMultihopQAデータセットでは性能が向上しましたが、他のデータセットではわずかな低下が見られました。
ロバスト性と汎化性能
リトリーバーの性能向上は、CoRAGの性能をさらに向上させる可能性があり、弱いLLMを利用することで、データ生成のコストを下げる可能性があることを指摘しています。(表3)
異なるリトリーバー:
表3: テスト時に異なるリトリーバー(E5-base, BM25)を使用した結果が示されています。
弱いリトリーバーを使用した場合でも、テスト時の計算量を増やすことで性能が向上することが確認されました。
ただし、より強力なリトリーバー(E5-large)を使用した方が、絶対的な性能は高かったです。これは、リトリーバーの品質がCoRAGの性能に大きく影響することを示唆しています。
弱教師あり学習からの汎化:
表3: 弱いLLM(Llama-3.2-1B-Inst, Llama-3.2-3B-Inst)で生成した検索連鎖を用いてCoRAGを学習させた結果が示されています。
Llama-3Bを使用した場合は、8Bモデルと比較して非常に近い性能が得られました。
Llama-1Bを使用した場合は、性能が低下しました。これは、1Bモデルが与えられた指示に従うのが難しいことを示唆しています。
検索連鎖は常に役立つか?
質問の複雑さに応じてデコーディング戦略を適応させる必要性が示唆されました。複雑な質問には、多段階の検索連鎖が有効ですが、単純な質問には、単一の検索で十分であることが示唆されました。
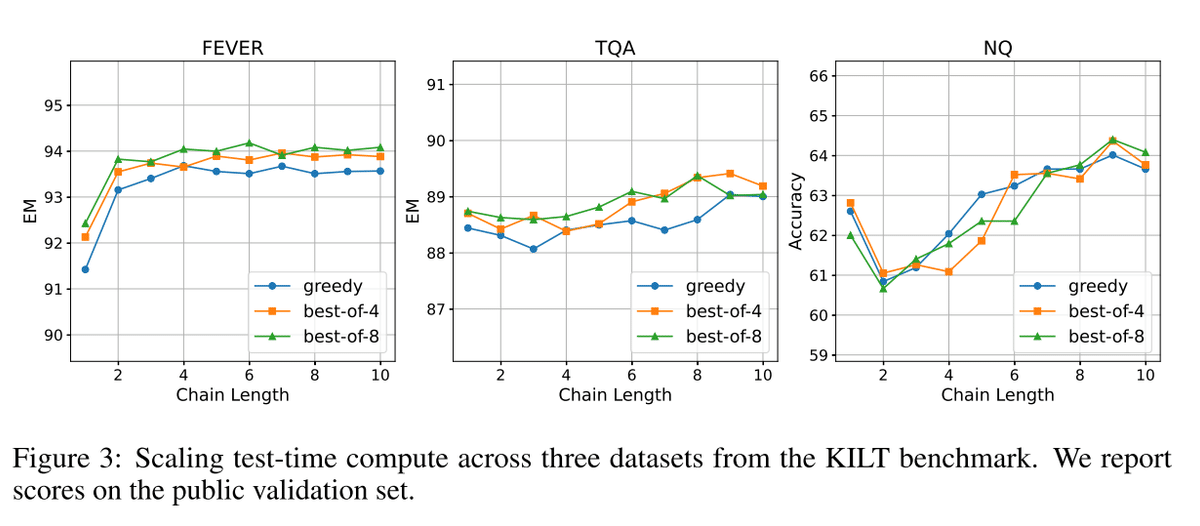
タスクの性質によって、検索連鎖の有効性が異なることを示しています。
図3: KILTベンチマークの3つのデータセット(FEVER, TQA, NQ)におけるテスト時の計算量と性能の関係が示されています。
**多段階推論を必要とするタスク(多ホップQAデータセット)**では、検索連鎖が有効に働くことが示されています(4章参照)。
一方、単一の検索ステップで十分なタスクでは、検索連鎖の利点は小さいことが示されました。特に、NQのようなデータセットでは、その傾向が顕著でした。
テスト時における早期停止
最適な構成は、データセットの特性や期待される品質によって異なることが示唆されました。

図4: MuSiQueデータセットにおいて、早期停止のlogitバイアス値を調整した場合の、性能とトークン消費量の関係が示されています。
早期停止を行うことでトークン消費量を削減できる一方で、性能が低下することが示されました。
この論文の成果
CoRAGは柔軟なフレームワークであり、様々な状況に適応できる可能性を示しています。特に、質問の複雑さやリトリーバーの品質に応じて戦略を調整することが重要であることが示唆されました。CoRAGは、事実に基づいた信頼性の高いAIシステムを構築するための有望なアプローチです.
