
(論文)DeepSeekが学習技術を説明しているよ。

Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
こんにちは、makokonです。DeepSeek者は近頃多くの優秀なモデルを公開して、我々をわくわくさせてくれていますが、そのモデルの優秀さが、高速かつ安価なトレーニングによるものであると発表されています。
この論文は、そのトレーニングに関わる重要な技術「Fire-Flyer AI-HPC」の概要を紹介しています。以下のモデルはこの技術の恩恵を受けていることが確実ですが、最近のモデルもこれに基づく学習が重要な要素であると思われます。是非抑えておきましょう。極力定性的に紹介しますので、長い割には読みやすいかと。
DeepSeekMoE-16B:
LLaMa-13B:
DeepSeek-V2:
DeepSeekMath:
DeepSeek-VL:
DeepSeek-Coder-V2:
DeepSeek-Prover-V1.5:
これらのモデルは、Fire-Flyer 2 AI-HPCのハードウェアとソフトウェアの共同設計によって、効率的かつ安定的にトレーニングされています。
概要は?
この論文は、深層学習と大規模言語モデルのトレーニングのための費用対効果の高いAI-HPCアーキテクチャ「Fire-Flyer AI-HPC」を紹介しています。1万台のPCIe A100 GPUを用いたFire-Flyer 2は、DGX-A100と同等の性能を、コストを半分、消費電力を40%削減して達成しました。独自開発のソフトウェアスタック(HFReduce、HaiScale、3FS、HAI Platform)により、計算と通信のオーバーラップを実現し、スケーラビリティを向上させています。また、システムの安定性と堅牢性、そして将来のアーキテクチャについても論じています。
I. 導入 (INTRODUCTION)
AIの急速な進歩と、それに伴う計算リソースの需要の増大、そして、コストやエネルギー消費の問題が提起されています。これらの課題を解決するために、ハードウェアとソフトウェアの両面から最適化を図る必要性が強調されています。
図1は、ディープラーニング(DL)の発展に伴い、必要となる計算能力が指数関数的に増加していることを示しています。DLの進歩が、従来の計算能力の成長ペースを大きく上回っていることがわかります。
図2は、ハードウェアの性能向上、特にピークFLOPS(浮動小数点演算回数)と、メモリやインターコネクトの帯域幅の伸びを示しています。この図を見ると、AIの計算能力に対する要求が非常に速いペースで増加しているのに対し、ハードウェアの性能向上はそれに追いついていないことがわかります。
特に、メモリやインターコネクトの帯域幅の伸びは、計算能力の向上に比べて緩やかであり、このギャップがAIの発展におけるボトルネックとなっています。


II. 背景 (BACKGROUND)
コスト効率の高いAI-HPCシステムの構築が重要な課題であることを示す背景について説明しています。
AIモデルの巨大化に伴い、計算資源、エネルギー消費、コストなどの課題が増大しているため、ハードウェアとソフトウェアの協調設計による最適化が不可欠です。
図3 は、モデルのパラメータ数とアクセラレータメモリのサイズが、時間の経過とともに急速に増加していることを示しています。特に、TransformerモデルやGPTシリーズなどの大規模言語モデル(LLM)は、従来のモデルと比較して非常に大きなメモリ容量を必要とします。これは、モデルの複雑化と大規模化が、AIの進化を加速させている一方で、計算資源への要求を増大させていることを意味します。この図は、AIモデルが大きくなるにつれて、必要なメモリも指数関数的に増加している状況を視覚的に表しています。

