(論文紹介)日本語マルチモーダルQAデータセット。JDocQA: Japanese Document Question Answering Dataset for Generative Language Models

こんにちはmakokonです。面白そうなLLM用の日本語データセットが公開されているようなので、論文を読んでみました。この記事は、基本的に元論文にある内容、図表から構成されています。
JDocQAは、視覚と言語の両方の情報を活用する日本語の質問応答データセットです。Yes/Noから自由回答まで多様な質問に対応し、特に文書中に明示的な回答がない質問も含むことで、AIの幻覚を抑制する効果が確認されています。実用的なアプリケーションでの活用が期待される新しいデータセットです。
GPT-4やInstructBLIPなど、最新マルチモーダルモデルとの高い適合性についても検討中です。
JDocQA: Japanese Document Question Answering Dataset for Generative Language Models
概要
日本語の文書に基づく大規模な質問応答データセット
視覚情報とテキスト情報の両方を必要とするタスクに対応
PDF形式の5,504の文書
11,600の質問応答インスタンス
文書ページの参照と回答の手がかりとなるバウンディングホックスを含む
多岐にわたるカテゴリー日本語特有の書式(左右横書きと上下縦書き)の理解も求められます。
回答不可能な質問を取り入れることで、LLMの生成中にしばしば見られる幻覚を軽減することができるかも。
なお、データセット本体はこちらから
shunk031/JDocQA · Datasets at Hugging Face
import datasets as ds
dataset = ds.load_dataset(
path="shunk031/JDocQA",
# Rename to the same wording as in the paper: Document -> Report / Kouhou -> Pamphlet
rename_pdf_category=True,
# Set to True to use loading script for huggingface datasets
trust_remote_code=True,
)
print(dataset)
# DatasetDict({
# train: Dataset({
# features: ['answer', 'answer_type', 'context', 'multiple_select_answer', 'multiple_select_question', 'no_reason', 'normalized_answer', 'original_answer', 'original_context', 'original_question', 'pdf_category', 'pdf_name', 'question', 'question_number', 'question_page_number', 'reason_of_answer_bbox', 'text_from_ocr_pdf', 'text_from_pdf', 'type_of_image', 'pdf_filepath'],
# num_rows: 9290
# })
# validation: Dataset({
# features: ['answer', 'answer_type', 'context', 'multiple_select_answer', 'multiple_select_question', 'no_reason', 'normalized_answer', 'original_answer', 'original_context', 'original_question', 'pdf_category', 'pdf_name', 'question', 'question_number', 'question_page_number', 'reason_of_answer_bbox', 