
どんな営業データならAI活用ができるか ChatGPT で試してみた

AI による営業の自動化が当たり前になる時代において、AIを正しく稼働させるにはデータが必要です。今回は、実際にChatGPTに「良いデータ」「ダメなデータ」を入力した結果を例に、AI活用ができる「意味のあるデータ」の要件について解説します。
ChatGPT でも営業データから十分に示唆を得られる
まずは皆さんがおそらく一度は触ったことがある ChatGPT で、AI が読み込めるデータを検証します。データ品質による出力結果の違いを検証するために、試しに弊社で営業活動のメタデータを2パターン作成し、Chat GPT に案件の受注確率と判断理由を聞いてみました。

2つのメタデータの違いですが、左図は情報が定義・整理され、整合的に取り扱える状態の「構造化データ(良いデータ)」、右図は定義や分類がされていない「非構造化データ(ダメなデータ)」です。構造化データは会社名、分類、受注理由といった情報が漏れや重複なく整理されている一方で、非構造化データは案件ごとに情報のばらつきがあります。

「構造化データ(左)」「非構造化データ(右)」
Chat GPT4.0 にそれぞれのメタデータを入力し、同じ質問をします。「株式会社東京ソリューション(エンプラ)と商談中。製品Aを使っている。過去データから受注の確率、その時の理由はわかる?」という質問をし、左側は構造化データ、右は非構造化データを入力した場合の出力結果です。

「構造化データ」に紐づく回答(左)、「非構造化データ」に紐づく回答(右)
また、構造化データを用いた回答には「株式会社東京ソリューションは社員教育目的で弊社製品を導入しようとしているようです。どうアプローチするのがいいでしょうか?」と追加質問をし、得られた回答は以下です。

両者の違い
構造化データと非構造化データの出力結果において異なる点は、前者からは「個別の案件に関する事実に基づいた洞察が得られる」ことです。構造化されたメタデータからは以下のような示唆を得ることができました。
・定量的な要素が提示される:受注確率 25%
・受注要因に関する具体的な要因が分かる:価格
・追加質問により推奨アクションが示唆として得られる:製品の価格競争力を強調し、他社製品との比較や長期的なコスト削減効果をアピールする
営業におけるこれらの情報は、これまでは「人の勘と経験」に委ねられ、暗黙知のまま明らかにされていなかった領域でしたが、きちんと構造化されたデータを社内で組織的に蓄積することができれば、集合知から定量的に案件ごとの将来を予測し、リスクがある場合は必要な対策や改善点がわかります。
上記で活用した営業活動のメタデータ、および ChatGPT を活用したプロンプトは、下記のリンクより自由に閲覧いただけます。出力結果に続いて追加質問も可能ですので、お試しください。
正規化データの場合:https://chat.openai.com/share/23fe8e03-cfd1-4f51-820f-63df542a836b
非正規化データの場合:https://chat.openai.com/share/859e7dda-7717-4ff2-9969-6ca4638895ca
正規化されたデータを貯めるための、4 つの要件
ChatGPTで実証したとおり、AIが正しく示唆を導くためには「良いデータ」が必須になります。そして組織的にデータを蓄積するためには、全体で一貫したデータ戦略を練り、統一された認識のもとオペレーションが設計・運用されていることが重要です。
当社では、独自のデータ戦略(「TRUE INDEX」)を掲げています。代表の村尾が Google や freee に在籍していた際に学んできたデータ基盤の要件をベースとします。ここからは「AIが活用できるデータ」を貯めるための大事な4つの要素を紹介します。

リアルタイム記録
リアルタイム記録とは、事象が発生したと同時にデータが作成及び取得され、遅延なくデータが利用できることです。データの発生源となった業務と同時に、記録されるデータを指します。
例:
✖︎ 商談中にとったメモを商談が終了してからシステムに入力する
◎商談内容を商談中にシステムに記録する

データをリアルタイムで蓄積する理由は、常に変化し続ける顧客の状況を捉えるためです。
これまではデータを作るために営業担当が手動で対応する必要があり、入力にラグが発生すればその分数字の集計に時間がかかり、時間の経過により顧客の実際の状況と異なる情報の入力・蓄積につながる恐れがありました。昨今は文字起こしや音声解析といった自動記録の技術進化が進んだことでデータ記録の省力化が可能になり、活用シーンが増えています。今後さらに記録の精度・速度の品質が上がれば、自動記録がデフォルトになっていくのではないかと思います。
シングルインプット
シングルインプットとは、一度の記録作業で、漏れや重複なく、データが記録されるべき必要な場所に蓄積されることです。二度打ち・転記を一切行わない入力です。
例:
✖︎ 商談内容を一覧化するためのエクセルがあり、一度入力済みの商談内容を手で転記している
◎商談内容の確認は、営業が入力した元データが連携させたシステム上に自動記録している