モデルの巨大化に対応するために、多数のGPUを使用する必要性などが強調されています。大規模なAIインフラストラクチャ構築の必要性を示唆しています。さらに、DLトレーニングのコストが増大が指摘され、特に、LLMのトレーニングに必要な計算能力は、従来のHPCアプリケーションを上回っていると指摘されています。
その他のコンピューティングシステムの紹介もありますが、いずれにしても必要なトレーニングに対し、性能が追いつかないか、膨大なコストが必要になることが指摘されています。
III. Fire-Flyer 2:ディープラーニングと初期LLMトレーニングへのアプローチ
ここでは、Fire-Flyer 2は、PCIe A100 GPUを使用し、コスト効率とエネルギー効率を重視したアーキテクチャであることを説明しています。また、初期のLLMトレーニングニーズにも対応できる柔軟性も備えています。これらの設計により、DGX-A100と同等の性能を、より低いコストとエネルギー消費で実現することを目指しています。
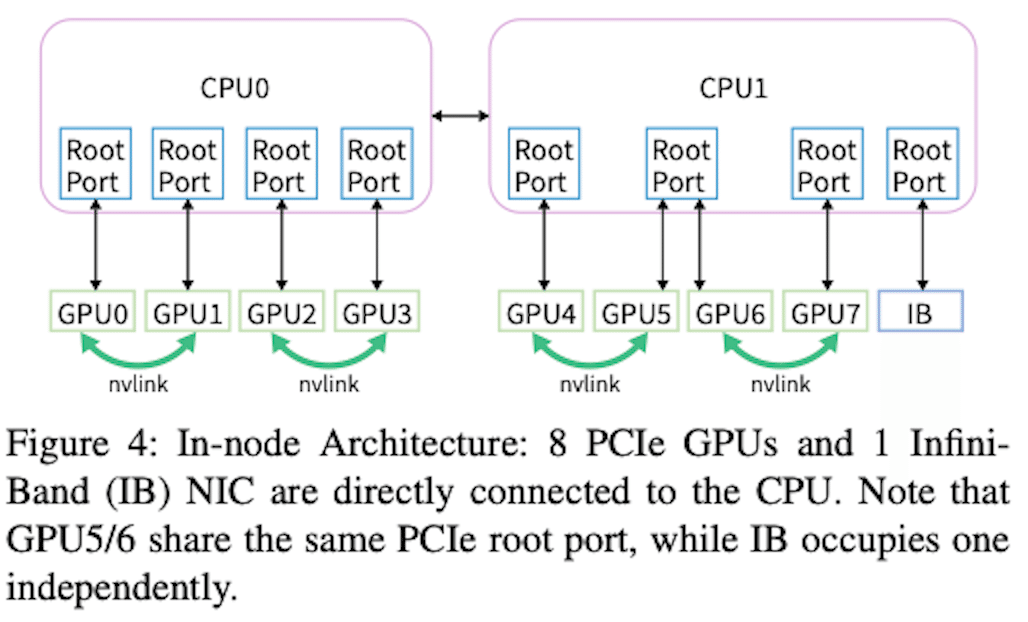
Fire-Flyer 2のPCIe A100 GPUアーキテクチャ
図4は、ノード内アーキテクチャを示しており、8つのNVIDIA A100 PCIe GPUと1つのMellanox CX6 200Gbps InfiniBand(IB)NICが、PCIeスイッチを使用せずにCPUに直接接続されていることがわかります。
IB NICは、独立したPCIeルートコンプレックスを使用しており、GPUとの性能干渉を避けています。
NVLink Bridgeを追加する可能性も設計に組み込まれており、LLM時代への対応も考慮されています。
表Iでは、Fire-Flyer 2のアーキテクチャの詳細とNVIDIAの標準的なDGX-A100サーバーとの比較が示されています。この表から、Fire-Flyer 2は、CPU、メモリ、GPU、NICの構成がDGX-A100とは異なることがわかります。

ネットワークトポロジー
図5は、Fire-Flyer 2が採用している2層ファットツリーネットワークトポロジーを示しています。このトポロジーは、高いバイセクション帯域幅を持つため、AI-HPCや高スループットストレージ環境に適しています。
コスト削減のため、3層ではなく2層構成。
2つのゾーンに分割、各ゾーンは約600個のGPU計算ノードに接続
ストレージサーバーは、異なるゾーンに接続された2つのIB NICを備えており、全てのGPU計算ノードがストレージサービスを共有できます。
2つのゾーンは限られたリンクで相互接続
HAI Platformのスケジューリング戦略により、ゾーンを跨ぐ計算タスクは最大でも1つに制限

表IIでは、A100 PCIeとDGX-A100の性能比較が示されています。PCIe A100は、DGX-A100と比較して、TF32とFP16のGEMMベンチマークで約83%の性能を達成しています。しかし、コストとエネルギー消費は大幅に削減されており、GPUコストは60%、エネルギー消費は40%に抑えられています。
表IIIでは、ネットワークのコスト比較が示されています。Fire-Flyer 2のアーキテクチャは、DGX-A100クラスタに必要なスイッチ数よりも大幅に少ないスイッチ数で構成されており、ネットワークコストを大幅に削減しています。また、同様の規模の3層ファットツリーネットワークと比較しても、40%のネットワークコスト削減が実現されています。