'text_from_ocr_pdf', 'text_from_pdf', 'type_of_image', 'pdf_filepath'],
# num_rows: 1134
# })
# test: Dataset({
# features: ['answer', 'answer_type', 'context', 'multiple_select_answer', 'multiple_select_question', 'no_reason', 'normalized_answer', 'original_answer', 'original_context', 'original_question', 'pdf_category', 'pdf_name', 'question', 'question_number', 'question_page_number', 'reason_of_answer_bbox', 'text_from_ocr_pdf', 'text_from_pdf', 'type_of_image', 'pdf_filepath'],
# num_rows: 1176
# })
# })
関連研究
マルチモーダル質問応答データセット
視覚的質問応答(VQA)
画像などの視覚的コンテキストに基づいてテキストクエリに応答するタスク
さまざまなメディア形式をカバー
特に、文書VQAは、実世界の画像に埋め込まれたテキストを対象
視覚的およびテキスト的な両側面から文書を総合的に理解するために注目OCR-VQA、TextVQA、DocVQA、VisualMRC、WebSRC、InfographicVQAなどが公開されている
これらの多くが単一画像に基づくVQA
各質問応答ペアに対して関連する情報を含む単一の画像が存在マルチイメージVQA
スライドや文書を理解するためには、複数のページやチャートを理解する能力がより実用的で必要になる。
MultiModalQA、MP-DocVQA、SlideVQA
文書質問応答において、Universal Document Processing(UDOP)が提案
視覚、テキスト、レイアウトを統合するビジョンテキストレイアウトTransformer
文書全体の理解を一貫した方法で行うことが可能
日本語に関する研究
日本語版MS-COCOキャプションデータセット Miyazaki and Shimizu (2016)
日本語のテキスト含意データセット Yanaka and Mineshima (2022)
日本語のブログを基にしたQAデータセット Takahashi et al. (2019)
日本の大学入試のデータセット Miyao and Kawazoe (2013)
JGLUE (Kurihara et al., 2022)
データセットの作成
データセットの内訳


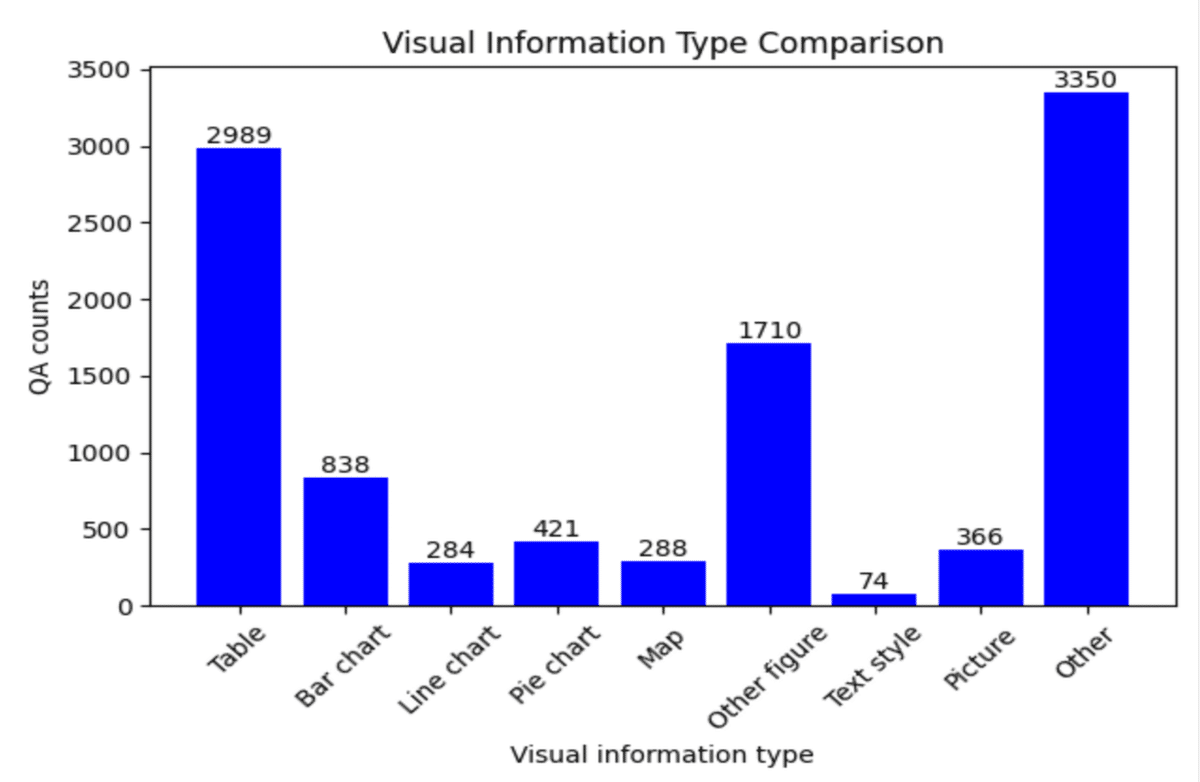
データセットの作成方法

PDFの収集
本の政府機関や地方自治体が作成した自治体のパンフレットやウェブサイトなどの公開文書PDFを手動で収集
経済政策、教育政策、労働問題、健康と衛生、農林水産、文化と芸術、歴史など広範なトピックをカバーしています。
図、表、チャート、写真、マンダラチャートなどの視覚要素も含まれる
形式に基づいてパンフレット、スライド、レポート、ウェブサイトの4つのカテゴリに分類
収集対象
日本国立国会図書館(NDL)のデジタルコレクション
ウェブアーカイブプロジェクト(WARP)
日本政府の省庁のウェブサイト
テキスト抽出と正規化
PDF文書からテキストをPyPDF2を用いて抽出
一部のPDF文書は文書ページの画像からOCR(光学文字認識)を用いてテキストを抽出
テキストの抽出またはOCRの後、誤って認識された記号や絵文字、または同じ文字が5回以上連続して繰り返し現れる場合は重複した文字を削除
注釈手順
合計43名の注釈者に文書の質問応答ペアの注釈を依頼
テキストおよび視覚要素(例:グラフ、チャート、地図、イラスト、縦書きと横書きの混在したテキスト)から、テキスト情報と視覚情報の両方に関連する質問応答ペアを作成
各文書に対して2~4つの質問応答の注釈
