
pythonプログラムの初歩16/(演習)ジョーク約分を見つけよう

pythonプログラムの初歩16
(演習)ジョーク約分を見つけよう
こんにちはmakokonです。初心者向けpythonプログラムの時間にようこそ。
今日は、演習ぽく、簡単なプログラムからエラーをなくしたり、動作を改善しながら、プログラムがどう変化していくのかを見ていきましょう。各章のタイトルも演習ぽくなっています。
今日のお題は、ジョーク約分です。なにそれ?。まあ、本当にそんな名前なのか知りませんが、試してみましょう。
ジョーク約分とは
例によって、noteのネタになるような面白い画像がないかなあとSNSを見ているとありましたよ。
それがこの画像です。まさにジョーク約分。分母と分子に同じ数字があるとその数字を分母と分子から取り除く処理です。そして、不思議なことに結果は正しい。(注意 結果が正しいのは偶然です。算数の勉強中の人や、教育関係者の人は決して使わないでください)
とにかく面白い数字です。このジョーク約分を見つけるプログラムを書いてみたい。ちょっと考えてみてもいろいろな処理が必要そうです。
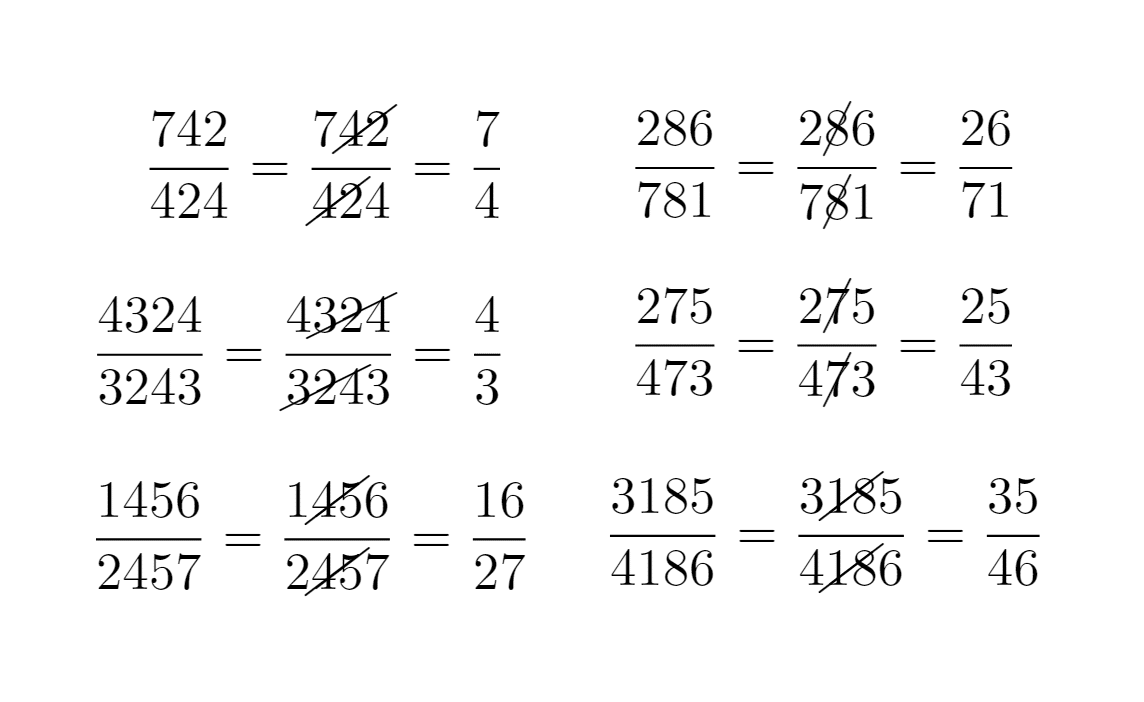
https://x.com/Pajoca_/status/1863163347396694264
先生激おこになる約分(ただし成立)
課題 ジョーク約分を見つけるプログラムを書きなさい。
では、順番に進めてみましょう。
ジョーク約分の特徴
まず、目的とするジョーク約分の特徴を正しく認識しましょう。
特徴としては、
分子と分母の数字を見て、同じ数字を消して(削除して)残った数字で新しい分数を作っています
偶然にも、その結果が正しい約分結果と一致しています
分母と分子は10以上の整数
分母は分子より大きい。
例えば、742/424 の場合を考えると
42(4と2)を消すと 742/424 -> 7/4 となり、これが実際の約分結果と一致します。
あと、プログラムの都合上ですが、3と4の条件を付け加えておきます。
課題01 分母が10から1000まで変化するときのジョーク約分を見つけなさい。
探索アルゴリズムはどうしましょうか?とりあえず、こんな感じで
指定された範囲内の分数を生成
分子と分母の共通の数字を見つける
その数字を削除した新しい分数を作成
元の分数の値と新しい分数の値が一致するものを抽出
テクニックとしては、分母と分子を2重ループで変化させて元の分数を作る。
分母と分子を文字列に変えて、共通の文字があったら取り除く。
再び数字に戻して割り算する。
元の分数とその結果が一致吸えば、元の分母分子の組み合わせをジョーク分数として登録する
という手順でできそうですね。
課題01−A 1回目の答え lesson16-0.py
さっきの方針に従って、作ってみました。
def find_joke_fractions(max_num=10000):
results = []
for numerator in range(10, max_num):
for denominator in range(10, max_num):
if numerator >= denominator:
continue
# 本来の分数の値
true_value = numerator / denominator
# 数字を文字列として処理
num_str = str(numerator)
den_str = str(denominator)
# 共通の数字を見つける
common_digits = set(num_str) & set(den_str)
for digit in common_digits:
# 数字を削除した新しい文字列を作成
new_num = int(''.join(c for c in num_str if c != digit))
new_den = int(''.join(c for c in den_str if c != digit))
# 0による除算を防ぐ
if new_den == 0:
continue
# 新しい分数の値を計算
joke_value = new_num / new_den
# 元の値と一致する場合
if abs(true_value - joke_value) < 1e-10:
results.append((numerator, denominator, new_num, new_den))
return results
# 実行例
results = find_joke_fractions(1000)
for n, d, new_n, new_d in results:
print(f"{n}/{d} = {new_n}/{new_d}")課題01−A 1回目の答えの結果
$ python lesson16-0.py
Traceback (most recent call last):
File "lesson16-0.py", line 38, in <module>