IV. HFReduce:ネットワークにおけるハードウェアとソフトウェアの協調設計 (HFREDUCE: HARDWARE SOFTWARE CO-DESIGN IN NETWORK)
ここでは、HFReduceは、ハードウェアの制約をソフトウェアで克服し、PCIeアーキテクチャにおける効率的な全削減処理を実現していることを説明しています。NVLinkの導入により、さらなる性能向上が期待されますが、メモリ帯域幅やPCIeルートコンプレックスポートなどの課題についても指摘しています。その主な特徴は、
GDRCopyを使用して、D2H転送時の小規模データ転送を高速化し、ホストメモリからの読み取りを削減します。
CPUはSIMD命令を使用して、FP32、FP16、BF16、FP8などのデータ型をサポートします。
NUMAを意識した設計で、D2Hの転送先メモリを2つのNUMAノードにインターリーブし、レイテンシを最小化しています。
ノード間削減には、ibverbs RDMA Writeを通じてダブルバイナリーツリーの全削減アルゴリズムを実装し、オーバーヘッドを回避しています。

HFReduceの基本的な動作原理
図6は、HFReduceの基本的な動作原理を示しています。HFReduceは、ノード内での削減処理を先に行い、その後でノード間の全削減処理を行うという2段階のアプローチを採用しています。各ノード内のGPUで計算された勾配データがCPUに転送され、そこで削減処理が行われた後、結果が再びGPUに転送されます。

HFReduceのアルゴリズムをもう少し詳しく見るならば、
アルゴリズム1は、ノード内削減のステップを示しています。
まず、GPU上の勾配データがCPUメモリに非同期的に転送されます。
次に、CPU上でベクトル命令を用いて削減加算処理を行います。
アルゴリズム2は、ノード間削減のステップを示しています。
ダブルバイナリーツリーアルゴリズムを用いてノード間の全削減処理を行います。
最後に、削減された勾配データがCPUからGPUへPCIe経由で返送されます。 この際、CPUからGPUへの転送には、GDRCopyを利用することで、ホストメモリからの読み取り回数を削減しています。


HFReduceの性能
HFReduceとNCCLの比較
図7aは、HFReduceとNCCLの全削減時のノード間帯域幅を比較したものです。この図から、HFReduceはNCCLよりも高い帯域幅を達成していることがわかります。
HFReduceはPCIeの帯域幅消費を削減し、GPUカーネルのオーバーヘッドもありません。
NCCLのリングトポロジーでは、各データユニットが2n-1回の伝送を行う必要があるのに対し、HFReduceは1回のD2H(Device-to-Host)転送と1回のH2D(Host-to-Device)転送のみを必要とするためです。
NVLinkブリッジを導入した場合のHFReduceの性能
図7bは、NVLinkブリッジを導入した場合のHFReduceの性能を示しています。
NVLinkを活用したHFReduceは、さらに高いノード間帯域幅を達成しています。
NVLinkを介してGPU間で削減処理を先に行い、その結果をCPUに渡すことで、メモリボトルネックを緩和

V. HaiScale:ディープラーニングモデルのトレーニング向け最適化 (HAISCALE: SPECIAL OPTIMIZATION FOR DEEP LEANING MODELS TRAINING)
HaiScaleは、PCIeアーキテクチャにおけるディープラーニングモデルの効率的な学習を可能にするソフトウェアフレームワークであり、特に、
HFReduceをバックエンドとして活用し、通信と計算のオーバーラップを最大化
LLMトレーニングにおける様々な並列化戦略のサポートと最適化
メモリ管理の最適化と通信オーバーラップによるFSDPの高速化 などの特徴を有しており、これらの最適化により、高い並列効率とスケーラビリティを達成しています。
HaiScaleの主要な特徴は、ディープラーニングモデルのトレーニングを最適化するために、さまざまな並列化戦略を実装している点です。特に、PCIeアーキテクチャに特化した最適化が施されており、HFReduceを通信バックエンドとして利用することで、高い効率性を実現しています。
図8aは、HaiScale DDPとPyTorch DDPのVGG16モデルの学習における性能を比較
HaiScale DDPはPyTorch DDPよりも大幅に高速
HaiScale DDPがHFReduceをバックエンドとして使用し、勾配のallreduce処理をバックプロパゲーションの計算とオーバーラップさせることで、通信の待ち時間を短縮
HFReduceがGPUのストリーミングマルチプロセッサ(SM)に依存しないため、完全に非同期なallreduceが可能
図8bは、HaiScale FSDPとPyTorch FSDPのGPT2-mediumモデルの学習における性能を比較
ZeRO Stage-3アルゴリズムをベースに実装
メモリ管理を最適化
モデル調整時のフラグメンテーションを低減
allgatherとreduce-scatterの通信をフォワードおよびバックワード計算とオーバーラップ
最適化ステップを分割することでオーバーラップを強化
HaiScale FSDPはPyTorch FSDPよりも高い並列スケーラビリティを達成