注釈プロセス中にOpenAI ChatGPTなどのAIツールを使用しない
複数のページにわたって複数のサポート事実を持つ質問のサブセットを、マルチページ質問として分類
マルチページ質問は、単一ページの質問と比べてかなり難しい
回答不可能な質問は、文書内にサポートする事実がないため、与えられた文書に基づいて回答することが不可能な質問
視覚的入力とバウンディングボックス
マルチモーダルモデルのために3種類の画像を用意。
異なるタイプの画像を利用することで、視覚情報が質問応答に与える影響を評価することができます。
全ページ画像: 注釈された質問応答ペアを含む文書の全ページの画像。
バウンディングボックスで切り取られた画像: 注釈者が回答の根拠とした表や図など、ページの特定部分をバウンディングボックスで切り取った画像。単一の質問応答ペアに複数のバウンディングボックスが注釈されている場合は、複数の切り取られた画像を一つの画像にまとめています。
白紙画像: アブレーションスタディに使用される白紙の画像。
データセットの特徴
Question-Answering(質問応答)
Question-Answering(質問応答)タスクに関するデータセットの説明。
このデータセットは、文書の文脈(テキストおよび視覚情報)に基づく質問応答能力を評価することを目的としています。
質問タイプ(4種類)
Yes/No質問
事実関連質問(factoid)
数値関連質問
自由回答式質問
回答形式
すべての質問タイプでオープンエンド形式のテキスト生成による回答
各質問タイプに応じた回答フォーマットのガイドラインを提示
"Yes/No形式で回答してください"
"文書で言及されている事実を回答してください"
"文書から数値情報で回答してください"
"自由形式で回答を記述してください"
特殊な機能
文書のみでは回答できない質問(unanswerable questions)を含む
回答不能な質問に対する統一的な回答:
"本文中に記載がありません"
入力データ
テキストデータ(埋め込みテキストまたはOCR結果)
質問文
回答フォーマットのガイドライン
Models
モデル実験の設定に関する説明。
実験は教師あり学習(supervised finetuning)で実施され、トレーニングセットとバリデーションセットで最適なハイパーパラメータを探索した後、そのパラメータでモデルの性能を評価しています。
テキスト入力モデル
最大13B(130億)パラメータの日本語LLMを使用
使用モデル:
rinna japanese-gpt2-medium
japanese-gpt-4B-8k
rinna japanese-gpt-1B
OpenCALM-7B
weblab-10b
PLaMo-13B
Japanese-StableLM-Base/Instruct-Alpha-7B
Llama-2-7B(多言語モデル)
公平な比較のため、基本的に1024トークン長で統一
(japanese-gpt-4B-8kは例外で、2048/4096/8192トークンでも実験)
マルチモーダル入力モデル
Japanese-StableLM-Instruct-Alpha-7B(InstructBLIPの日本語版)を使用
512トークン長で実験
3種類の視覚入力パターン:
白紙画像(アブレーション用)
文書全体のページ画像
アノテーションされた該当部分の切り取り画像
OpenAI GPTベースライン
gpt-3.5-turbo-16kとgpt-4を使用
ゼロショット学習として実験
プロンプトを手動調整
ファインチューニングは以下の理由で実施せず:
ローカルでの限られたリソースでの動作が目的
ファインチューニングの詳細が不明
APIコストの問題
Evaluation Methods
評価手法に関する説明です。
質問タイプに応じた適切な評価を実施しています。
Yes/No、事実関連、数値関連の質問の評価
完全一致(Exact Match)メトリックを使用
以下の微細な違いは無視:
句読点の有無
「です」などの日本語の語尾
完全一致の変形版も検討:
モデルの予測フレーズが正解フレーズに含まれているかの比率
ただし、通常の完全一致との差は検証セットで10ペア未満と僅少
自由回答式質問の評価
