
長文を処理する新しい概念CoA/googleが提唱

長文を処理する新しい概念CoA/googleが提唱
https://openreview.net/pdf?id=LuCLf4BJsr
こんにちはmakokonです。
googleから長文コンテキストタスクにアクセスするための新しい概念として「CoA(Chain of Agents)」が提唱されました。
複数のエージェントがテキストを分割して処理し、情報を段階的に統合することで、従来のRAGや長文対応LLMを上回る性能を示します。この手法は、訓練不要でタスク・長さ非依存、解釈可能かつ計算コスト効率が良い点が特徴です。
特に既存のマルチエージェントシステムMergeやHierarchicalとは異なり、エージェント間の連携が生む効果の比較が面白いものでした。
論文とブログの両方を参考にしながら紹介したいと思います。
説明は、図表に合わせて極力定性的にしたいと思います。(いつもそうですね)
詳しい話に踏み込みたい人は、ぜひ原文を読んでください。資料が非常に充実しています。(この記事は大体の説明ですからね)
CoAはなんのための技術ですか。
Chain-of-Agents (CoA) は、大規模言語モデル(LLM)が長文のコンテキストを効果的に処理するための技術です。
CoAのアーキテクチャ
長文コンテキストの理解の向上: LLMは、入力トークン数の制限により、長文の情報を一度に処理することが困難です。CoAは、長文を複数のチャンクに分割し、それぞれを異なるエージェントに処理させることで、LLMが長文全体を理解できるようにします。
情報集約と文脈推論の促進: 各ワーカーエージェントは、担当するチャンクの情報を処理し、前のエージェントからの情報を引き継ぎながら、次のエージェントに情報を伝達します。この連鎖的なコミュニケーションによって、情報が集約され、文脈に沿った推論が可能になります。
図1 (論文): CoAのアーキテクチャを示す図で、ワーカーエージェントが連鎖的にコミュニケーションを行い、最後にマネージャーエージェントが結果を統合する様子を表しています。これは、長文を分割して処理する分散型のプロセスを示しており、従来のLLMが抱える長文コンテキストの処理における課題を解決するアプローチであることが理解できます。

なぜこの技術が重要なのですか
CoAはLLMが長文のコンテキストを効果的に理解し、複雑な推論を実行するための重要な技術であると言えます。特に、情報過多な現代社会において、長文のテキストを効率的に処理し、必要な情報を抽出する能力は、個人や組織にとって非常に価値があると考えられます。
技術的な観点からは、Chain-of-Agents(CoA)技術が重要な理由は、主に以下の点に集約されます。
長文コンテキスト処理におけるLLMの限界克服: 大規模言語モデル(LLM)は、テキストの長さに制限があり、長文の情報を効果的に処理することが困難です。
情報集約と複雑な推論の実現: 各ワーカーエージェントは、前のエージェントからの情報を引き継ぎながら、次のエージェントに情報を伝達します。この連鎖的なコミュニケーションを通じて、情報が集約され、文脈に基づいた推論が可能になります。
「lost-in-the-middle」問題の軽減: 長文のコンテキスト入力に対する「lost-in-the-middle」問題を効果的に軽減し、長文全体にわたって情報を均等に活用できます。
その他 以下のような重要な効果が指摘されています。
多様なタスクへの適用性:
効率性とコスト効果:
解釈可能性の向上:
長文LLMとの比較における優位性:
どんな効果がありましたか
Chain-of-Agents (CoA) 技術によって、主に以下の効果が得られました。
長文コンテキストタスクにおける性能の大幅な向上:(表4)
質問応答タスク:
表4に示されているように、HotpotQA、MuSiQue、NarrativeQA、Qasper、QuALITYといった質問応答データセットにおいて、CoA(8k)はVanilla(8k)およびRAG(8k)モデルを大幅に上回る性能を示しています。特に、text-bisonモデルでは、NarrativeQAで13.30%、MuSiQueで12.82%、QuALITYで22.00%の向上が見られます。
要約タスク:
表4 に示されるように、QMSum、GovReport、BookSumといった要約タスクにおいても、CoA(8k)はVanilla(8k)および(32k)のベースラインモデルを上回っています。注目すべき点として、GovReportでは、RAGが擬似クエリを使用しても性能が改善しなかったのに対し、CoAは大幅な性能向上を達成しています。これは、CoAがクエリベースではないタスクにも適用可能であることを示しています。
コード補完タスク:
表4 に示されるように、RepoBench-Pデータセットにおいて、CoA(8k)はベースラインモデルよりも高いコード類似性スコアを達成しました。

