Langchainブログ:プロンプト最適化によるLLMの性能向上

こんにちはmakokonす。みなさんはお気に入りのプロンプトがありますか。普段からLLMと会話していると、プロンプトの書き方に一定のクセのような偏りが出てきますが、解決したい問題によっては、「もっといいプロンプトがないかなあ」と考えることも多くなります。経験と慣れがこの手の問題には、こんなプロンプトがいい気がするとわかった気になるのですが、これを包括的に理解することはなかなかに困難です。
今日、紹介するブログは、大規模言語モデルの性能向上を目的としたプロンプト最適化手法を検証した研究結果を報告しています。5つの異なるデータセットと5つの最適化アルゴリズム、3つの言語モデルを用いた実験を通して、プロンプト最適化が最も有効な場面、最適なモデル、信頼性の高いアルゴリズムを明らかにしています。
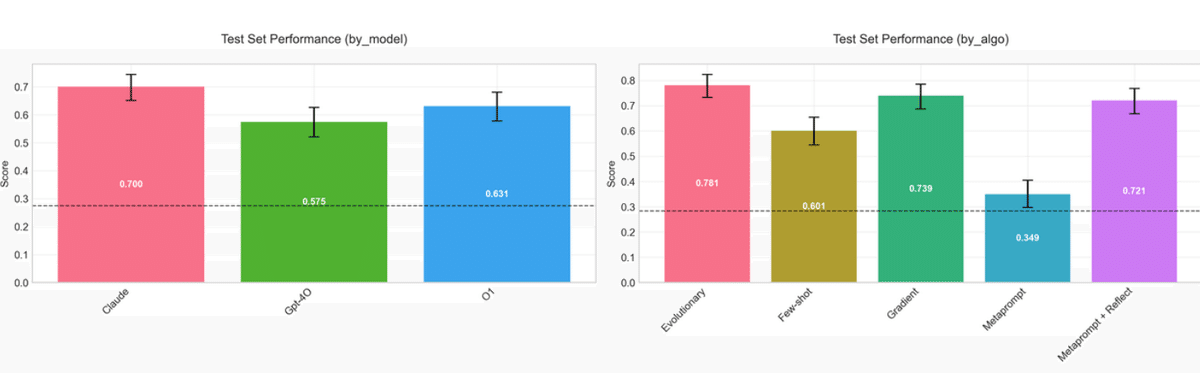
また結果として、Claude-sonnetモデルがプロンプト最適化に優れていること、ドメイン知識が不足するタスクにおいて最適化が効果的で精度を大幅に向上させる可能性があることなどが示されています。
なかなか興味ふかい内容でした。
この論文の結論はなんですか
プロンプト最適化が、特にモデルが特定のドメイン知識を持っていない場合に、LLMのパフォーマンスを大幅に向上させる可能性があることを示唆しています。ただし、プロンプト最適化は万能薬ではなく、他のツールと組み合わせて使用する必要があります。
プロンプト最適化にはclaude-sonnetモデルを推奨します (o1よりも優れています)。
プロンプト最適化は、基盤モデルがドメイン知識を欠いているタスクで最も効果的です。
上記の状況では、プロンプト最適化によって、単純なベースラインプロンプトと比較して精度が約200%向上する可能性があります。
これらの状況におけるプロンプト最適化は、データから直接適応を学習する長期記憶の一形態と考えることもできます。
メタプロンプティングは、LLMがドメイン知識にない可能性のあるルールや好みを検出するのに特に役立ちます。
メタプロンプティングは、好みのニュアンスを伝えるにはあまり役に立ちません。
少数の例とインストラクションチューニングを組み合わせることで、相補的な改善が得られると推測されます。
メタプロンプティングによってモデルに新しい機能が付与されるわけではありません。
検証可能な結果を持つデータセットで最適化を行うことが重要です。
プロンプト最適化は、LLMアプリケーションを改善するためのより広範なツールキットの1つとして捉えるのが最適です。
claudeは、テストされた設定では、より信頼性の高いオプティマイザーモデルでした。
これらの結果は、LLMが効果的なプロンプトエンジニアであることを裏付けています。
どうやって確認しましたか
プロンプト最適化の効果を検証するために、5つの異なるデータセットを用いて、5つの異なるプロンプト最適化手法をベンチマークしました。
また、3つの異なるモデル(gpt-4o、claude-sonnet、o1)がプロンプト最適化にどのように影響するかを評価しました。
データセット
サポートメールルーティング(3): 受信メールを3人の担当者のうち正しい担当者にルーティングするタスク。
サポートメールルーティング(10): 上記と同様だが、担当者が10人となるより難易度の高いタスク。
多言語数学: 数学の文章題に対し、問題のテーマに基づいて5つの言語のいずれかで回答するタスク。
メールアシスタント(シンプル): メールに対し、無視、返信、通知のいずれかの対応を決定するタスク。
メールアシスタント(エキセントリック): 上記と同様だが、隠れたルールに基づいて判断するタスク。
プロンプト最適化手法(アルゴリズム)
少数の例(Few-shot prompting): 学習例をプロンプトに含め、期待される動作を示す。
最も単純な手法であり、学習データから最大50個の例をプロンプトに含めることで、モデルに期待される動作をデモンストレーションします
メタプロンプティング: LLMを使用してプロンプトを分析し、改善する。
これは、指示チューニングの最も単純なアプローチです。◦まず、対象のLLMで例を実行し、出力に対してスコアを計算します。
◦次に、別のLLM(メタプロンプティングLLM)に、入力、出力、参照出力(利用可能な場合)、および現在のプロンプトのスコアを示し、それに基づいてより良いプロンプトを作成させます。
◦このプロセスをミニバッチで繰り返し、開発セットで評価し、最も高いスコアのプロンプトを保持します。
プロンプト勾配: 例ごとに改善のための具体的なフィードバック(「テキスト勾配」)を生成し、それを別のLLM呼び出しで適用する。(図1)
このアプローチは、最適化をより小さなステップに分解します。
まず、現在のプロンプトの出力をスコアリングします。
次に、LLMを使用して、プロンプトが失敗した例ごとに具体的なフィードバック(「勾配」)を生成します。
これらの収集された「勾配」に基づいて、プロンプトの更新を提案します。
この手法は、変更を加える前に詳細なフィードバックを収集することで、メタプロンプティングよりも的を絞った改善につながると考えられています。
進化的最適化: 制御された変異を通じてプロンプト空間を探索する。(図2)
このアルゴリズムは、「世代」ごとに動作し、各世代で**LLMの助けを借りて作成されたさまざまなタイプのプロンプト更新(「変異」)**を適用し、候補プロンプトを作成します7...。
◦各世代後、最もパフォーマンスの高いプロンプトが保持されます7。
◦この論文では、CuiらのPhaseEvoという手法を適応し、テキスト勾配アプローチと、既存の集団における共有パターンに基づいて新しいプロンプトを作成するようLLMに指示する「グローバル」な更新を組み合わせました。
◦これにより、アルゴリズムが、より広いプロンプトのバリエーションを探索することで、局所的な最適解を克服するのに役立つと考えられています。


