開発と事業を繋ぐ!SREのオブザーバビリティ戦略 ~開発者体験UPで、全員幸福なサービス開発へ~

オブザーバビリティによる開発者体験の向上
エンジニアがコア業務に注力
インフラメトリクスではなく、ユーザー視点のモニタリングによるアラートの最適化
原因のボトルネックへのドリルダウンを高速に、かつ俗人化しない体制へ
コミュニケーションの効率化
SLI/SLO運用により、共通指標をもとにしたコミュニケーションで開発速度と信頼性を両立
事業サイドと開発サイドで共通指標を持ち、顧客への価値提供を最大化
レバテックが抱える戦略と課題
システム戦略
事業をより加速させるための、システムのToBeへ近づけていく
リアーキテクトプロジェクトが進行中
&
リアーキテクト前の既存システムの運用
リアーキテクトのリリースをビッグバンでは行わず、ドメインごとに切り分けて段階的なリリースを目指している
CTO、事業目線
既存システムの運用
なるべくこれまで以上の安定的な運用
引き続き小中規模の機能改修
リアーキテクトプロジェクト
なるべくリアーキテクト部分のリリースの際に業務、事業影響が出ないように
機能要件
非機能要件
なるはや
システム戦略のプロジェクトを完成させ、その後継続的な運用をするために以下の要素が必要
既存システムの安定稼働
リアーキテクトシステムのリリース時の品質担保
SREの立ち位置
レバテック開発部の中の横断的組織
各ストリームアイランドチームには属さない
複数の開発チームを跨いだ大きい運用課題に取り組むため
特定のチームに属すとそういった課題に取り組むことが難しい
システム戦略を進めていくうえでの課題
既存システムの運用課題
システムの複雑な内部構造
マイクロサービスを採用しているが、サービス同士の通信が多く発生し、メトリクスやログだけで通信を追うのが難しい
レガシーなコードによる認知負荷の高さ
長くいないと把握できない部分などの属人化
サービスの信頼性を計測できていない
安定稼働は何を指しているのか
障害は本当に障害なのか、見逃している障害はないか
カーディナリティの高いデータが取得できていない
SLOが下がった時にどのくらいユーザーに影響が出ているか分かりづらい状況
SREとしては開発者体験の向上を重きに置いた

既存システムの運用との戦い方

リアーキテクトプロジェクトのリスク
完遂までのリリース回数が増える
デプロイ失敗率が高いまま回数が多くなると、障害対応時間が膨れ上がっていく
品質が落ちる回数が増えると、開発チームへの信頼度が下がっていく
最悪リアーキテクトプロジェクトのストップがかかるかも?
システムの複雑性は上がる一方
機能やシステムを捨てない限り、システム全体の複雑性は上がっていく
偶有的複雑性は減っていくが、本質的複雑性が下がることはない
遅延した時のリスク
既存システムの苦しい運用がその分継続される
リアーキテクトプロジェクトのリスクとの戦い方
ビッグバンリリースを避けるので、リリース回数が増える

既存システムの運用とリアーキテクトプロジェクトの並行進行

課題に対するSREからのアプローチ
オブザーバビリティの採用
やりたいこと
既存システムの運用作業負荷の軽減
リアーキテクトシステムのデプロイ時の品質担保
プラクティス
システムの内部構造の可視化
新たな実装無しでシステムの状態がわかる
属人性の軽減
信頼性の計測
予測モデルの作成
カーディナリティの高いデータの取得
システムの内部構造の可視化
メトリクス、ログ、トレース、イベントの各テレメトリデータの取得
ダッシュボード、サービスマップの作成
新たな実装無しでシステムの状態がわかる
ツール内に調査に必要なデータが揃っている状態
※ツールを導入するだけで、この状態が作れるわけではない
→New Relicを採用
属人性の軽減
システムの内部構造にある暗黙知の量が抑えられている状態
会社に長く在籍している人ではなく、システムに関心のある人が、データを追うことによって自分で調査できる
→人が見やすいようなダッシュボードを作成
取れないデータは実装してダッシュボードで可視化できるように
テレメトリデータの取得
APMを利用
トランザクションデータ、レイテンシー、スループットの可視化
サービスマップの自動作成
トレース情報から自動で通信状態を可視化してくれる
各サービスに対して設定したアラート状態を色で可視化