長文LLMとの比較における優位性:(表5、図2)
表5に示されているように、Claude 3(Haiku, Sonnet, Opus)のような長文LLMと比較しても、CoA(8k)は同等以上の性能を発揮しました。特に、NarrativeQAおよびBookSumデータセットでは、CoA(8k)がVanilla(200k)よりも優れた性能を達成しました。この結果は、LLMのコンテキストウィンドウの長さだけでなく、情報の処理方法も重要であることを示唆しています。
図2 は、BookSumにおけるClaude 3の性能を示しており、入力長が長くなるにつれて、CoAの性能が向上し、Vanilla(200k)に対する改善幅も拡大していることがわかります。


「lost-in-the-middle」問題の軽減:
図4 は、「lost-in-the-middle」現象の評価結果を示しています。Vanillaモデルがこの問題の影響を強く受けているのに対し、CoAはより少ない性能低下幅を示しており、この問題を効果的に軽減していることがわかります。これは、CoAが各エージェントに短いコンテキストを割り当てることで、長文全体にわたって情報を均等に活用できるためです。

複雑な推論の実現:
(アブスト読んだときにこの効果がよくわかっていなかった)
図5 は、HotpotQAにおけるRAGとCoAのケーススタディを示しています。RAGはセマンティックな類似性に基づいてテキストチャンクを検索しますが、多段階の推論には不向きです。一方、CoAは、各エージェントが前のエージェントからの情報を引き継ぎながら推論を進めるため、複数ホップの推論を必要とする複雑な質問にも対応できます。

