
AWSがRAGシステムの評価をいい感じにまとめていた

こんにちはmakokonです。
RAGを使っていますか?
ちょっと自分用のRAGシステムを使って便利に会話するのはいいのですが、不特定多数の人に使ってもらうシステムを公開しようとすると、それなりの責任があるし、裏付けとなる評価が必要なのですが、なかなか一般的な評価フレームワークを構成するのは大変です。
このあたりを、AWSがうまいことまとめてくれたので簡単に紹介しようと思います。この仕組みは、RAGの重要で基本的な本質を適切に評価できるように思います。記事の中では、これを具体的なプロンプトにも構成してみました。
この評価の仕組みを上手く利用して、より良いRAGを構成できるようになればいいですね。
この論文はなに? 評価フレームワークRAGCHECKERを紹介するよ
この論文は、Retrieval-Augmented Generation (RAG) システムの評価フレームワークであるRAGCHECKERを提案し、その有効性を検証するものです。
以下のような内容が含まれています。
RAGシステムの評価における課題とRAGCHECKERの必要性
RAGCHECKERの詳細
設計原則
入力
評価手法
指標群
RAGCHECKERを用いた実験と結果
結論 RAGCHECKERの有効性
どうして、RAGCHECKERが必要なのか?今の評価の何が問題なのか
RAGシステム(検索拡張生成)の評価は、システムが複雑で、既存の評価方法では正確に測れない、そして評価自体の信頼性が低いという問題があります 。既存の研究では、生成部分だけを評価したり、システム全体の評価が単純すぎたりする限界がありました 。RAGCHECKERは、これらの問題を解決するために、システム全体、検索、生成の各部分を細かく評価し、エラーの原因を特定できるように設計された評価フレームワークです 。つまり、RAGシステムの性能をより正確に把握し、改善点を見つけやすくするためのツールです 。
つまり、RAGシステムの評価における以下の課題に対応する必要があります。
(1)モジュール構造の複雑さ、
(2)既存の評価指標の限界、
(3)評価指標の信頼性の問題です 。
RAGCHECKERの評価手法の概念を図1を参照しながら、定性的に説明
RAGCHECKERの評価手法は、RAGシステムの検索と生成の両方のプロセスを詳細に分析するために設計された革新的なフレームワークです 。図1は、RAGCHECKERで提案されている指標の概念を示しており、モデルの応答と正解(ground truth)を比較し、正しい主張、誤った主張、欠落した主張を識別します 。
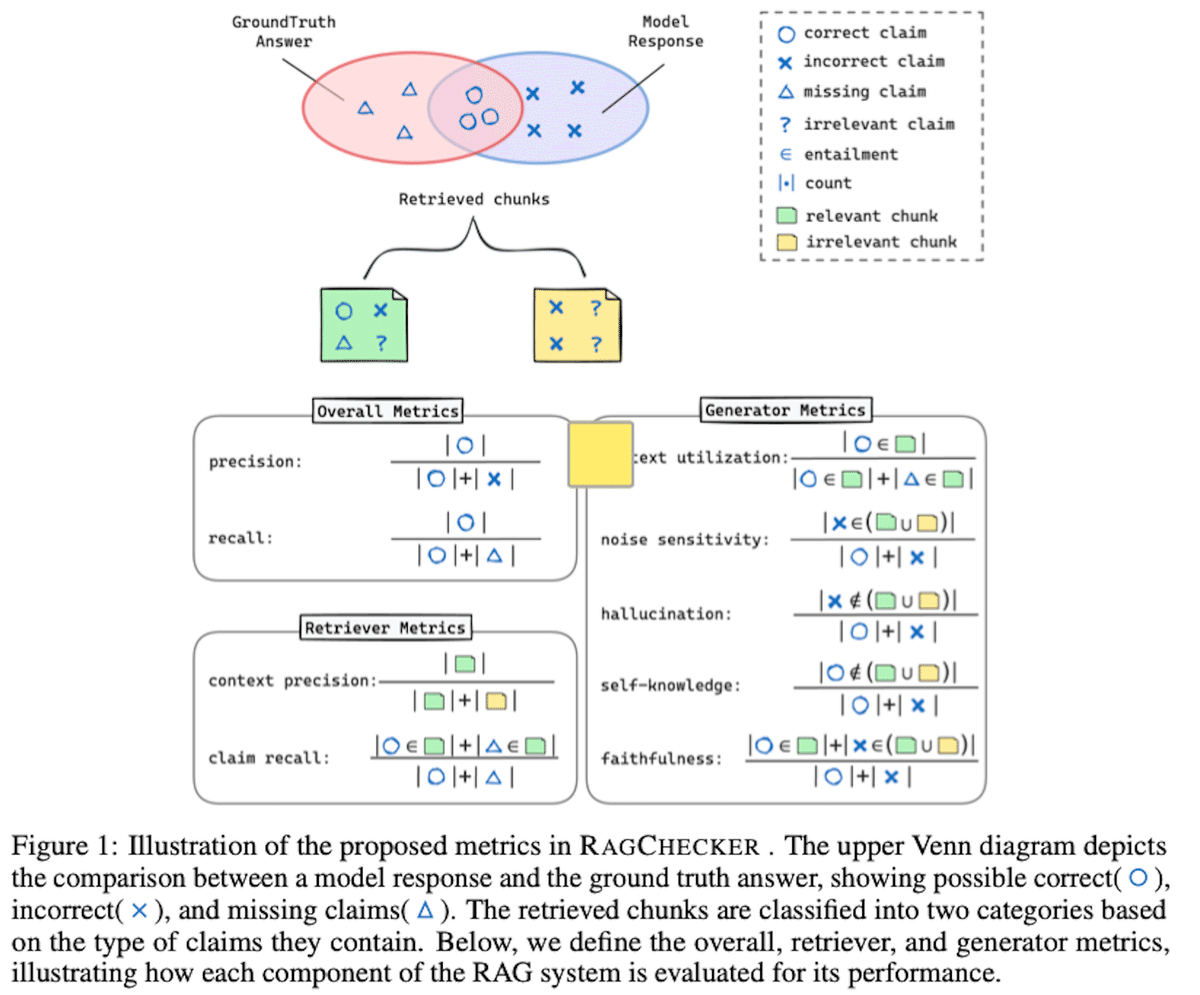