results = find_joke_fractions(1000)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "lesson16-0.py", line 22, in find_joke_fractions
new_den = int(''.join(c for c in den_str if c != digit))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ValueError: invalid literal for int() with base 10: ''おっと、いきなりエラーですね。
ValueError: invalid literal for int() with base 10: ''
共通の文字を取り除いたら、文字列が空になって、数字に戻せなくなったようです。
対策しましょう。
課題01−B 2回目 空の文字列対策をしなさい lesson16-1.py
空文字列チェックを追加(`if not new_num_str or not new_den_str`)
例外処理を追加(try-except)
目的の文字列が空かどうかは、文字列の長さをチェックしてもいいですが、IFのあと単に変数を書いてもチェックできます。
ついでに、今後も色々追加しそうなので(try-except)を使って、主要な処理で、エラーの例外処理ができるようにしておきましょう。
0での除算などのチェックと並べてかけてわかりやすいですね。
def find_joke_fractions(max_num=10000):
results = []
for numerator in range(10, max_num):
for denominator in range(10, max_num):
if numerator >= denominator:
continue
# 本来の分数の値
true_value = numerator / denominator
# 数字を文字列として処理
num_str = str(numerator)
den_str = str(denominator)
# 共通の数字を見つける
common_digits = set(num_str) & set(den_str)
for digit in common_digits:
try:
# 数字を削除した新しい文字列を作成
new_num_str = ''.join(c for c in num_str if c != digit)
new_den_str = ''.join(c for c in den_str if c != digit)
# 空文字列チェック
if not new_num_str or not new_den_str:
continue
new_num = int(new_num_str)
new_den = int(new_den_str)
# 0による除算を防ぐ
if new_den == 0:
continue
# 新しい分数の値を計算
joke_value = new_num / new_den
# 元の値と一致する場合
if abs(true_value - joke_value) < 1e-10:
results.append((numerator, denominator, new_num, new_den))
except:
continue
return results
# 実行例
results = find_joke_fractions(1000) # 範囲を小さくして試す
for n, d, new_n, new_d in results:
print(f"{n}/{d} = {new_n}/{new_d}")課題01−B 2回目 lesson16-1.pyの結果
$ python lesson16-1.py
10/20 = 1/2
10/30 = 1/3
10/40 = 1/4
10/50 = 1/5
10/60 = 1/6
10/70 = 1/7
10/80 = 1/8
10/90 = 1/9
10/110 = 1/11
10/120 = 1/12
10/130 = 1/13
10/140 = 1/14
以下略 エラーが消えて動きました。
しかし、
10/90 = 1/9
10/110 = 1/11
10/120 = 1/1
こんなパターンがっかりです。分母分子から末尾の0を取り除いたら、どちらも10で割った結果と同じですよね。
実につまらん。これはジョークになっていない。
こんなパターンは必要ありません。
課題01−C 3回目 末尾が0のケースを取り除きなさい lesson16-2.py
これは簡単ですね。 分母と分子の文字列の末尾が0の場合をチェックしたらOKです。
if digit == '0' and (num_str.endswith('0') or den_str.endswith('0')):
continue
全部のコードを提示するまでもないのですが、やりましょう。
def find_joke_fractions(max_num=10000):