具体的な成果は、以下のようにまとめられます。
この論文では、複雑な質問に答えるために、LLMに反復的な検索と推論を学習させる CoRAG (Chain-of-Retrieval Augmented Generation) というフレームワークが提案されました。
CoRAGは、リジェクションサンプリングによって中間的な検索連鎖を自動的に生成することで、手動アノテーションの必要性を軽減しています。
CoRAGモデルは、複数のデコーディング戦略を提供しており、性能と計算コストのバランスを管理することができます。
また、実験結果では、以下の点が示されました。
CoRAG-8Bモデルは、多段階のQAデータセットとKILTベンチマークの両方で、最先端の性能を達成しました。これは、より大規模なLLMで構築された多くのベースラインを上回っています。
CoRAGは、複雑な質問をより単純なサブクエリに分解し、検索された情報が役に立たない場合には動的にクエリを再構成することができます。
CoRAGのテスト時の計算量を調整することで、性能を向上させることが可能です。
リトリーバーの品質はCoRAGの性能に影響を与えますが、弱いリトリーバーでも計算量を増やすことで一定の性能が得られます。
弱教師ありのLLMを使用しても、ある程度の性能を持つCoRAGを学習させることが可能です。
検索連鎖は、複雑な質問に有効ですが、単純な質問にはその利点が小さい場合があります。
テスト時における早期停止は、トークン消費量を削減できる一方で、性能を低下させる可能性があります。
付録Cより 各タスクのプロンプトテンプレートの説明
付録Cには、CoRAGフレームワークで使用される4種類のプロンプトテンプレートが記載されています。これらのプロンプトは、CoRAGモデルが多段階の検索と推論を行うために設計されており、それぞれの目的と本研究における役割は以下の通りです。
これらのプロンプトテンプレートは、CoRAGモデルが段階的な検索と推論を実行するための明確な指示を提供します。各プロンプトは、特定のタスクを遂行するために設計されており、モデルが複雑な質問を解決するために必要な機能を果たす上で重要な役割を果たします。特に、サブクエリ生成プロンプトは、CoRAGの反復的な検索戦略を支える重要な要素であり、中間回答生成プロンプトは、検索結果から正確な情報を抽出する上で不可欠です。
サブクエリ生成プロンプト (Prompt: Sub-query Generation)
目的: 与えられたメインクエリと、それまでの検索履歴(中間クエリと回答)に基づいて、メインクエリを解決するための次のステップとなる、単純な質問(サブクエリ)を生成することです。
本研究との対応: このプロンプトは、CoRAGの多段階検索プロセスの中核を担います。モデルは、過去の検索結果を踏まえて、次に検索すべき情報を判断し、新しいサブクエリを作成します。これにより、複雑な質問を段階的に解決することが可能になります。このプロンプトは、モデルが動的にクエリを再構成し、必要に応じてメインクエリを分解することを可能にします。
中間回答生成プロンプト (Prompt: Intermediate Answer Generation)
目的: 与えられた検索結果(ドキュメント)とサブクエリに基づいて、そのサブクエリに対する適切な回答を生成することです。
本研究との対応: このプロンプトは、検索された情報から必要な情報を抽出し、サブクエリに対する事実に基づいた回答を生成する役割を担います。モデルは、与えられたドキュメントのみを使用して回答を生成し、幻覚(ハルシネーション)を避けるように指示されています。もし関連情報が見つからない場合は、「No relevant information found」と回答するように求められます。
最終回答生成プロンプト (Prompt: Final Answer Generation)
目的: それまでの中間クエリと回答、およびメインクエリに対する検索結果に基づいて、メインクエリに対する最終的な回答を生成することです。
本研究との対応: このプロンプトは、CoRAGが複数のステップで収集した情報を統合し、メインクエリに対する総合的な回答を生成するために使用されます。モデルは、中間的な回答が必ずしも正確ではない可能性があることを認識した上で、関連情報を組み合わせるように指示されています。
停止学習プロンプト (Prompt: Learning to Stop)
目的: 中間クエリと回答の履歴に基づいて、メインクエリに答えるための十分な情報があるかどうかを判断させることです。
本研究との対応: このプロンプトは、モデルがテスト時に早期停止する能力を学習させるために使用されます。モデルは、「Yes」または「No」で応答し、追加のサブクエリが必要かどうかを判断します。 この機能は、トークン消費量を削減し、計算コストを管理する上で重要です。
