
AI 実装検定への道(9)

AI 実装検定 A級合格へ向けて学習を進めています。
前回投稿が8回目で、引き続きGoogle Colaboratoryを利用してプログラミングの章を進めて書いています。
第8回では、前々回から引き続き「NumPy」のような拡張ライブラリのひとつである「pandas」を使って表形式に並べていくことを勉強しました。「Series」を使って各格納データを整理し、「score」を使って「Series」を定義づけるのだが、同時に「midscore」「endscore」なるものを生成しておいて「DataFrame」でExcelのような表形式に表現できました。「Google Colaboratory」の機能において、DataFrameについては表形式にまとめて見易いようにしてくれるそうです。
今回は、234ページから進めていきます。
直接DataFrameを作成
公式テキストに倣って、2×5の下記のような直接DataFrameを作成します。
1.2, 1.5, 2.4, 2.7, 2.9
2.3, 2.6, 3.1, 3.5, 3.8
(コード記述)
data=pd.DataFrame([[1.2, 1.5, 2.4, 2.7, 2.9],[2.3, 2.6, 3.1, 3.5, 3.8],])
data
(結果)
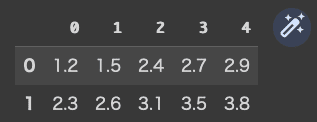
pandasのDataFrameと、NumPyの配列(行列)は Indexでデータを取得する際に違いがあるので比較するということですが・・・
(コード記述)
data[0]
(結果)
0 1.2
1 2.3
Name: 0, dtype: float64
(コード記述)
data[3][1]
(結果)
3.5
data[3][1] とすると、3列目の1行目 3.5が抽出されました。
ここでは、indexには指定された数値を入力していますので、初め(0)から何個目と数えなくて良いみたい。公式テキストにある、NumPyとpandasの違い・・・というあたりのことは良く分かりませんが先に進むとします。
csvファイルの読み込み
次に、DataFrameを作る別の手段として「csvファイル」を読み込むのだそうです。先日、道草的に『アイティメディア株式会社が運営する「ITmedia」サイトのうち『@IT』サイトに掲載された情報』で勉強したあたりとよく似ています。公式テキストに紹介されているのは、Google Colaboratoryに用意されたサンプルデータ「mnist_test.csv」を読み込むようです。
(コード記述)
pd.read_csv("sample_data/mnist_test.csv").head()
(結果)

公式テキストは優しいですね。
.head()と追記することで、先頭5行を抽出するということのようです。
.head(8)として試してみましょう。
(コード記述)
pd.read_csv("sample_data/mnist_test.csv").head(8)
(結果)

このように、実際のデータ処理でもcsvファイルを読み込んでpandasで分析をすることがよくあるようです。次に、Seriesのデータを作成してDataFrameに変換し、辞書の配列に渡すことでDataFrameを作成するというのをやってみます。
(コード記述)
pd.DataFrame([{"a":2,"b":5},{"a":6,"b":7},{"a":8,"b":9},])
(結果)