results = []
for numerator in range(10, max_num):
for denominator in range(10, max_num):
if numerator >= denominator:
continue
# 本来の分数の値
true_value = numerator / denominator
# 数字を文字列として処理
num_str = str(numerator)
den_str = str(denominator)
# 共通の数字を見つける
common_digits = set(num_str) & set(den_str)
for digit in common_digits:
# 末尾の0の場合はスキップ
if digit == '0' and (num_str.endswith('0') or den_str.endswith('0')):
continue
try:
# 数字を削除した新しい文字列を作成
new_num_str = ''.join(c for c in num_str if c != digit)
new_den_str = ''.join(c for c in den_str if c != digit)
# 空文字列チェック
if not new_num_str or not new_den_str:
continue
new_num = int(new_num_str)
new_den = int(new_den_str)
# 0による除算を防ぐ
if new_den == 0:
continue
# 新しい分数の値を計算
joke_value = new_num / new_den
# 元の値と一致する場合
if abs(true_value - joke_value) < 1e-10:
results.append((numerator, denominator, new_num, new_den))
except:
continue
return results
# 実行例
results = find_joke_fractions(1000)
for n, d, new_n, new_d in results:
print(f"{n}/{d} = {new_n}/{new_d}")課題01−C 3回目 lesson16-2.pyの実行結果
実行結果です。
$ python lesson16-2.py
前略
149/298 = 14/28
149/596 = 14/56
149/894 = 14/84
154/253 = 14/23
154/352 = 14/32
154/451 = 14/41
156/858 = 16/88
159/795 = 15/75
後略10でわるケースは、除外できています。
同じ文字を取り除いてピックアップする最初の問題はクリアできたかもしれません。ここで課題01はクリアしたことにしましょう。
課題02 2桁以上の数字の取り除きに対応しなさい。
さっきの結果をよく見ると、まだまだ不十分だと思います。
最も重要なのは、例示したような(742/424==>7/4)などの事例が含まれません。適当な場所の2桁以上の異なった数字を取り除いても成立するからこそ、驚きと笑いが得られると思います。
そういえばさっきまでは共通の文字を探して消していただけでしたね。
課題02−A 連続した2つ以上の数字を同時に消しなさい lesson16-3.py
俄然難易度が上がりましたね。こういう処理にはそれなりのテクニックもあるのですが、今回の処理は力ずくです。
つまり、元の文字列から2文字以上の部分文字列を切り出して、相方の同じ長さの部分文字列と片っ端から比較することにします。
def find_joke_fractions(max_num=10000):
results = []
for numerator in range(10, max_num):
for denominator in range(10, max_num):
if numerator >= denominator:
continue
# 本来の分数の値
true_value = numerator / denominator
# 数字を文字列として処理
num_str = str(numerator)
den_str = str(denominator)
# 共通の連続する部分文字列を探す
for length in range(2, min(len(num_str), len(den_str)) + 1):
for i in range(len(num_str) - length + 1):
num_part = num_str[i:i+length]
# 末尾の0を含むパターンは除外
if num_part.endswith('0'):
continue
for j in range(len(den_str) - length + 1):
den_part = den_str[j:j+length]