トレーニングにおける並列化戦略
HaiScaleは、大規模言語モデル(LLM)のトレーニングにおいても、様々な並列化戦略をサポートしています。
データ並列化(DP):データ並列化は、モデルとオプティマイザの状態を複数のデバイスに複製し、データを均等に分散する方法です。大規模言語モデルのトレーニングでは、Zero Redundancy Optimizer(ZeRO)を用いて、これらの状態を各データ並列プロセスでシャーディングし、パラメータのフェッチや勾配計算のためにallgatherやreduce-scatterを使用します。
パイプライン並列化(PP):パイプライン並列化は、モデルの層を各デバイスに分割し、トレーニングバッチをマイクロバッチに分割してパイプライン実行する方法です。効率的なスケジューリング戦略により、「パイプラインバブル」を最小限に抑える必要があります。
テンソル並列化(TP):テンソル並列化は、モデル層を複数のGPUに配置し、並列に計算を行う方法です。入力の分割と出力のマージにallgatherやall2allが必要となります。
エキスパート並列化(EP):MoE(Mixture-of-Experts)モデルのトレーニングでは、異なるエキスパートモデルを異なるGPUに分散します。ゲートモデルが入力中にトークンを選択し、対応するトークンをall2all通信でエキスパートモデルに送信します。
Fully Sharded Data Parallel(FSDP):FSDPは、ZeRO Stage 3アルゴリズムに基づいており、モデルのパラメータ、オプティマイザの状態、勾配をパーティション分割し、各GPUに1/nだけ保持します。フォワードプロパゲーション時には、allgather操作で完全なパラメータを組み立て、フォワードパスが完了後に解放します。バックワードプロパゲーション時にも、allgather操作で完全なパラメータを取得し、バックワード計算を行って勾配を計算し、reduce-scatter操作で勾配を同期させます。
図9aは、LLaMa-13Bモデルをトレーニングする際の、GPU数に対するステップ時間の変化を示しています。この図から、GPU数を増やすにつれてステップ時間が減少しており、高い並列効率を達成していることがわかります。特に、NVLinkブリッジを導入することで、PCIe GPU間のテンソル並列処理がより効率的に行えるようになっています。
図9bは、DeepSeekMoE-16Bモデルをトレーニングする際の、GPU数に対するステップ時間の変化を示しています。この図からも、GPU数を増やすにつれてステップ時間が減少しており、優れたスケーラビリティを発揮している。