解釈可能性の向上:
図1 のように、CoAは複数のエージェントが連携して情報を処理するため、各エージェントの処理過程を追跡でき、LLMの推論過程が解釈しやすくなります。
RAGが失敗した場合の性能向上:
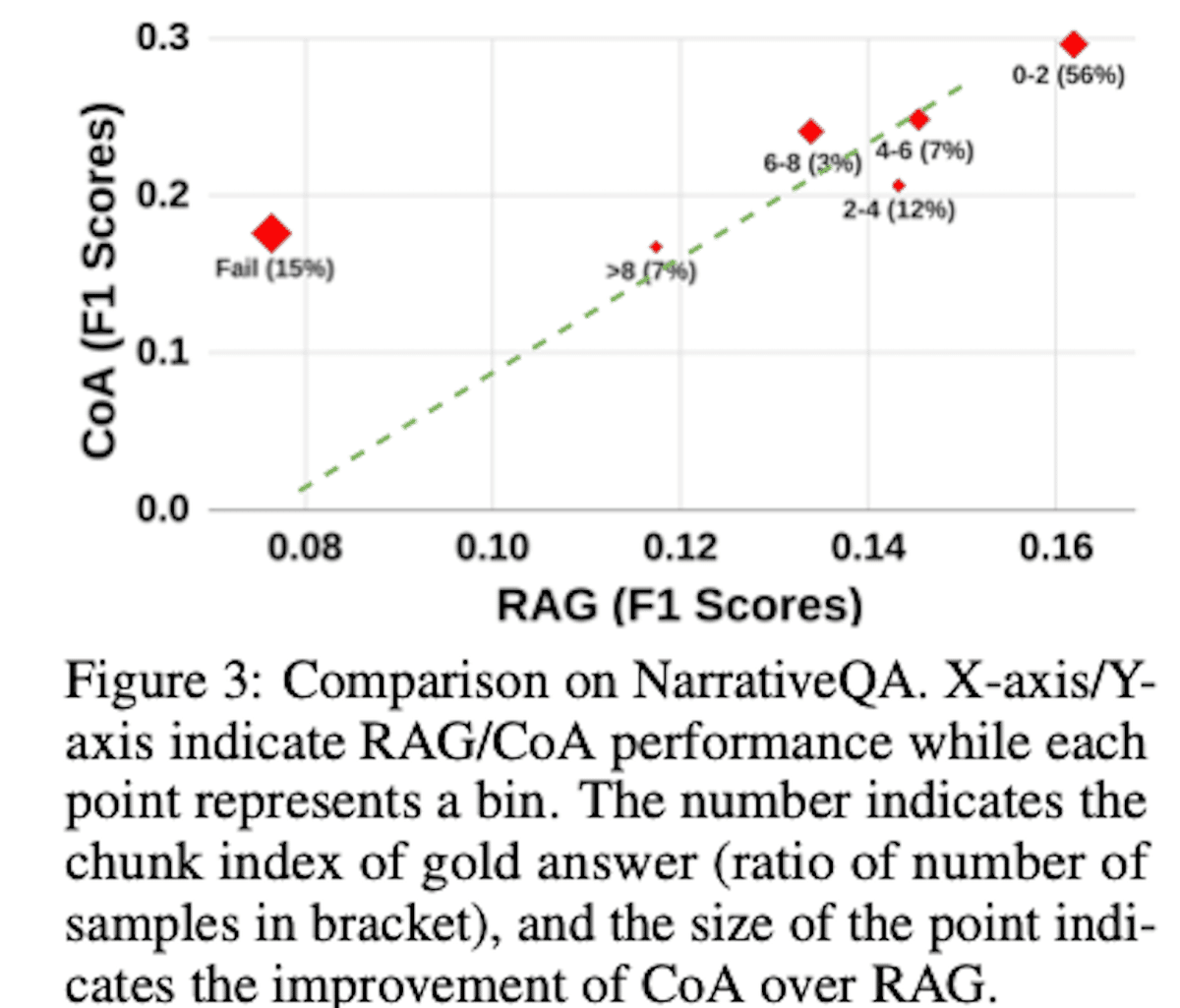
(失敗したときのことを比較しているのが珍しい。アプリによってはRAGの失敗が許されないこともあるしね。)図3 は、NarrativeQAデータセットにおけるRAGとCoAの性能比較を示しています。RAGがゴールドアンサーを含むチャンクをうまく検索できた場合は、CoAとの性能に相関が見られます。しかし、RAGが失敗した場合、CoAはRAGよりも大幅に性能を向上させることができ、RAGの検索精度に依存せずより堅牢な性能を発揮することがわかります。
情報損失の低減
表10に示されるように、Chain of Agents での情報伝播中の情報損失は、1%〜4%と少ないことがわかります。
これらの図表は、CoAの有効性を裏付ける重要な根拠となっています。特に、長文コンテキスト処理におけるLLMの課題を克服し、複雑な推論を可能にする点において、CoAは非常に価値のある技術であると言えるでしょう。
長文コンテキストタスクにおける性能の大幅な向上:
質問応答タスク: CoAは、HotpotQA、MuSiQue、NarrativeQA、Qasper、QuALITYなどのデータセットにおいて、従来のRAGやFull-Contextモデルと比較して大幅に優れた性能を示しました。例えば、NarrativeQAでは、text-bisonで13.30%、MuSiQueでは12.82%、Qualityでは22.00%の性能向上が見られました。
要約タスク: QMSum、GovReport、BookSumなどのデータセットにおいて、CoAはベースラインモデルを上回る性能を達成しました。特に、GovReportでは、RAGが擬似クエリを使用しても性能を改善できなかったのに対し、CoAは大幅な性能向上を示しました。
コード補完タスク: RepoBench-Pデータセットにおいて、CoAはベースラインモデルよりも高いコード類似性スコアを記録しました。
長文LLMとの比較における優位性:
Claude 3などの長文LLMと比較しても、CoAは同等以上の性能を示しました。特に、NarrativeQAおよびBookSumデータセットでは、CoA(8k)がFull-Context(200k)よりも優れた性能を発揮しました。これは、LLMのコンテキストウィンドウの長さだけでなく、情報の処理方法が重要であることを示唆しています。
「lost-in-the-middle」問題の軽減:
長文コンテキストにおいて、文脈の中間部分の情報を効果的に利用できない「lost-in-the-middle」問題に対して、CoAはより耐性があることが示されました。CoAは、各エージェントが短いコンテキストに焦点を当てることで、この問題を効果的に軽減します。
複雑な推論の実現:
複数のテキストチャンクにまたがる複雑な質問や、多段階の推論が必要なタスクにおいて、CoAは効果的に情報を集約し、推論を完了させることができました。
RAGのような単一のステップでの検索では困難な、複数ホップの推論を必要とする質問にも対応可能です。
解釈可能性の向上:
CoAでは、各エージェントの処理内容を追跡できるため、LLMの推論過程がより解釈しやすくなります。これにより、結果の信頼性を高め、LLMの挙動をより深く理解することができます。
効率性とコスト効果:
CoAは、Full-Contextアプローチと比較して時間計算量を削減し、より効率的に長文コンテキストを処理できます。
また、トレーニングを必要としないため、既存のLLMをそのまま活用でき、コストを抑えることができます。
RAGが失敗した場合の性能向上:
RAGがゴールドアンサーを含むチャンクをうまく検索できなかった場合でも、CoAは性能を大幅に向上させることができました。これは、CoAがRAGの検索精度に依存せず、より堅牢な性能を発揮することを示唆しています.
これらの効果は、様々なデータセットやLLMモデルを用いた実験によって実証されており、CoAが長文コンテキスト処理において非常に効果的な技術であることを示しています。特に、長文のテキストを効率的に処理し、複雑な情報を抽出する能力は、情報過多な現代社会において非常に重要であると言えます。
これらの効果を説明する対応する図表を指摘して、説明を修正してください。
今回利用した主な評価指標とデータセット
これらのデータセットと評価指標を用いて、Chain-of-Agents (CoA) の有効性が検証されています。
データセット:
質問応答 (Question Answering) タスク:
HotpotQA: Wikipediaに基づいたマルチホップ質問応答データセットで、複数の文章にまたがる推論が必要です。
MuSiQue: マルチホップ質問応答データセットで、HotpotQAよりも多くのホップ、回答不能な質問、より難しい妨害コンテンツが含まれます。
NarrativeQA: 書籍や映画のトランスクリプト全体を対象とした質問応答データセットで、抽象的、抽出的、Yes/No形式、および回答不能な質問が含まれます。
他にも、Qasper、QuALITYが用いられています。
要約 (Summarization) タスク:
QMSum: クエリベースの要約データセットで、学術会議や業界製品など、複数のドメインからの会議トランスクリプトで構成されます。
GovReport: 米国政府説明責任局が発行した長文レポートを含む汎用要約データセットです。
BookSum: 長文ナラティブ要約のためのデータセットコレクションで、小説、劇、物語などが含まれます。
コード補完 (Code Completion) タスク:
RepoBench-P: GitHubリポジトリから収集されたデータセットで、長いコードベースが与えられたときに、次のコード行を生成する必要があります。
評価指標:
質問応答タスク:
F1スコア: HotpotQA、MuSiQue、Qasperなど、抽出的な質問応答タスクで用いられます。
正確一致 (Exact match): QuALITYデータセットのような複数選択式の質問応答タスクで使用されます。
要約タスク:
ROUGEの幾何平均: 要約タスクで、生成された要約と参照要約の重複度を評価するために用いられます。
コード補完タスク:
コード類似性スコア: コード補完タスクで、生成されたコードと正解コードの類似性を測るために用いられます。
従来のマルチエージェントシステムと比較
Chain-of-Agents (CoA) は、従来のマルチエージェントフレームワーク(MergeやHierarchical)と比較して、複数の点で優れた性能を示しています。
Chain-of-Agents (CoA) は、MergeやHierarchicalとは異なり、CoAでは、ワーカーエージェントが連鎖的にコミュニケーションを行います。各ワーカーは前のワーカーからの情報を受け取り、その情報を基に自身の担当チャンクを処理し、次のワーカーに情報を伝達します。この連鎖的なコミュニケーションが、文脈を考慮した段階的な推論を可能にし、長文コンテキストを効果的に処理する上で重要な役割を果たします。
性能の比較:
表6 に示されているように、CoA は、HotpotQA、MuSiQue、NarrativeQA、Qasper、QuALITY、QMSum、GovReport、RepoBench-P のすべてのデータセットで、Hierarchical および Merge よりも優れた性能を発揮しています。