信頼性の計測
SLI/SLOの設定
SLM(Service Level Management)の活用
予測モデルの作成
システム内の相関性
システムとビジネスの相関性
↑これを見つけることでシステムの価値がわかりやすくなり、投資の判断もしやすくなる
カーディナリティの高いデータ取得
どんなユーザーに、どういう時に、どんな影響が出ているのか
数値の変化に対して原因分析がしやすい
SLO達成率
SLIの推移
リリースタイミングでの変化
エラーバジェット管理
良いイベント/有効なイベントの可視化
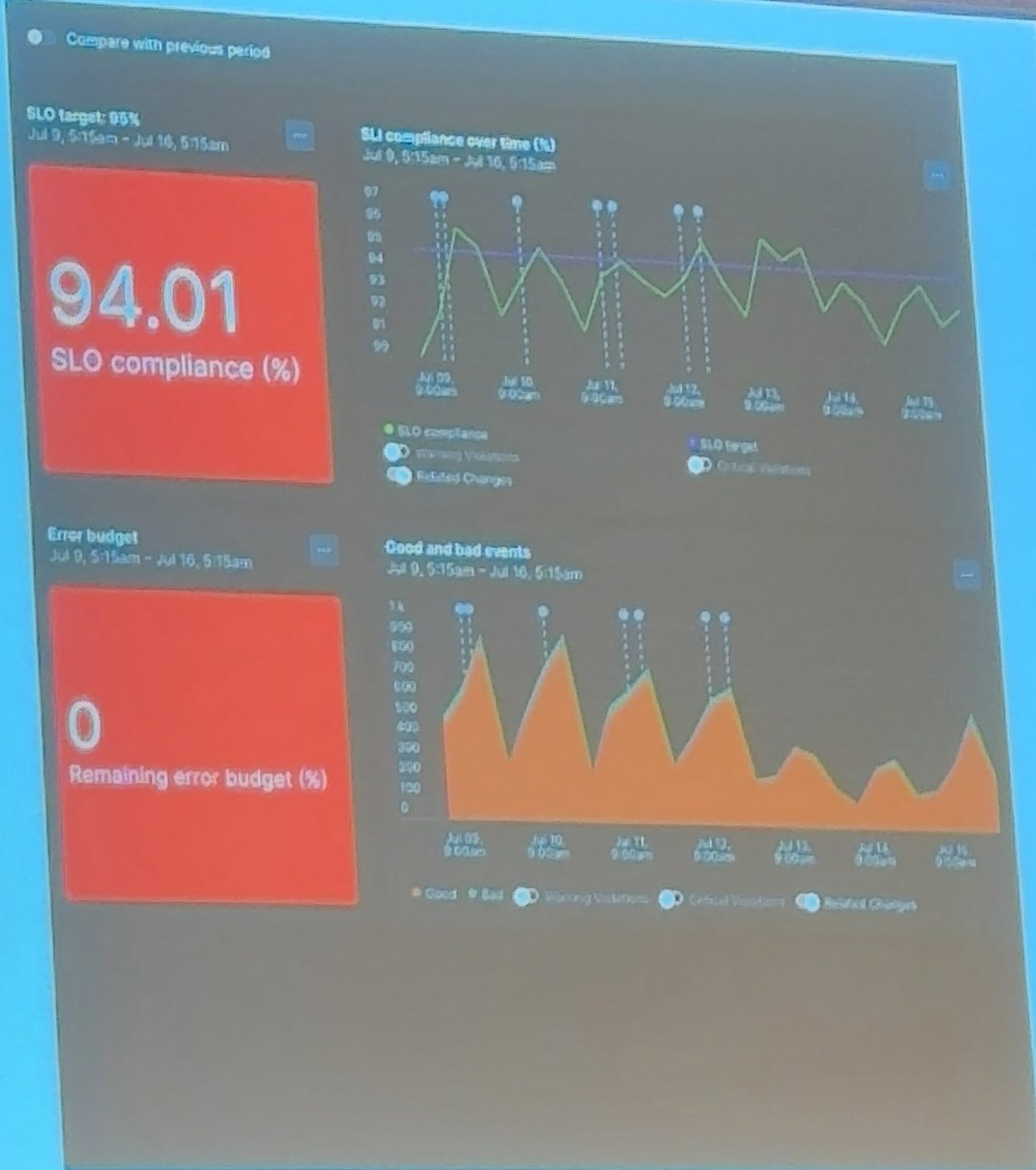

結果として
見込める効果
開発者体験UP↑
障害対応時間の減少
システムの内部構造の把握によって、原因分析のループに最適化していく
「未知の未知」に対する対応をしやすい状態に近づけていく
オオカミ少年アラートの減少
ユーザー体験を重視した、対応する必要のあるアラートだけ鳴るように改善していく
機能開発により集中できる状態へ
デプロイ失敗率を抑えていく
運用作業のコントロール
システムのパフォーマンスがSLOを満たすレベルを維持し続けるために機能開発と積もり積もった運用作業の優先度付けを適切に行なっていく
オブザーバビリティ(O11y)を実現するまでの道のり
マイルストーン
フェーズ1
O11yの理解
ツール移行
アラート改善
フェーズ2
SLOの設定
障害対応改善
ツールの移行、アラートの改善
移行の推進
New RelicアラートのTerraformライブラリを作成
New Relic合宿
GWの中日にあった平日3日間で、出勤している開発部メンバーでアラートの移行作業を行なった
その間SREチームががっつりサポート
アラート勉強会
ユーザー体験視点でのアラート作成をNew Relicを使ってハンズオンを実施
今の所の進捗と効果
社内事例
New Relicっをサービス運用改善に活用できているか
ツール移行(New Relicへのツール移行がどの程度進んだか)
マイルストーン作成時、ツール導入を目標としていたシステムは無事完了
追加で導入を希望するシステム、チームが出たのでそちらにも導入済み
合計で30システムに導入完了
アラート品質(オオカミ少年アラートはどの程度減らせたか)
導入したシステムは全てアラートをNew Relic管理に移行済み
一部SendgridなどSaaS連携部分は既存のツールを使用中
Criticalアラート発報数/1週間(6/2〜7/16)
234→157(4割減)