ここで注意をしなければならないのは、( )、[ ]、{ }の使い方。
下記のようにするとエラーになります。
(コード記述)
pd.DataFrame([["a":2,"b":5],["a":6,"b":7],["a":8,"b":9],])
(結果)
File "<ipython-input-10-957a3dd4e55a>", line 1
pd.DataFrame([["a":2,"b":5],["a":6,"b":7],["a":8,"b":9],])
^
SyntaxError: invalid syntax
次は、c列を作ってちょっと紛らわしいですが、下記のようにやってみます。(一部、数値を指定しないままにしておくってことかな?)
(コード記述)
pd.DataFrame([{"a":2,"b":5},{"b":6,"c":9},])
(結果)
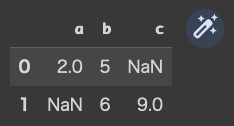
数値をあらかじめ指定しなかった、2行目のa列と、1行目のc列には「NaN」と表示されました。「数値がない」ことを「NaN」(非数)として表示するのだそうです。これを欠損値というそうですが、これまでにも出てきたような・・・気のせいかな??
次に、np.random.rand 関数を使って4×3の配列(行列)を準備します。
(コード記述)
data=np.random.rand(4,3)
data
(結果)
array([[0.77313055, 0.01798844, 0.36828405],
[0.04833785, 0.75269491, 0.23758432],
[0.75781515, 0.67130274, 0.60468659],
[0.85451604, 0.44753611, 0.75834494]])
(コード記述)
data2=pd.DataFrame(data,)
data2
(結果)
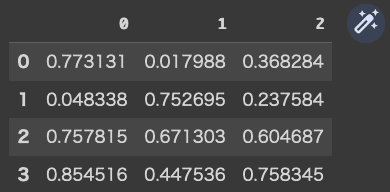
これは分かりやすいですね。
NumPyで配列(行列)を生成し、その後 pandasでDataFrameに格納するというやり方でした。最初の「data」の方に対してdata[0]と照会すると、0行目の1行の数値が3つ呼び出されますが、「data2」に対して「data2[0]」と照会すると0行目が下記のように呼び出されました。
(コード記述)
data[0]
(結果)
array([0.77313055, 0.01798844, 0.36828405])
(コード記述)
data2[0]
(結果)
0 0.773131
1 0.048338
2 0.757815
3 0.854516
Name: 0, dtype: float64
私なら、間違っても確認すればいいや!って感じにあまり気にしないんですが、NumPyの場合と、pandasでは異なるということはインプットしておきましょう。
次は、NumPyの配列(行列)から、Indexをa,b,c,d,として、columnsをfoo, bar, bazとしてDataFrameに格納することをやってみます。
(コード記述)
pd.DataFrame(data, columns=["foo", "bar", "baz"],index=["a", "b", "c", "d",])
(結果)
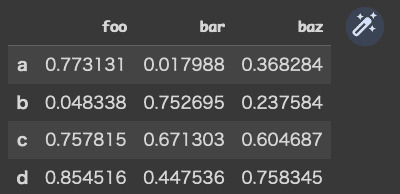
pandasで欠損値の処理
(コード記述)
df1=pd.DataFrame({
"0番目":[30, 50, None, np.nan],
"1列目":[40, 70, None, np.nan],
"文字列":["X", "Y", None, np.nan],})
df1
(結果)

公式テキストでは、240ページに進んでいます。
何気に上記DataFrameを眺めていても気付きませんが、よくよく見ると3行目の3列目には「None」と表示されています。
コードには、どの列に対しても「None, np.nan」と記述したので、3、4行目に対する処理は同じのはずですが、1列目(0番目列)と2列目(1列目列)は最初の行に数値を示したので、3、4行目も数値として処理され「NaN」(非数)として表されましたが、3列目(文字列)においては先に文字列が入っているので、3行目には「None」とそのまま表示されたようです。
そこで、isna( )を使って、pandasで欠損値を探してみます。
(コード記述)
df1.isna()
(結果)

下記のようにしても、同じ結果が得られました。
(コード記述)
pd.isna(df1)
(結果)

notna( )は、isna( )の逆だそうです。
やってみましょう!
(コード記述)
df1.notna()
(コード記述)
pd.notna(df1)
(結果)

欠損値の処理
欠損値の処理には大きく2つあり、欠損値を削除してしまう方法と、他の値を入れる方法があるそうです。
もとのDataFrameはこれでした。

ここで、欠損値を削除する「dropna」を使うと・・・
(コード記述)
df1.dropna()
(結果)

これをpandasからも実行してみます・・・pd.dropna(df1)っとは、使えないようだ・・・dropnaでは、データを上書きしたのではなく、新たなDataFrameを生成したと解説されています。念の為、df1を再度呼び出してみます。
(コード記述)
df1
(結果)

df2として、別に欠損のあるDataFrameを作成します。
(コード記述)
df2=pd.DataFrame([
[5, np.nan, 3],
[2, 6, 8],
[np.nan, 7, 9],
])
df2
(結果)
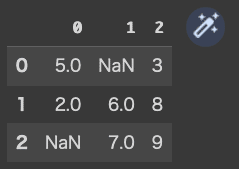
df2に、欠損値を削除する dropnaを利用すると・・・
(コード記述)
df2.dropna()
(結果)

ということで、欠損値を含む行が削除されてしまいました。
これを列方向に削除する記述を加えます。
(コード記述)
df2.dropna(axis="columns")
(結果)

(コード記述)
df2.dropna(axis=1)
(結果)

(コード記述)
df2.dropna(axis=0)
(結果)

ということが分かりました。
今日はここまで。
なんだか、今日はお昼頃から腰が痛いので、ここまでにします。
公式テキストでは、244ページの途中まで。
今回は、直接DataFrameを作成すること、Google Colaboratoryに用意されたサンプルデータからcsvファイルを読み込むこと(これは、道草の中でも勉強したので嬉しいですね)、pandasでの欠損処理について「dropna」を習得し、何も指定しないと行方向に削除、「columns」をしているすると列方向で削除。axis=1でも同様で、0にすると行方向となることまで確認しました!
今回も10ページしか進んでいない・・・次は倍くらい進もう!