評価
これらの手法を、各データセットで上記の3つのモデルを用いて実行し、開発セットで最も高いスコアを出したプロンプトを最終結果として評価しました。テストセットでの平均スコアを算出し、ベースラインプロンプトの結果と比較することで、各手法とモデルの性能を評価しました。また、トレーニングの進捗状況(開発セットでのスコアの変化)も分析しました。
データセット別に見る結果のまとめ
全体として、claude-sonnetが最も信頼性の高いオプティマイザーモデルであり、プロンプト最適化は、モデルがドメイン知識を欠いているタスクで特に効果的であることが示されました。また、少数の例は単純なタスクで効果的であり、進化的最適化は複雑なタスクでより良い結果を出す傾向がありました。
サポートメールルーティング(3):
サポートメールルーティング(3):
最適化手法は全般的にベースラインよりも改善が見られ、特に勾配ベースと進化的アプローチが類似の向上を示しました。
claude-sonnetはgpt-4oよりも優れた結果を出し、特にメタプロンプティング手法では顕著な差が見られました。
少数の例によるプロンプトは改善が見られたものの、最適とは言えませんでした。

サポートメールのルーティング(経路選択)実験に関するテスト性能図1
正解の判定基準:
プロンプトとモデルの組み合わせが、メールを正しい担当者に振り分けた場合を正解(1)とする
実験設定と評価方法:
開発(dev)データセットで最も高い合格率を示したプロンプトを選択
そのプロンプトをテストデータセットで評価
集計方法:
モデルとアルゴリズムごとの集計は算術平均を使用
サポートメールルーティング(10):
サポートメールルーティング(10):
gpt-4oは単純なメタプロンプティングとメタプロンプティング+反省アルゴリズムでは開発セットで収束に失敗し、テストセットでも悪い結果となりました。
少数の例によるプロンプトは安定した改善を見せましたが、他の最適化手法には及ばない結果となりました。
o1がこのデータセットで最も良い結果を出し、claude-sonnetを上回りましたが、gpt-4oは進化型と勾配アルゴリズム以外では苦戦しました。
gpt-4oはメタプロンプティング+反省の構成でプロンプトが悪化する現象が見られました。


サポートメールのルーティング(経路選択)実験に関するテスト性能図1
サンプル数が増えただけで評価基準はサポートメールルーティング(3)と同じです。サンプルが多く、評価の信頼性が向上しています。
多言語数学
多言語数学:
このデータセットは、開発セットのパフォーマンスが特定の期間で大きく向上するという特徴がありました。
ほとんどのモデルとアルゴリズムの組み合わせは、ベースラインからの改善が乏しかったです。
少数の例を利用したo1とo1-miniが最も効果的でした。
o1は少数の例を利用できましたが、プロンプトの最適化には失敗しました。
claude-sonnetとgpt-4oは進化型アルゴリズムで、そしてclaude-sonnetはメタプロンプティング+反省の設定で解決策を発見することができました。