# サブクエリ生成プロンプト (Prompt: Sub-query Generation)
def sub_query_generation_prompt(intermediate_queries_and_answers, task_description, query):
prompt = f"""
あなたはウェブを反復的に検索してメインクエリに答えるための検索エンジンを使用しています。
以下の中間クエリと回答を踏まえて、メインクエリに答えるのに役立つ新しい簡単なフォローアップ質問を生成してください。
前の回答が役に立たない場合は、メインクエリを言い換えたり分解したりしてもかまいません。
検索エンジンは複雑な質問を理解できない可能性があるため、簡単なフォローアップ質問のみをしてください。
## 以前の中間クエリと回答
{intermediate_queries_and_answers}
## タスクの説明
{task_description}
## 回答すべきメインクエリ
{query}
メインクエリの回答に役立つ簡単なフォローアップ質問のみを返答してください。
説明や他の出力をしないでください。
"""
return prompt
このプロンプトは、与えられたメインクエリとそれまでの検索履歴に基づいて、次の検索ステップとなるサブクエリを生成します。モデルは、過去の検索結果を踏まえて、次に検索すべき情報を判断し、新しいサブクエリを作成します。
# 中間回答生成プロンプト (Prompt: Intermediate Answer Generation)
def intermediate_answer_generation_prompt(retrieved_documents, sub_query):
prompt = f"""
以下のドキュメントを踏まえて、クエリに対する適切な回答を生成してください。
情報を捏造せず、提供されたドキュメントのみを使用して回答を生成してください。
ドキュメントに役立つ情報が含まれていない場合は、「No relevant information found」と回答してください。
## ドキュメント
{retrieved_documents}
## クエリ
{sub_query}
簡潔な回答のみを返答してください。
説明や他の出力をしないでください。
"""
return prompt
このプロンプトは、検索されたドキュメントからサブクエリに対する回答を生成します。モデルは、与えられたドキュメントのみを使用して回答を生成し、幻覚を避けるように指示されています。
# 最終回答生成プロンプト (Prompt: Final Answer Generation)
def final_answer_generation_prompt(retrieved_documents, intermediate_queries_and_answers, task_description, query):
prompt = f"""
以下の中間クエリと回答を踏まえて、関連情報を組み合わせてメインクエリに対する最終的な回答を生成してください。
中間回答はLLMによって生成されており、必ずしも正確ではない可能性があることに注意してください。
## ドキュメント
{retrieved_documents}
## 中間クエリと回答
{intermediate_queries_and_answers}
## タスクの説明
{task_description}
## メインクエリ
{query}
適切な回答のみを返答してください。
説明や他の出力をしないでください。
"""
return prompt
このプロンプトは、複数のステップで収集した情報を統合し、メインクエリに対する最終的な回答を生成します。
# 停止学習プロンプト (Prompt: Learning to Stop)
def learning_to_stop_prompt(intermediate_queries_and_answers, query):
prompt = f"""
以下の中間クエリと回答を踏まえて、メインクエリに答えるための十分な情報があるかどうかを判断してください。
十分な情報があると思われる場合は、「Yes」と応答してください。そうでない場合は、「No」と応答してください。
## 中間クエリと回答
{intermediate_queries_and_answers}
## メインクエリ
{query}
「Yes」または「No」のみを返答してください。
説明や他の出力をしないでください。
"""
return prompt
このプロンプトは、モデルがテスト時に早期停止する能力を学習させるために使用され、メインクエリに答えるのに十分な情報があるかどうかを判断します。
この記事で参照した参考文献
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open-Review.net, 2024.