具体的には、RAGCHECKERはクレームレベルのentailment checkingに基づいており、応答と正解からクレームを抽出し、それらを他のテキストと照合します 。これにより、応答全体を評価するのではなく、より細かく評価できます 。RAGCHECKERは、ユーザーのクエリ、検索されたコンテキスト、応答、および正解を処理し、一連の指標を生成します 。
これらの指標は、全体指標、診断的検索器指標、診断的生成器指標の3つのカテゴリに分類されます 。全体指標は、生成された応答の全体的な品質を評価し、システム全体のパフォーマンスを把握するためのものです 。診断的検索器指標は、検索器の有効性を評価し、知識ベースから関連情報を検索する際の長所と短所を特定します 。診断的生成器指標は、生成器のパフォーマンスを評価し、検索されたコンテキストをどれだけうまく利用し、ノイズの多い情報を処理し、正確で信頼性の高い応答を生成するかを診断します 。
図1では、検索されたチャンクが、それらが含むクレームのタイプに基づいて2つのカテゴリに分類されている様子も示されています。関連するチャンク(r-chunk)は、正解に必要なクレームを含み、無関係なチャンク(irr-chunk)は、そうでないものです 。これらの指標を使用することで、RAGシステムのエラーの原因を特定し、改善するための実用的な洞察を得ることができます 。
もっと端的にわかりやすく、評価方法を説明する。
RAGCHECKERの評価は、要するに、生成AIに「自己評価」させ、その結果を基にRAGシステムの性能を多角的に分析するということです 。これは、以下の手順で行われます :
クレーム抽出: 生成AIの回答と模範解答から、それぞれ主張(クレーム)を抽出します 。
クレームの照合: 生成AIに、生成AIの回答に含まれるクレームが模範解答に含まれているか、また、検索された文書(Retrieved Chunks)に根拠があるかを判定させます 。
チャンクの分類: 検索された各チャンクを、模範解答に必要なクレームを含む「関連チャンク (relevant chunk)」と、そうでない「無関係なチャンク (irrelevant chunk)」に分類します 。
指標の算出: 抽出されたクレーム、照合結果、チャンクの分類に基づき、全体指標、検索器指標、生成器指標を計算します 。これらの指標は、RAGシステムの全体的な品質、検索の有効性、生成の正確さを評価するために使用されます 。

試しにプロンプト化してみる。
RAGCHECKERの評価フローを試しにプロンプト化してみます。
この手法の便利さと難しさが見えてくるかもしれません。