# 同じ連続数字列が見つかった場合
if num_part == den_part:
try:
# その部分を除いた新しい数を作成
new_num_str = num_str[:i] + num_str[i+length:]
new_den_str = den_str[:j] + den_str[j+length:]
# 空文字列チェック
if not new_num_str or not new_den_str:
continue
new_num = int(new_num_str)
new_den = int(new_den_str)
# 0による除算を防ぐ
if new_den == 0:
continue
# 新しい分数の値を計算
joke_value = new_num / new_den
# 元の値と一致する場合
if abs(true_value - joke_value) < 1e-10:
results.append((numerator, denominator, new_num, new_den, num_part))
except:
continue
return results
# 実行例
results = find_joke_fractions(1000)
for n, d, new_n, new_d, removed in results:
print(f"{n}/{d} = {new_n}/{new_d} (removed: {removed})")主な変更点:
連続する数字列(2桁以上)を探すように変更
分子と分母から同じ連続数字列を見つけて削除
末尾の0を含むパターンは除外
削除した数字列も表示するように変更
4は、どういうジョーク約分だったのか、わかりにくいので対応しました。
プログラムの機能が増えるほどわかりやすいアウトプットが重要ですね。
課題02−A lesson16-3.py の結果
早速実行してみましょう。
$ python lesson16-3.py
166/664 = 1/4 (removed: 66)
199/995 = 1/5 (removed: 99)
266/665 = 2/5 (removed: 66)
424/742 = 4/7 (removed: 42)
484/847 = 4/7 (removed: 84)
499/998 = 4/8 (removed: 99)
545/654 = 5/6 (removed: 54)おお、なかなかいい感じです。(424,742)の組み合わせもありますね。もう完成でもいいかもしれません。(いやそんなことない)
そもそも動作確認も全く不十分ですね。
ここで全部するわけにもいかないですが、少なくとも探索範囲を広げてみましょう。
課題02−B 探索範囲を10000まで拡大して動作を確認しよう lesson16-4.py
流石に、範囲を変更するだけなので全部は載せません。
試してみましょう:
注意 このプログラムは2重ループのおばけなので探索範囲nが増えるとO(n²)のオーダーで 計算量が増えますので結構時間がかかります。つまり探索範囲が10倍になったので100倍時間がかかります。無理に実行する必要はないでしょう。
def find_joke_fractions(max_num=10000):
# (前のコードと同じ)
# より大きな範囲で実行して、結果を約分前の桁数でソート
results = find_joke_fractions(10000)
sorted_results = sorted(results, key=lambda x: len(str(x[0])))
# 見やすく表示
for n, d, new_n, new_d, removed in sorted_results:
print(f"{n}/{d} = {new_n}/{new_d} (removed: {removed}, {len(removed)}桁)")課題02−B lesson16-4.py の結果
実行結果です。もちろん随分と時間がかかりました。
結論から言うと結果は正しかったけど、つまらないパターンがまだ有りました。
ひどいのは分母が分子の10倍になっているパターン。全く感動がありません。ジョークになっていません。次はそのへんをケアしながら体裁を整えていきましょう
$ python lesson16-4.py
前略
981/9810 = 1/10 (removed: 98)
981/9810 = 9/90 (removed: 81)
982/9820 = 2/20 (removed: 98)
982/9820 = 9/90 (removed: 82)
983/9830 = 3/30 (removed: 98)
983/9830 = 9/90 (removed: 83)
984/9840 = 4/40 (removed: 98)
984/9840 = 9/90 (removed: 84)
985/9850 = 5/50 (removed: 98)
985/9850 = 9/90 (removed: 85)
後略
時間がかかる問題をどうするかですか?