多言語数学のテスト性能
正解の判定基準:
値が正しく表現されている
指定された目標言語で正しく表現されている
上記の両方を満たす場合にスコア1を付与
評価プロセス:
開発データセットで最高パフォーマンスを示したプロンプトを選択
そのプロンプトをテストデータで評価
集計方法:
モデルとアルゴリズムの性能は算術平均で算出
この実験の特徴は、単なる計算の正確さだけでなく、異なる言語での適切な表現も評価基準に含まれている点です。これは言語モデルの多言語能力と数学的能力の両方を測定するものといえます。
メールアシスタント(シンプル)
メールアシスタント(シンプル):
少数の例によるプロンプトが最も信頼性の高い改善を示しました。
このタスクはモデルの既存の知識で十分に対応できるため、最適化による改善は限定的でした。
直接的なプロンプト最適化(勾配、メタプロンプト)は、モデルがすでに知っている以上の指示を捉えるのに苦労しました。
o1とgpt-4oは、このタスクで支援に苦戦しました。


メールアシスタント(シンプル版)データセットにおけるテストデータでの性能(合格率)
評価プロセス:
開発データセットで最も高い合格率を示したプロンプトを選択
選択されたプロンプトをテストデータで評価
集計方法:
モデルとアルゴリズムごとの性能は算術平均で計算
合格率(pass rate)で性能を測定
メールアシスタント(エキセントリック)
メールアシスタント(エキセントリック):
進化的アプローチはトレーニングを通して安定した改善を見せました。
claude-sonnetはgpt-4oとo1よりも優れた結果を出し、進化的アルゴリズムは他の2つの手法を上回る傾向がありました。
o1は進化的アプローチでは性能が低い結果となりました。


結果全体を通して
全体として、claude-sonnetが最も信頼性の高いオプティマイザーモデルであり、プロンプト最適化は、モデルがドメイン知識を欠いているタスクで特に効果的であることが示されました。また、少数の例は単純なタスクで効果的であり、進化的最適化は複雑なタスクでより良い結果を出す傾向がありました。


この論文で得られた主な知見
この論文で得られた知見をアルゴリズムごとに強みに注目してまとめます。
結論として、メタプロンプティング、勾配法、進化法のそれぞれが、プロンプト最適化において異なる強みを持っています。メタプロンプティングはルールや好みの発見に、勾配法はターゲットを絞った改善に、進化法は複雑なタスクやより広い探索に適しています。これらの手法は、タスクの性質やモデルの特性に合わせて適切に選択、または組み合わせることで、より効果的なプロンプト最適化が実現できると考えられます。論文の結果は、特定の手法を否定するものではなく、それぞれの長所と短所を理解し、適切に活用することの重要性を示唆しています。
メタプロンプティングの強み:
論文では、メタプロンプティングが、LLMが持つドメイン知識の外にあるルールや好みを「発見」するのに特に役立つと述べています。つまり、例を通じて望ましい行動を定義し、オプティマイザーがそれらの行動を他のLLMに適用できるようにする能力に優れています。
メタプロンプティングは、指示チューニングのシンプルなアプローチとして、プロンプトを反復的に改善するのに有効です。
しかし、メタプロンプティングは、微妙なニュアンスを伝えるのにはあまり効果的ではないことも指摘されています。
勾配法の強み:
勾配法は、プロンプトが失敗した例ごとに具体的なフィードバック(「勾配」)を生成し、それに基づいてプロンプトを更新するという、よりターゲットを絞った改善アプローチを取ります。
この手法は、変更を加える前に詳細なフィードバックを収集することで、メタプロンプティングよりも的を絞った改善につながると考えられています。
例えば、サポートメールルーティング(3)のデータセットでは、勾配法は進化法と同様にベースラインからの改善を示しました。
メールアシスタント(シンプル)のデータセットでは、他の直接的な最適化アプローチと同様に苦戦しましたが、これはタスクの性質によるものであり、手法の有効性を否定するものではありません。
進化法の強み:
進化法は、複数のプロンプトを「世代」ごとに進化させ、より広いプロンプト空間を探索することで、局所的な最適解を克服することを目指します。
この手法は、特に多言語数学やメールアシスタント(エキセントリック)のような複雑なタスクで効果を発揮する傾向があります。
例えば、多言語数学のデータセットでは、claude-sonnetとgpt-4oは進化型アルゴリズムで解決策を発見しました。
メールアシスタント(エキセントリック)のデータセットでは、進化的なアプローチがトレーニングを通して安定した改善を見せました。
少数の例との比較:
少数の例によるプロンプトは、単純なタスクで最も信頼性の高い改善を示す一方で、複雑なルールや条件を捉えるのには不向きです。
メタプロンプティング、勾配法、進化法は、より複雑なタスクや、LLMの既存の知識外のルールを学習する必要がある場合に、少数の例よりも優れている可能性があります。