以下は、RAGCHECKERの評価フローに沿った日本語の評価プロンプトのサンプルです。このプロンプトは、生成AIに対して、回答の品質や根拠の有無などを評価させるためのものです。
プロンプトの構成:
役割定義: あなたは優秀な研究者であり、高度な読解力と文章作成能力を持っています。与えられた情報とあなたのAI知識に基づいて、ユーザーの質問に答えてください。
タスク: ユーザーの質問に対する回答と、その根拠となる検索結果が与えられます。模範解答と比較して、回答の正確性、完全性、関連性を評価してください。
評価項目:
正確性: 回答は模範解答と一致していますか?誤った情報や不正確な情報が含まれていませんか?
完全性: 回答は質問に対して十分な情報を提供していますか?必要な情報が欠落していませんか?
関連性: 回答は質問に直接関係していますか?無関係な情報や冗長な情報が含まれていませんか?
根拠: 回答の根拠は、検索結果から明確に示されていますか?検索結果にない情報が含まれていませんか?
指示: 以下の質問と回答、検索結果、模範解答を注意深く分析し、上記の評価項目に基づいて評価結果を述べてください。各評価項目について、具体的な根拠とともに説明してください。
入力データ:
質問: (ユーザーの質問)
生成AIの回答: (生成AIによって生成された回答)
検索結果 (Retrieved Chunks): (RAGシステムによって検索された文書のリスト)
模範解答 (Ground Truth Answer): (正解とされる回答)
出力形式:
評価結果:
* 正確性: (評価) - (根拠)
* 完全性: (評価) - (根拠)
* 関連性: (評価) - (根拠)
* 根拠: (評価) - (根拠)プロンプトの例:
あなたは優秀な研究者であり、高度な読解力と文章作成能力を持っています。与えられた情報とあなたのAI知識に基づいて、ユーザーの質問に答えてください。
タスク: ユーザーの質問に対する回答と、その根拠となる検索結果が与えられます。模範解答と比較して、回答の正確性、完全性、関連性を評価してください。
評価項目:
* 正確性: 回答は模範解答と一致していますか?誤った情報や不正確な情報が含まれていませんか?
* 完全性: 回答は質問に対して十分な情報を提供していますか?必要な情報が欠落していませんか?
* 関連性: 回答は質問に直接関係していますか?無関係な情報や冗長な情報が含まれていませんか?
* 根拠: 回答の根拠は、検索結果から明確に示されていますか?検索結果にない情報が含まれていませんか?
指示: 以下の質問と回答、検索結果、模範解答を注意深く分析し、上記の評価項目に基づいて評価結果を述べてください。各評価項目について、具体的な根拠とともに説明してください。
入力データ:
* 質問: RAGシステムとは何ですか?