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. ArXiv preprint, abs/2407.21783, 2024.
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small llms can master math reasoning with self-evolved deep thinking. ArXiv preprint, abs/2501.04519, 2025.
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. ArXiv preprint, abs/2410.21276, 2024.
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. ArXiv preprint, abs/2412.16720, 2024.
Jiajie Jin, Yutao Zhu, Xinyu Yang, Chenghao Zhang, and Zhicheng Dou. Flashrag: A modular toolkit for efficient retrieval-augmented generation research. ArXiv preprint, abs/2405.13576, 2024.
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. ArXiv preprint, abs/2501.05366, 2025.
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Richard James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. RA-DIT: retrieval-augmented dual instruction tuning. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024.
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9248–9274, Singapore, 2023. Association for Computational Linguistics.
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. ArXiv preprint, abs/2403.05530, 2024.
**** An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. ArXiv preprint, abs/2412.15115, 2024.
Zhenrui Yue, Honglei Zhuang, Aijun Bai, Kai Hui, Rolf Jagerman, Hansi Zeng, Zhen Qin, Dong Wang, Xuanhui Wang, and Michael Bendersky. Inference scaling for long-context retrieval augmented generation. ArXiv preprint, abs/2410.04343, 2024.
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
参考:この論文の構成
1. Introduction (はじめに): Retrieval-Augmented Generation (RAG) の重要性と課題を述べ、多段階検索の必要性を提示し、この論文で提案するCoRAGの概要を説明します。
2. Related Work (関連研究): RAGに関する既存の研究、特に多段階検索や推論に関する研究をレビューします。
3. Methodology (手法): CoRAGフレームワークの詳細を説明します。具体的には、リジェクションサンプリングによる検索連鎖の生成、拡張データセットを用いたモデル学習、およびテスト時の計算量調整戦略について説明します。
3.1 Retrieval Chain Generation (検索連鎖の生成): リジェクションサンプリングを用いた中間検索連鎖の自動生成方法を説明します。
3.2 Training (学習): 拡張されたデータセットを用いたLLMのファインチューニング方法を説明します。
3.3 Test-time Scaling (テスト時のスケーリング): 様々なデコーディング戦略を用いてテスト時の計算量を調整する方法を説明します。
4. Experiments (実験): 多段階QAデータセットとKILTベンチマークを用いたCoRAGの評価実験とその結果を示します。
4.1 Setup (設定): 実験で使用したデータセット、評価指標、モデル学習の詳細について説明します。
4.2 Main Results (主な結果): 多段階QAデータセットとKILTベンチマークにおけるCoRAGの性能を、他のモデルと比較して示します。
4.3 Scaling Test-Time Compute (テスト時の計算量スケーリング): テスト時の計算量とモデル性能の関係について分析します。
5. Analysis (分析): CoRAGの動作と性能に関する詳細な分析を行います。
5.1 Iterative Rejection Sampling (反復的なリジェクションサンプリング): 反復的な学習による性能向上について検討します。
5.2 Robustness and Generalization (ロバスト性と汎化性能): 異なるリトリーバーやモデルを用いた場合の性能を評価します。
5.3 Does Chain-of-Retrieval Always Help? (連鎖検索は常に役立つのか?): タスクの特性に応じた連鎖検索の有効性を考察します。
5.4 Learning to Stop at Test Time (テスト時に停止を学習): テスト時に動的に停止するモデルについて検討します。
6. Conclusion (結論): この論文の成果をまとめ、今後の研究の方向性を示します。
References (参考文献): 論文中で引用された文献をリストします。
Appendix (付録): 実験の詳細や追加の結果を掲載しています。
A Implementation Details (実装の詳細): 実験環境やハイパーパラメータの詳細を記載します。
B Additional Results (追加の結果): KILTベンチマークの検証セットでの結果や、異なる設定での実験結果を示します。
C Prompts (プロンプト): 各タスクで使用したプロンプトのテンプレートを掲載します。
各章の概要は、CoRAGという新しい多段階質問応答モデルを提案し、その有効性を実験的に検証・分析することで、より事実に基づいた信頼性の高いAIシステム構築に貢献することを目指す内容となっています。