VI. 高度なコスト効率と協調設計の最適化 (ADVANCED COST-EFFECTIVE AND CO-DESIGN OPTIMIZATIONS)
ここでは、Fire-Flyer AI-HPCシステムにおいて、コスト効率を高めつつ、性能を最大限に引き出すための高度な最適化について説明しています。
特に、ネットワークの輻輳を最小限に抑えるための設計と、高スループットな分散ファイルシステムに関する説明がありますが、特に具体的な数値効果が殆ど無いので項目のみ紹介します。
A. 計算・ストレージ統合ネットワークにおける輻輳の最小化
異なる種類のトラフィック間の干渉を分離し、ネットワークの輻輳を制御するための対策です。
トラフィックの分離: 異なる種類のトラフィック(HFReduce通信、NCCL通信、3FSストレージトラフィック、その他のトラフィック)をInfiniBandのサービスレベル(SL)技術を用いて分離
トポロジ調整と経路最適化: 大量のストレージトラフィック対策として、静的ルーティング戦略を採用
NCCLの最適化: NCCLのトポロジを調整し、IB NICと同一NUMAノード内のGPUを経由するようにルーティング
3FSにおけるネットワークチューニング: ストレージサービスとクライアント間のリクエスト送信制御メカニズムを実装
B. 高スループット分散ファイルシステム: 3FS
NVMe SSDのIOPSとスループット、およびRDMAネットワークを最大限に活用するように設計された、内製の高性能分散ファイルシステムです。
3FSのストレージノード: 各ストレージノードには、16個のPCIe 4.0 NVMe SSDと2つのMellanox CX6 200Gbps InfiniBand HCAが搭載
合計で、システムは9TB/sの帯域幅を提供可能。
3FSの主要な技術ポイント:
クラスタマネージャー、メタサービス、ストレージサービス、クライアントの4つの役割で構成
メタデータは、分散キーバリューストレージシステムに保存
CRAQ(Chain Replication with Apportioned Queries)の実装
ストレージネットワークは、完全な二分帯域幅を提供するファットツリートポロジーを採用
ストレージサービスとクライアントの間でリクエスト送信制御メカニズムが実装
C. HAIプラットフォーム: タイムシェアリングスケジューリングプラットフォーム
ユーザーが複数のGPUを同時に利用して並列トレーニングを行うことを推奨し、99%の利用率を促進しています。
クラスタリソース管理にタイムシェアリングの原則を適用
ユーザーがタスクを送信すると、プラットフォームは現在のリソース要件やクラスタの稼働状況に応じてタスクを中断およびロードします。
タスクのコードは、中断からの再開を可能にするためにプラットフォームのコーディングルールに従う必要があります。
VII. 安定性と堅牢性 (STABILITY AND ROBUSTNESS)
ここでは、システム全体の安定性を維持するための様々な対策が講じられていることを説明しています。具体的には、チェックポイントマネージャーによる迅速な復旧、バリデーターによる障害の早期発見、ハードウェア障害の特性分析と対応などです。これらの対策により、Fire-Flyer AI-HPCシステムは、大規模なAIトレーニング環境で安定した運用を実現しています。
A. チェックポイントマネージャー
LLM(大規模言語モデル)のトレーニングは数ヶ月に及ぶ場合があり、その間にはハードウェアの故障が避けられません。このため、トレーニングの中断からの復旧時間を最小限に抑えるためにチェックポイントマネージャーが開発されました。具体的には、ハードウェア障害によるトレーニング中断時には、直近の5分間の進捗のみが失われます。
巨大なLLMチェックポイントの効率的な保存とロードのために、3FSの高スループットが活用されます。
チェックポイントの保存は、パラメータと最適化状態をチャンクに分割し、3FSバッチ書き込みAPIを使用して高速に行われます(1ノードあたり10GiB/s以上)。
GPUからCPUホストメモリへのパラメータと最適化状態の非同期転送が行われ、チェックポイントの保存は定期的に実行されます。
各テンソルは、チェックポイント内のインデックスとオフセットとともに記録され、ロードプロセス中の場所の特定を容易にします。3FSバッチ読み込みAPIにより、ロードプロセスも高速に完了します。
B. バリデーター
デバイスの安定性を向上させるためには、問題が発生する前に特定することが重要です。このため、ハードウェアが正しく機能しているかを検証するためのバリデーターツールが開発されました。このことにより、障害のあるノードはスケジューリングプラットフォームから削除され、スケジュールされたノードはすべて動作することが保証されます。
プラットフォームの自動運用・保守システムは、ノードの正常な機能を検証するためにバリデータープログラムを毎週実行します。
バリデーターは、ハードウェアの周波数、リンク速度、リンク状態の確認、CPU負荷テスト、メモリ帯域幅テスト、GPUメモリテスト、GPUチップの動作ロジックテスト、ノード内allreduceテスト、ストレージ帯域幅ストレステストなどを行います。
C. Fire-Flyer 2 AI-HPCにおけるハードウェア障害の特性
この部分は、実際の運用で発生したハードウェア障害の種類とその原因について分析した結果を述べています。
GPU Xidエラー: NVIDIAドライバーから発生する一般的なGPU障害メッセージであるXidエラーを分類し、原因を分析しています。
NVLinkエラー (Xid 74) が最も多く、これはNVLinkブリッジコネクタの固有の障害率が高いためです。
ソフトウェア関連のエラー (Xid 13, 31, 43, 45) は、ユーザーコードにおける不正なメモリアクセスや命令を示唆しますが、ハードウェアの故障も考慮する必要があります。
GPUメモリECCエラー (Xid 63, 64, 94, 95) は、GPUがメモリECCエラーを処理する際に発生し、GPUのリセットで解決できる場合が多いです。
修正不能なGPU障害 (Xid 44, 48, 61, 62, 69, 79) は、GPU上で修正不能なエラーが発生したことを意味し、GPUのリセットまたはノードの再起動が必要です。
その他の障害 (Xid 119) は、GPU GSPモジュールの障害を意味し、フィールド診断テストとRMA(返品承認)が必要な場合があります。
ネットワークフラッシュカット: CPUやGPUの障害に加えて、ネットワークデバイスの誤動作も重要なハードウェア問題です。IBリンクの障害はアプリケーションの通信中断やタスクの失敗につながる可能性があります。
図10と図11
図10は、過去6ヶ月間のメモリとネットワークの障害傾向を示しており、GPU ECC障害がCPUよりも頻繁に発生していることを示しています。
図11は、過去1年間のIBネットワーク障害データを示しており、リンクのフラッシュカットがクラスタの運用期間を通じてランダムに発生する可能性があることを示しています。