この記事は初心者向けのプログラミングなので、別途アルゴリズムの開発記事を読んでください。
例えば、枝刈りの徹底や、並列処理、無駄とわかっているものを生成しないロジックなどの対策があります。
課題03 最終形に向けて 気になっている部分に手を入れよう
先程の、面白くない10倍パターンを排除するとともに、少し使い勝手を改善しましょう。
課題03-A 10倍パターンを排除し、探索範囲を指定できるようにしなさい。 lesson16-5.py
具体的には、
分母の探索範囲をコマンドラインから指定できるようにする >python sampley.py min max
分子の探索範囲は、min/10-max ただし、min/10が10未満なら10に固定する。
分母=分子*10のパターンは、探索結果に含めない。
こんな方針で行きます。 コマンドラインの引数については以前紹介しましたね。探索範囲は、ループ範囲を変更すればOK。また、パターン排除は、いつもの場所に放り込めばいいでしょう。
import sys
def find_joke_fractions(min_den, max_den):
results = []
# 分子の範囲を設定
min_num = max(10, min_den // 10)
max_num = max_den
for numerator in range(min_num, max_num + 1):
for denominator in range(min_den, max_den + 1):
# 分子が分母以上、または分母が分子の10倍の場合はスキップ
if numerator >= denominator or denominator == numerator * 10:
continue
# 本来の分数の値
true_value = numerator / denominator
# 数字を文字列として処理
num_str = str(numerator)
den_str = str(denominator)
# 共通の連続する部分文字列を探す
for length in range(2, min(len(num_str), len(den_str)) + 1):
for i in range(len(num_str) - length + 1):
num_part = num_str[i:i+length]
# 末尾の0を含むパターンは除外
if num_part.endswith('0'):
continue
for j in range(len(den_str) - length + 1):
den_part = den_str[j:j+length]
# 同じ連続数字列が見つかった場合
if num_part == den_part:
try:
# その部分を除いた新しい数を作成
new_num_str = num_str[:i] + num_str[i+length:]
new_den_str = den_str[:j] + den_str[j+length:]
# 空文字列チェック
if not new_num_str or not new_den_str:
continue
new_num = int(new_num_str)
new_den = int(new_den_str)
# 0による除算を防ぐ
if new_den == 0:
continue
# 新しい分数の値を計算
joke_value = new_num / new_den
# 元の値と一致する場合
if abs(true_value - joke_value) < 1e-10:
results.append((numerator, denominator, new_num, new_den, num_part))
except:
continue
return results
def main():
# コマンドライン引数のチェック
if len(sys.argv) != 3:
print("Usage: python script.py min_denominator max_denominator")
print("Example: python script.py 100 1000")
sys.exit(1)
try:
min_den = int(sys.argv[1])
max_den = int(sys.argv[2])
if min_den < 10 or max_den <= min_den:
print("Error: min_denominator must be >= 10 and max_denominator must be > min_denominator")
sys.exit(1)
except ValueError:
print("Error: Arguments must be integers")
sys.exit(1)
print(f"Searching for joke fractions with denominators between {min_den} and {max_den}")
results = find_joke_fractions(min_den, max_den)
if not results:
print("No joke fractions found")
else:
for n, d, new_n, new_d, removed in sorted(results, key=lambda x: (len(str(x[0])), x[0])):
print(f"{n}/{d} = {new_n}/{new_d} (removed: {removed}, {len(removed)}桁)")
print(f"\nTotal {len(results)} patterns found")
if __name__ == "__main__":
main()その他、細々した変更を加味して、出来上がったコードの特徴は、
主な変更点:
コマンドライン引数で分母の範囲を指定可能に
分子の範囲を適切に設定(min_den/10以上、max_den以下)
分母=分子×10のパターンを除外
エラーチェックとユーザーフレンドリーなメッセージを追加
結果の総数を表示
使用例:
python lesson16-5.py 100 1000これで、より使いやすく、かつ不適切なパターンを除外したプログラムになったかな。
課題03-A lesson16-5.py の結果
早速結果を確認してみましょう。
$python lesson16-5.py 2000 2500