* 生成AIの回答: RAGシステムとは、検索によって情報を取得し、その情報を基に文章を生成するシステムです。
* 検索結果 (Retrieved Chunks):
* チャンク1: RAGシステムは、外部の知識ソースから情報を検索し、その情報を利用してテキストを生成する技術です。
* チャンク2: RAGシステムは、質問応答、文章要約、テキスト生成などの様々なタスクに適用できます。
* 模範解答 (Ground Truth Answer): RAGシステム(Retrieval-Augmented Generation)とは、検索によって取得した情報を基に、テキストを生成する手法です。外部知識を利用することで、より正確で詳細な回答を生成することができます。
出力形式:
評価結果:
正確性: (評価) - (根拠)
完全性: (評価) - (根拠)
関連性: (評価) - (根拠)
根拠: (評価) - (根拠)こんな感じですかね。geminiを利用して何回かやり取りして整形しました。
RAGシステムの基本的な評価内容は網羅できていると思います。
ただ、実際には、データセットや設問の構成によって、工夫しないとだめかも知れないですね。多分、評価基準(正確性、完全性、関連性、根拠)は、もっと具体化するか、評価に合わせて修正する必要があるかもしれません。
また、RAGの構成によっては、もっと複雑な入力になるかもしれません。
また、自動化や、フィードバックなどの利用システムを考えないと上手く機能しないかもしれません。
今回の論文における知見のまとめ
一応、この論文で得られたRAGに関する知見を記載しておきましょう。
定性的な言葉にすると、普段の実感にかなりあっていますね。この評価システムが、順当な結果になっているのではないでしょうか?
今回のRAGシステムに関する実験結果の主な知見は以下の通りです。
検索器の質: 高性能な検索器(例: E5-Mistral)を使用すると、RAGシステム全体の精度、再現率、F1スコアが向上します 。
生成器のモデルサイズ: より大規模な生成器モデル(例: Llama3-70B)は、コンテキストの活用度を高め、ノイズへの感度を下げ、幻覚を減少させることで、RAGシステムの性能を向上させます 。
コンテキストの活用度: コンテキストの活用度はRAGシステムの全体的な性能と強く相関しており、特にF1スコアとの相関が強いです 。
情報量の多いコンテキスト: 情報量の多いコンテキストは、生成器の忠実度を向上させ、幻覚を減少させる傾向があります 。
検索器のクレーム再現率と生成器のノイズ感度: 検索器のクレーム再現率が高くなると、生成器がノイズに対してより敏感になるというトレードオフが存在します 。
オープンソースモデルの課題: オープンソースモデルは、正確な情報とノイズを区別することが苦手であり、コンテキストを盲信する傾向があります。推論能力の向上が必要です 。
RAGシステム最適化の可能性: チャンク数、チャンクサイズ、チャンクの重複率、生成プロンプトを変更することで、RAGシステムの性能を改善できる可能性があります。ただし、コンテキスト量とノイズ感度、忠実度とコンテキスト活用度・ノイズ感度の間でトレードオフが生じる可能性があります 。
これらの主な数値結果は表3他にまとめられています。

まとめ
この記事では、RAGシステムの評価フレームワーク「RAGCHECKER」を紹介しました。このフレームワークは、RAGシステムの複雑な評価を、クレームベースの分析により実現。システム全体、検索部分、生成部分それぞれを細かく評価できる特徴を持ちます。
実験結果から、高性能な検索器の重要性や、大規模モデルの利点、コンテキスト活用度の重要性などが明らかになりましたが、これは定性的に経験にあった結果であり、今回の評価方法が妥当なものと感じました。
また、評価手法を具体的なプロンプト例として構成することによって、、実践的な活用方法と、この手法をより性格にするための考察ができました。
ハッシュタグ
#RAG
#RAGCHECKER
#生成AI
#評価フレームワーク
#検索拡張生成
#LLM
#AIエンジニアリング
#AWS
#プロンプトエンジニアリング
#AI評価手法