完全一致は不適切
回答が長い(平均65.97文字)ため
BLEUスコアを採用
MeCabで形態素解析して評価
自動評価の手法として使用
Experimental Settings
実験の設定に関する説明。
回答不能な質問の影響を詳細に分析できる実験構成。
データセットの特徴
すべての質問カテゴリーに回答不能な質問(unanswerable questions)を含む
モデルの2つのバージョン
全質問回答ペアでファインチューニングしたモデル
(回答不能な質問を含む)回答可能な質問のみでファインチューニングしたモデル
(回答不能な質問を除外)
評価用データセットも2種類を用意
標準の検証・テストセット
(すべての質問回答ペアを含む)縮小版の検証・テストセット
(回答不能な質問を除外)
この設定の理由
回答不能な質問でのファインチューニングは、モデルの幻覚(hallucination)を抑制する可能性
ただし、回答不能な質問の検出は本質的に困難な課題という指摘がある。(Rajpurkar et al., 2018)
結果
Models trained with all instances
以下の結果は、モデルのパラメータ数だけでなく、文脈長などの要因も性能に重要な影響を与えることを示唆している。
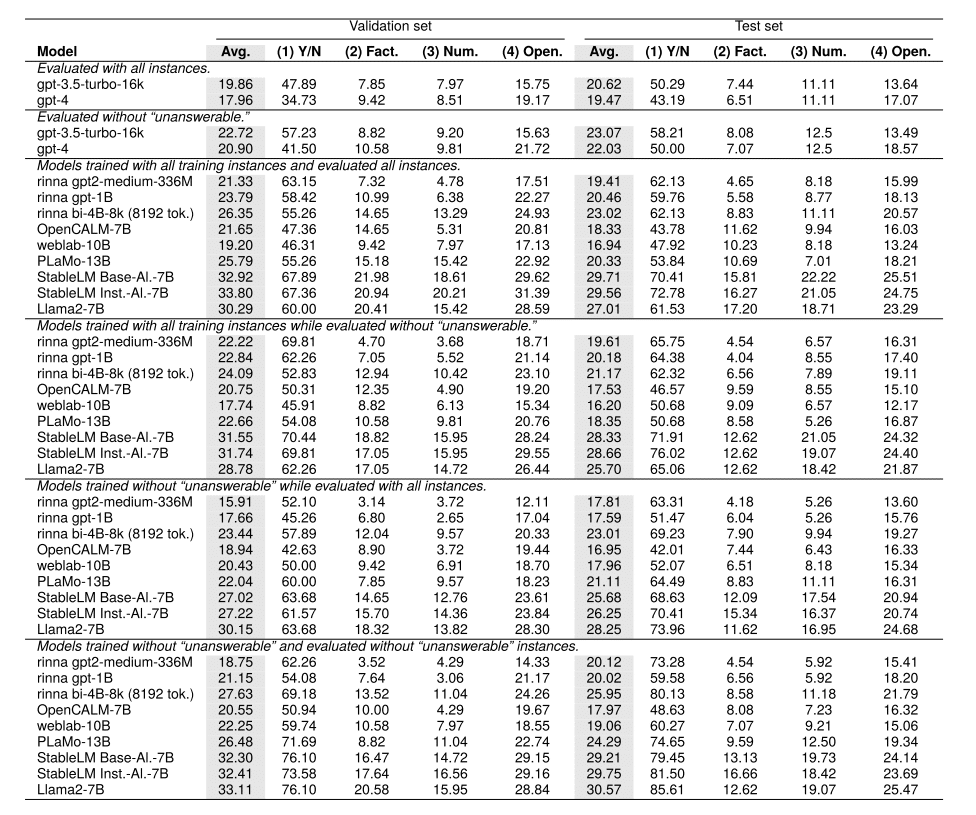
すべての質問タイプに対する検証・テストセットでの性能を評価(表4)。
全インスタンスで学習したモデルの分析:
ゼロショットとファインチューニングモデルの比較(表4の第1ブロックと第3ブロック)
大規模なモデルほど、ファインチューニング済みモデルがGPT-3.5/4を上回る
回答不能質問除外ケースの比較(表4の第2ブロックと第4ブロック)
全インスタンス評価と同様の傾向
回答可能/不能な質問で同程度の性能を示す
モデル別の性能:
StableLMモデル
パラメータ数が7Bと少ないにも関わらず最高性能
rinna bi-4B-8kモデル
パラメータ数の割に高性能
8192トークンという長い文脈長が要因と推測
質問タイプ別の特徴
Yes/No質問は比較的容易
平均スコア(Avg.)は主に自由回答式質問の結果を反映
Models trained without unanswerable
回答不能質問を除外して学習したモデルの分析:
この結果は、回答不能質問を学習に含めることが、モデルの質を向上させる可能性を示唆しています。
評価結果の比較(表4)
第5・第6ブロック:回答不能質問を除外して学習したモデルの結果
回答不能質問を含む評価と除外した評価の両方を実施
重要な発見
第3ブロックと第5ブロックの比較
同じ評価セット(回答不能質問を含む)での比較
回答不能質問を含めて学習したモデルの方が、平均スコアで優れた性能
例外的なモデル
OpenCALM-7B
weblab-10B
Llama2-7B
(これらは異なる傾向を示し、別途議論)
結果の解釈
幻覚(hallucination)の抑制効果
文脈に存在しない回答を生成する問題への対処
回答不能質問を学習データに含めることで:
幻覚を抑制する効果がある可能性
定性的分析で具体例を提示予定
OpenCALM-7BとWeblab-10Bの特異な挙動
この結果は、事前学習の重要性と、回答不能質問の判断がモデルの性能評価において重要な要素であることを示唆しています。
観察された現象
パラメータ数の割に性能が低い
「本文中に記載がありません」という予測が少ない
OpenCALM-7B:11.9%
weblab-10B:13.7%
他のモデル:20%以上
問題の特徴
同じデータセットで学習しているにもかかわらず、異なる結果
原因は事前学習(pretraining)の違いによる可能性
重要な知見
質問が回答不能かどうかの判断は、モデルにとって困難なタスク
この判断能力は全体的な性能に大きく影響する
Multimodal model results
結果は、マルチモーダル入力の有効性を示すと同時に、現在のモデルの制限も明らかにしています。
実験結果(表5より)
StableLM-InstructBLIP-Alphaの性能を評価
特に参照された表や図の切り取り画像(bbox)使用時に性能が向上