Searching for joke fractions with denominators between 2000 and 2500
273/2275 = 3/25 (removed: 27, 2桁)
333/2331 = 3/21 (removed: 33, 2桁)
333/2331 = 3/21 (removed: 33, 2桁)
334/2338 = 4/28 (removed: 33, 2桁)
364/2366 = 4/26 (removed: 36, 2桁)
444/2442 = 4/22 (removed: 44, 2桁)
444/2442 = 4/22 (removed: 44, 2桁)
455/2457 = 5/27 (removed: 45, 2桁)
1092/2093 = 12/23 (removed: 09, 2桁)
1183/2184 = 13/24 (removed: 18, 2桁)
1212/2121 = 12/21 (removed: 12, 2桁)
1212/2121 = 12/21 (removed: 21, 2桁)
1212/2121 = 12/21 (removed: 21, 2桁)
1212/2121 = 12/21 (removed: 12, 2桁)
1216/2128 = 16/28 (removed: 12, 2桁)
1216/2128 = 16/28 (removed: 21, 2桁)
1221/2220 = 11/20 (removed: 22, 2桁)
1221/2220 = 11/20 (removed: 22, 2桁)
1274/2275 = 14/25 (removed: 27, 2桁)
1332/2331 = 12/21 (removed: 33, 2桁)
1336/2338 = 16/28 (removed: 33, 2桁)
1365/2366 = 15/26 (removed: 36, 2桁)
1443/2442 = 13/22 (removed: 44, 2桁)
1456/2457 = 16/27 (removed: 45, 2桁)
1820/2184 = 20/24 (removed: 18, 2桁)
2045/2454 = 20/24 (removed: 45, 2桁)
Total 26 patterns foundおお、いい感じですね。それらしい意外な分数が並んでいます。
探索範囲も、発見した個数などの表示も親切ぽくなりました。
なお、今回はお遊びプログラムかつ課題を提供するためのプログラムなので割愛していますが、範囲指定を変更したときは、境界条件を含むいろんなパターンを確認してくださいね。
結果の中で気になるところを探してみましょう。
1212/2121 = 12/21 (removed: 12, 2桁)
1212/2121 = 12/21 (removed: 21, 2桁)
1212/2121 = 12/21 (removed: 21, 2桁)
1212/2121 = 12/21 (removed: 12, 2桁)
このあたり、同じ元分数が並んでいるのが気になりますね。これは、間違いではなく同じ数字でも消す場所が違ったり、成立するパターンが複数あるからです。
全探索がテーマなら、それが正しいですけど、テーマがジョークなので、同じ分数は1個でいいような気もします。
課題03-B 最終結果から重複した分数を削除しなさい lesson16-6.py
具体的には、最後のリストをソートして、重複している要素をグループ化して一つにまとめます。約分前後の数字の組み合わせでまとめるのが良さそうです。
また、すべてを探索することが重要なこともあるので、重複を削除するのではなく、オプションで選べるようにしたほうがいいでしょう。
オプションが増えたので後で分かるように簡単なヘルプもつけましょう。
探索部の本体は変更する必要がないでしょう。
import sys
import argparse
from itertools import groupby
def find_joke_fractions(min_den, max_den):
# (前のコードと同じ)
def remove_duplicates(results):
# 約分前後の分数の組み合わせでソートしてグループ化
sorted_results = sorted(results, key=lambda x: (x[2], x[3], x[0], x[1]))
unique_results = []
# 約分後の結果が同じものの中から最初の1つだけを残す
for key, group in groupby(sorted_results, key=lambda x: (x[2], x[3])):
unique_results.append(next(group))
return unique_results
def main():
# コマンドライン引数の解析
parser = argparse.ArgumentParser(description='Find joke fractions')
parser.add_argument('min_den', type=int, help='Minimum denominator')
parser.add_argument('max_den', type=int, help='Maximum denominator')
parser.add_argument('--allow-duplicates', '-d', action='store_true',
help='Allow duplicate results (same reduced fraction)')
args = parser.parse_args()
# 引数の妥当性チェック
if args.min_den < 10 or args.max_den <= args.min_den:
print("Error: min_denominator must be >= 10 and max_denominator must be > min_denominator")
sys.exit(1)
print(f"Searching for joke fractions with denominators between {args.min_den} and {args.max_den}")
results = find_joke_fractions(args.min_den, args.max_den)
if not results:
print("No joke fractions found")
return