図表に即して 考察 (DISCUSSION)部分を説明してください。説明に数値は極力使用せずに、定性的に説明してください。対応する図表がない部分はごくごく簡潔に説明してください。
VIII. 考察 (DISCUSSION)
ここでは、RDMAネットワークにおける輻輳制御の課題、NVLink技術の導入判断、メンテナンスコスト、他のアーキテクチャと比較した安定性について、実際の運用経験に基づいた考察が述べられています。特に、コスト効率と性能のバランス、およびシステムの安定性が重要な検討事項であることが強調されています。
A. RDMAネットワークにおける輻輳制御に関する考察
ロスレスRDMAネットワークは、PFC(Priority Flow Control)やクレジットベースのフロー制御などのメカニズムを提供します。
IB NICは、輻輳制御アルゴリズムとしてDCQCN (Data Center Quantized Congestion Notification) を使用しますが、このシステムではDCQCNを無効化しています。
これは、HFReduceトラフィックと3FSストレージトラフィックの両方を同時にサポートするパラメータを見つけることができなかったためです。
B. NVLink技術の選択に関する考察
当初、コストと安定性の観点からNVLinkを使用していませんでした。当時のトレーニング要件にはHFReduceで十分だったためです。
しかし、LLMの需要が増加したため、LLMトレーニング専用にNVLinkを追加しました。
NVLinkの導入は、潜在的な欠点も考慮して、実際のニーズに基づいて決定する必要があるとしています。
C. メンテナンスコストの概要
構築コスト: ハードウェアコストは表IIとIIIに記載されています。ソフトウェアコストは、数十人の社内開発者によって貢献されていますが、数千台のGPUサーバーのコストのごく一部です。
消費電力: ResNetトレーニング中の平均消費電力比較は表IIに記載されています。IBスイッチや他のノードのオーバーヘッドを含め、Fire-Flyer 2 AI-HPCの総消費電力は4MWを超えず、約3MW強です。
運用コスト: 消費電力とラックレンタルコストを考慮して見積もることができます。この数値にノード数とPUE(電力使用効率)を掛けることで、総運用コストを計算できます。
D. 他のアーキテクチャとの比較における安定性
ある論文では、NVLink関連の障害が全障害の約52.42%を占めていると報告されています。
このシステムでは、NVLink関連の問題(主にXid-74エラー)がGPU障害の約42.57%を占めています。
IX. 今後の展望 (FUTURE WORK)
次世代PCIeアーキテクチャの設計について述べ、MoE LLMトレーニングをターゲットとした、GPUとNICの1対1の比率、マルチプレーンネットワーク、RoCEスイッチの採用を提案します。
X. 結論 (CONCLUSIONS)
Fire-Flyer 2 AI-HPCの導入と運用経験から得られた教訓をまとめ、そのコスト効率とパフォーマンスを強調します。
ハードウェアとソフトウェアの協調設計、およびネットワーク最適化の重要性を再確認します。
Fire-Flyer 2 AI-HPCが、コスト効率の高いAI-HPCクラスター構築を目指す他の研究者にとって、有益な参考になることを期待します。
ハッシュタグ
効率的な学習