何度もデータの打ち込みや転記が行われることで、ヒューマンエラーによる誤入力や記入漏れが発生しやすくなるだけでなく、本来一度で済むはずの業務に時間が奪われ活動時間が圧迫されます。人の介在を極力減らし、一度の入力で一気にデータが連携されるオペレーションが組まれていることがポイントです。
トレーサビリティ
トレーサビリティとは、データ基盤全体において透明性があり、かつ追跡可能である状態を指します。課題が発生している原因を特定し解決するためには、いつ何が行われているかを追跡できることが重要です。元データやログを参照することができる状態を指します。
例:
✖︎ 大幅な割引率で販売してしまったが、誰が承認したか不明である
◎大幅な割引率で販売されているが、記録されている全ての商談や承認プロセスログを参照し、承認者を特定、解決策を検討できる
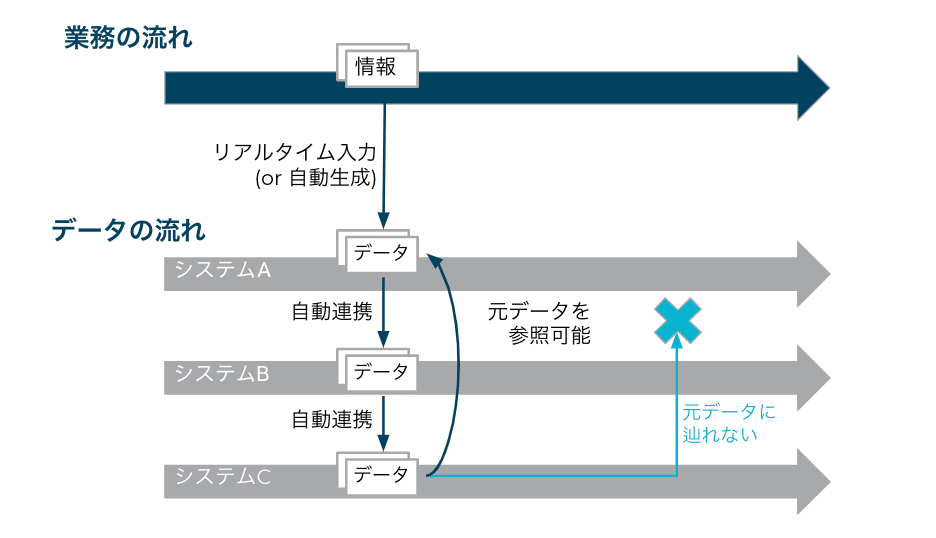
トレーサビリティがない場合、例えば元データを参照できず確認に時間がかかったり、変更などが反映されずに誤った情報で意思決定を進めてしまうといったリスクがあります。誰がいつ何をやったか、という情報が参照できなければ、イレギュラー時の原因究明も困難になります。
データの構造化
データの構造化とは、階層的に定義・構成されているデータです。誰が、いつ、何を、どうする といった情報の保存場所や形式、時系列が明確に定義され、測定可能・検証可能なデータ構造である状態を指します。
例:
✖︎ 商談時に取得する情報が構造化されておらず、各担当者が主観的に重要だと思った点を営業メモとして残している
◎商談時に取得する情報が決められており、測定可能・検証可能な項目が記録されている

データの構造化が出来ていない場合、営業担当がどのような情報を記録すれば良いのか分からず、バラバラな情報を記録してしまう可能性があります。そもそもデータの質が低いため、AIがそこから業務の自動化やネクストアクションの示唆出しができないのはもちろん、人がデータを見ながら比較・分析することもままならないでしょう。
AI活用による経済価値は70億円以上に
営業活動にAIが導入され、これまで人力で行っていた記録や報告、判断の負担がなくなった場合、どれだけの経済的価値が生まれるのでしょうか。営業担当が1,000人いる営業組織のケースシナリオを考えてみます。1日の労働時間は10時間(調査から平均残業時間を2時間)と設定しています。

まずはコスト削減効果ですが、データの記録や定型的なタスクに営業が使っている2時間が削減され、残業の必要がなくなれば、1日に2000時間の業務効率化となり、営業担当の時給(5000円とする)をかけると 1000万円、年間(250日とする)では 25億円のコスト削減効果が出ると推定されます。
同時に、売り上げ向上効果(※)も見込めます。これまで1日当たり6時間しか担保できなかった活動時間を 1時間増やせたら、6→7時間への活動量増加によって売り上げの15%向上も期待できるでしょう。
(※)営業組織における1年間の売り上げ向上効果:営業担当一人当たりの年間の売上高(1億円)× 営業人数(1000人)×活動量の伸び率(15%)=150億円。売り上げ向上に対する粗利益の伸び:売り上げ成長(150億円)×粗利(30%)=45億円
つまり、現実的なインパクトはコスト削減効果、売り上げ増収効果が同時に見込まれるため、最終的に生み出される経済的効果は総額で年間約70億円にも達します。

AI活用の未来と人の役割
ケースシナリオでは、AI活用による業務自動化で生み出すことができる経済効果の可能性を試算しました。現場浸透にはまだ時間がかかることが想定される一方で、日本は既に労働供給が減り手立てを打つ必要がある状況のため、AI活用は生命線にもなると思います。
次の投稿では、営業におけるAI導入が確実性の高い未来となり、活用領域も広がっていくことが予想されるなかで、組織と個人にどのような変化が求められるようになるか考察します。
来週10/30(月)の公開をお楽しみにお待ちいただけますと幸いです。
また、本投稿の内容を ITmediaビジネスオンラインにて、当社代表村尾の連載企画としてご掲載いただいております。
【プロンプト公開】ChatGPTが受注率も算出できる「良いデータ」とは?AI時代のデータの作り方(2023年10月13日掲載)