性能差の要因の理解
Merge(投票型):
各ワーカーエージェントは、与えられたチャンクに対して独立して推論を行い、最終的な答えを生成します。
すべてのワーカーエージェントが並行して処理を行い、相互にコミュニケーションは行いません。
最終的な答えは、多数決によって決定されます。つまり、最も多く生成された答えが最終的な答えとして選ばれます。
利点: 実装が比較的簡単で、各ワーカーの計算処理を並列化できるため、処理時間を短縮できる可能性があります。
欠点: 各ワーカーが独立して判断するため、文脈を考慮した段階的な推論や、エージェント間の情報共有が困難です。そのため、複雑なタスクや長文コンテキストを必要とするタスクでは、性能が低下する可能性があります。
Mergeは長文の要約タスクには特に効果的であることが示唆されていますが、他のタスクではVanillaモデルよりも性能が低い場合があります。
Hierarchical(階層型):
各ワーカーエージェントは、与えられたチャンクを独立して処理し、そのチャンクに有用な情報が含まれているかどうかを判断します。
有用な情報が含まれている場合、ワーカーエージェントはコミュニケーションユニット(CU)を生成します。
すべてのワーカーエージェントからのCUは、マネージャーエージェントに送られ、最終的な答えを生成します。
利点: 各ワーカーが事前に有用な情報を判断することで、マネージャーエージェントはより関連性の高い情報に基づいて答えを生成できます。
欠点: 各ワーカーは独立して処理を行うため、文脈を考慮した段階的な推論や、エージェント間の情報共有が制限されます。そのため、複雑なタスクや長文コンテキストを必要とするタスクでは、性能が低下する可能性があります。
HierarchicalはVanillaモデルよりも性能が向上する場合があるものの、Chain-of-Agents (CoA) には及ばないことが示されています。
ハッシュタグ
この論文「Chain of Agents: Large Language Models Collaborating on Long-Context Tasks」情報にアクセスするためのハッシュタグ
#ChainOfAgents
#マルチエージェントLLM
#長文コンテキスト
#LLMコラボレーション
#情報集約
#文脈推論
#分散型処理
#RAG超え
#インコンテキスト学習
#効率的LLM