New Relicでどう見えるの
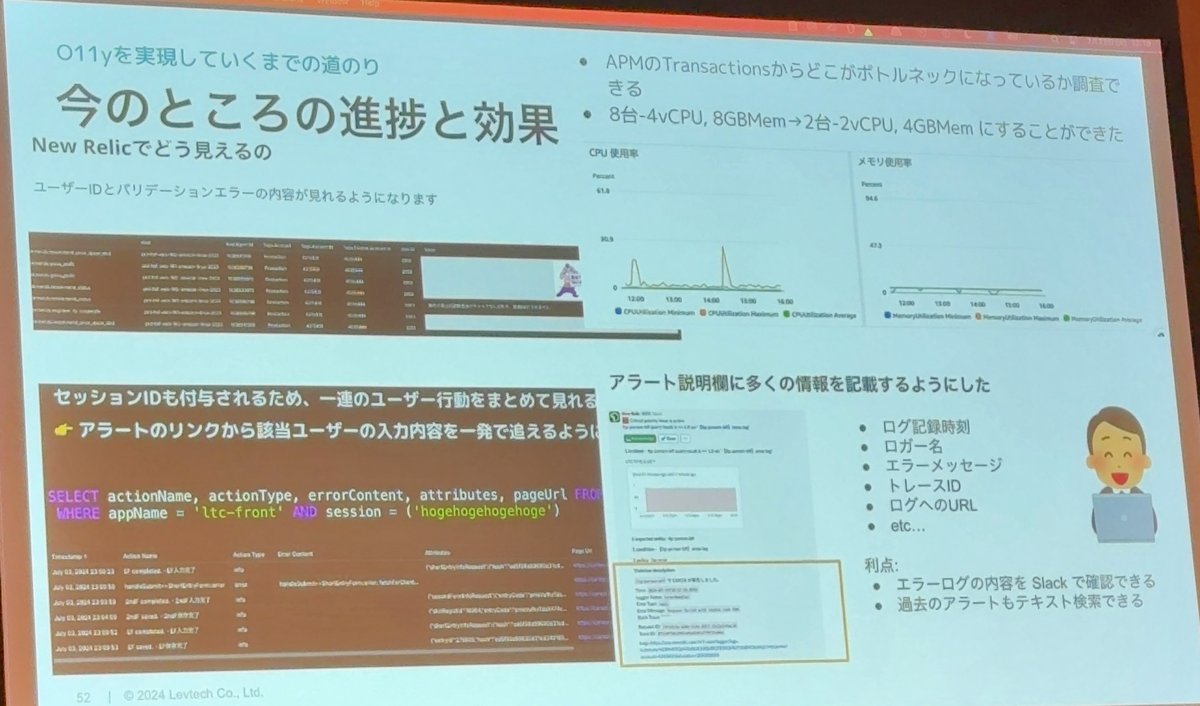
定性面での効果測定
O11yの浸透度
勉強会アンケート
開発者体験
エンゲージメントサーベイ

振り返り
なんでこのアプローチを半年間やりきれたか
SREチームを横断組織として起き続けた
O11yを複数の開発チームを巻き込んで導入できた
開発部のカルチャー
勉強会が盛ん
新しい技術や考えに抵抗感が少ない
経営陣、CTOの方針
リアーキテクトプロジェクトを走らせるように、今は開発に投資をしていくフェーズとしている
システムの安定性と変更容易生を高める施策はどんどんやっていきたい
新規マイルストーン
観点
SLO設定
障害対応改善
評価指数
ビジネスクリティカルなシステム群に対するSLO設定数
障害対応指標
MTTR
MTTI
まとめ
システム戦略と課題
既存システムの運用とリアーキテクトプロジェクト
運用負荷の大きさとデプロイ品質の担保の必要性
SREの課題へのアプローチ
O11yの導入
システムの内部構造の理解による認知負荷軽減
信頼性の計測
O11yを実現していくまでの道のり
O11y成熟度でのフェーズ分け
フェーズ2へ