# 重複削除のオプション処理
if not args.allow_duplicates:
original_count = len(results)
results = remove_duplicates(results)
if original_count != len(results):
print(f"\nRemoved {original_count - len(results)} duplicate patterns")
# 結果の表示
for n, d, new_n, new_d, removed in sorted(results, key=lambda x: (len(str(x[0])), x[0])):
print(f"{n}/{d} = {new_n}/{new_d} (removed: {removed}, {len(removed)}桁)")
print(f"\nTotal {len(results)} patterns found")
if __name__ == "__main__":
main()使用例:
# 重複を削除して実行
python lesson16-6.py 100 1000
# 重複を許可して実行
python lesson16-6.py 100 1000 --allow-duplicates
# または
python lesson16-6.py 100 1000 -d主な変更点:
argparseを使用してコマンドライン引数を処理
--allow-duplicatesオプションを追加
remove_duplicates関数を追加して重複を削除
探索結果の数は最終的に表示した数
--helpオプションの追加
重複の削除は、約分後の分数(new_n/new_d)が同じものを1つにまとめる形で行われます。これにより、同じ結果に至る異なるパターンが整理され、より簡潔な出力が得られます。
オプションの説明は以下のようにして確認できます:
python script.py --helpparser.add_argumentのhelpパラメータは、各引数の説明を指定します。この説明は、ユーザーが--helpオプションを使ってプログラムの使い方を尋ねたときに表示されるヘルプメッセージに含まれます。これにより、ユーザーは各引数が何を意味するのかを理解しやすくなります。
課題03-B lesson16-6.pyの結果
では、結果の確認です。
$python lesson16-6.py 2000 2500
Searching for joke fractions with denominators between 2000 and 2500
Removed 10 duplicate patterns
273/2275 = 3/25 (removed: 27, 2桁)
333/2331 = 3/21 (removed: 33, 2桁)
334/2338 = 4/28 (removed: 33, 2桁)
364/2366 = 4/26 (removed: 36, 2桁)
444/2442 = 4/22 (removed: 44, 2桁)
455/2457 = 5/27 (removed: 45, 2桁)
1092/2093 = 12/23 (removed: 09, 2桁)
1183/2184 = 13/24 (removed: 18, 2桁)
1212/2121 = 12/21 (removed: 12, 2桁)
1216/2128 = 16/28 (removed: 12, 2桁)
1221/2220 = 11/20 (removed: 22, 2桁)
1274/2275 = 14/25 (removed: 27, 2桁)
1365/2366 = 15/26 (removed: 36, 2桁)
1443/2442 = 13/22 (removed: 44, 2桁)
1456/2457 = 16/27 (removed: 45, 2桁)
1820/2184 = 20/24 (removed: 18, 2桁)
Total 16 patterns foundちゃんと重複がなくなっていますね。ここには、書きませんが他のパラメータも確認してみてください。
色々、不満はまだありますが、学習用ということでこれで一旦の完成とします。
最終課題
今回のプログラム作成を通じて学んだことを整理しなさい。
大層なことをいいましたが、下記のようなプログラミング要素を詰め込みました。今までのプログラムで順を追ってみればその効果と使い方がわかると思います。
基本的なデータ型の扱い
int と str の相互変換
文字列操作(スライス、結合、部分文字列の検索)
数値演算(除算、比較)
アルゴリズム的思考
探索範囲の設定
連続部分文字列の抽出
重複の除去
プログラムの構造化
関数の定義と使用
メイン処理の分離
エラー処理
try-except による例外処理
入力値の妥当性チェック
コマンドライン引数の処理
argparse の使用
オプション処理
プログラムの出力
フォーマット文字列の使用
結果の整形表示
このプログラムの問題について考え、発展的なプログラムを作成しなさい。
これも大層なこと行っていますが、例えば以下のような改善があると思います。(難易度はバラバラです)
パフォーマンスの最適化
探索範囲の枝刈り
アルゴリズムの改善
並列処理の導入
機能の拡張
異なる「ジョーク約分」パターンの追加
結果のファイル出力
より詳細な統計情報の表示
コード品質の向上
ユニットテストの追加
コードのドキュメント化
リファクタリング
その他
探索するのではなく作成することはできないか
巨大な数を探す方法はないだろうか
完全な約分パターンを探そう(結果が既約分数)
これらの、改善を通じてよりプログラミングへの理解が深まると思います。このあたりに必要なプログラミング技術は、また別の題材で紹介することもあるでしょう。
まとめ
たまたま見つけたジョーク約分を見て、そのパターン探しためのプログラムを作成しました。
最初は、整数と文字を相互に変換するだけのプログラムを紹介するつもりでしたが、適当に手をいれるうちに、多くのプログラミング要素を含むいい教材プログラムになりました。
みなさんも、面白い情報を見かけたら、似たようなものを探してみるプログラムをかいてくださいね。
ハッシュタグ
#python #プログラミング #初心者 #int #str #文字列 #スライス #アルゴリズム #探索 #重複 #構造化 #関数 #エラー処理 #try #except #入力チェック #コマンドラインオプション #argparse
#約分 #ジョーク