興味深い発見
白紙画像入力モデルも、視覚モデルに近い性能を示す
これは本タスクにおけるテキスト入力の有効性を示唆
制限事項
StableLM-InstructBLIP-Alphaの最大トークン長は512
この制限が現行のマルチモーダルモデルのテキスト理解能力を制限している可能性

Token length dependency
トークン長の依存性に関する説明。
モデルの性能向上にトークン長が重要な要因であることを示しているが、同時に計算コストとのトレードオフも存在することを示唆している。
調査内容
トークン長が性能に与える影響を分析
rinna bi-4B-8kモデルで3種類のトークン長を検証
2048トークン
4096トークン
8192トークン
全訓練インスタンスと回答不能質問除外の両条件で実験
主な発見(表6より)
ファインチューニング時のトークン長が最終結果に明確な影響
長いトークン長でのファインチューニングは計算コストが高い
表4でrinna bi-4B-8k(8192トークン)モデルが良好な性能を示した理由はトークン長の長さによる可能性

Qualitative Analysis
定性的分析の結果
この分析は、回答不能質問を学習に含めることの重要性と、マルチモーダル入力の利点を具体的に示しています。

以下は図4の分析結果を示す。
上部の例:
3つのモデルの生成結果を比較(回答不能質問を含む学習)
StableLM InstructBLIP-Alpha(画像入力)
StableLM Instruct-Alpha-7B
StableLM Base-Alpha-7B
結果:
画像入力モデルは表の配置を理解し、適切な車の説明を生成
Base-Alphaも類似の回答を生成したが、表にある走行距離123,334の情報を正確に扱えず
下部の例:
同じ事前学習モデルから派生した2つのモデルを比較
回答不能質問を含めて学習したモデル
回答不能質問を除外して学習したモデル
結果:
全インスタンスモデル:本文に回答がないことを正確に予測
回答不能質問除外モデル:誤って回答を生成(幻覚現象)
Human evaluation
この人的評価により、モデル間の性能差が定量的に示されました。
評価方法
テストセットから100の自由回答型質問をサンプリング
評価対象モデル:
テキスト入力モデル:
PLaMo-13B
StableLM Instruct-Alpha-7B
マルチモーダル入力モデル:
StableLM InstructBLIP-Alpha(黒画像入力)
StableLM InstructBLIP-Alpha(通常画像入力)
評価基準(0-2点)
生成された回答が正解を含んでいるか
誤った記述が含まれていないか
結果(表8)
StableLM Instruct-Alpha-7BがPLaMo-13Bを上回る性能
画像入力モデルが黒画像入力モデルより良好な結果

100の質問サンプルに対する各モデルの回答を、人間が定められた基準に従って採点
まとめ
このデータセットは、実際のアプリケーションで直面する様々な課題に対応できる実用的なツールとしての可能性を示しています。すなわち、
データセットの特徴
JDocQAデータセットを導入
視覚的・言語的手がかりの統合に焦点
日本語での質問応答タスク向け
文書から回答不能な質問を含む
主な発見
回答不能質問の導入が幻覚生成の抑制に効果的
多様な質問カテゴリーで有効性を確認
Yes/No質問から自由回答型まで
回答不能質問の予測が性能向上の鍵
実用的価値
現実的なアプリケーションに有効
複数カテゴリーの質問に対応可能
文書に明示的な回答がない質問への対応が可能
英語ハッシュタグ:
#JDocQA
#QuestionAnswering
#AI
#MachineLearning
#NLP
#DataScience
#DocumentQA
#JapaneseNLP
#DeepLearning
#AIResearch
日本語ハッシュタグ:
#質問応答
#人工知能
#機械学習
#自然言語処理
#データセット
#文書理解
#日本語AI
#デジタルトランスフォーメーション
#画像認識
#AIリサーチ
この記事が気に入ったらサポートをしてみませんか?