
スタートアップで直面する開発チームの問題をどう解決するか?(後編)

はじめに
こちらの記事は、スタートアップで直面する開発チームの問題をどう解決するか?(前編)の続きになります。
アーリーステージのスタートアップで直面する開発チームの課題について、私自身、これまで何回か経験し改善に向けて対応してきたことをまとめてみました。
皆さん、大体ご存知か、実践している内容かとは思いますが、初めて直面して悩んでいるEMの方や、これからそういった環境で働こうとしているEMの方の少しでもお役に立てればと思います。
よくある問題
まず最初に「リソース足りない(資金もない)」問題が根底にあり、そこを起因として、いくつかの問題が発生するケースが多いかと思います。
よくある問題の例
開発ラインが複数確保できない(1チーム or 数名で全てに対応する)
新規機能と既存機能の改善と不具合対応が一気に押し寄せてくる
判断や作業が属人的
とにかく忙しい
ざっと挙げるとこんな感じでしょうか?
経験したことがある方は「はいはい、あるある。あの時は懐かしかったなー」と思っているかもしれません。
これからそれぞれの問題について、どう対応するか考えていきます。
前編では、「リソース足りない問題を考える」をテーマに考えましたが、今回は、「新規機能と既存機能の改善と不具合対応が一気に押し寄せてくる」をテーマに考えます。
新規機能と既存機能の改善と不具合対応が一気に押し寄せてくる問題を考える
この問題の根本原因は、リソースとやることのバランスが崩れているのが原因になります。
とはいえリソースが増えるまで、この状況をひたすら耐えればいいのか?ということでもないと思うので、この状況でどう解決すればよいのかを考えていきます。
この状況では、おそらく下記のようなことが、同時多発で発生しているかと思います。
新規機能(スケジュールされたもの)
PMFしてないので要件変更多発し、さらに短期開発
既存機能の改善(スケジュールされたもの or 都度発生)
アーリーアダプターからの要望多発とその対応
不具合対応(都度発生)
スピード重視で品質高くない=不具合多いのでその対応
上記の状況で、何も手を打たないと、”今見えること、重要だと思えることをとりあえずやる”や、”全部最優先で対応”などというゲリラ的な戦法を取らざるを得ず、開発チームのコンテキストスイッチが多くなり、認知負荷(とりわけ課題内在性負荷)が高くなります。
結果、全体のスループットは下がり、プロダクトのグロースが鈍化し、事業への影響が出始めます。
この状態を放置する環境はあまりないかと思いますが、もし放置した場合、いずれはメンバーが去るなどの組織崩壊や事業成長が止まってしまうリスクが高くなっていきます。
では、どうするのか?
答えはシンプルで、「交通整理をする」だけです。
交通整理をして、限りあるリソースを効率的に活かすことに専念します。
色々手法はあると思いますが、私は下記の2つ視点で改善していきました。
組織体制を見直す
プロダクトマネジメント方法を見直す
次でそれぞれを解説していきます。
組織体制を見直す
ロールを決めてローテーションする
(こちらは複数名のエンジニアメンバーがいる前提で実施できることになります。)
メンバー、あるいはチームでロールを決めて、ロールごとに担当領域を割り当てて、集中できる環境を作ります。
例えば、1名(または1チーム)は、既存機能の改善+不具合対応をミッションとし、その他のメンバー(またはチーム)は新規機能開発にフルコミット、という体制を作ります。
担当を明確化することで、「これ誰がやるんだっけ?」問題が解決し、タスクが発生した時点で即座に担当が決まり着手することができます。
ただ、それぞれ専任制にすると、情報のサイロ化が起きやすくなるので、切りの良いタイミングでロールのローテーションを行ったり、開発部門として定期的に情報共有会などの会議体を設置した方が良いと思います。
また、不具合に関しては、もちろん基本は全員で対応することが前提なので、開発メンバー全員で、週ごとや日ごとの担当制のローテーションとしても良いと思います。
不具合対応のイメージとしては、まず最初に調査する人を決める、という感じです。
担当の人やチームが最後まで対応するのではなく、トリアージのための調査を行い、修正できるなら修正する、わからなければ、開発した人、または開発メンバー全員にエスカレーションする、という流れになります。
心理的安全性を高める
プロダクトのグロースに注力していると、技術的負債や低優先度の不具合、非機能要件の対応への時間が確保できなくなり、エンジニアとしては、見えない不安と戦いながら、日々開発を行うことになります。
いわゆる心理的安全性が確保できていない状態なので、いずれ開発チームが崩壊する危険性が伴います。
そうならないためにも、週の20%(20%でなくてもよいですが)を上記の対応に必ず確保する、というルールを定め、そこで継続的に対応できる環境を作ります。
このルールは全社向けに宣言し、理解を得てから実施してください。
そうでないとあらぬ誤解を招くので、他の部門のメンバーへ説明し同意を得てから導入するのがおすすめです。
プロダクトマネジメント方法を見直す
問題が発生している状況では、シンプルにタスクの優先度が明確になっていないので、そこを決められるフローやルールを決めていくことに専念します。
タスクの優先順位付けのルールとフローの構築
まず、すべてのタスクが可視化(バックログ化)出来ているか確認し、出来ていなければそこから始めてください。
方針としては、すべてのタスク全体で優先順位付けをする、になります。
新規機能での優先順位付け、既存機能改善での優先順位付け…と分けてはいけません。
全部を1つのテーブルに広げて考えます。
※新規機能対応チームと、既存機能改善チームと2チーム体制であれば、分けて考えてOKです
優先順位付けの基本ルールとしては、下記になります。
クリティカル度がHigh(後述)の不具合は即時対応する
バックログはRICEスコアなどの定量的なスコアリングを行い優先度を可視化する
部門間での優先順位のギャップは、「優先度検討会」を定例化し、各部門長が集まって協議して決める
「優先度検討会」の前に、各部門でバックログの起票とRICEスコアなどの優先順位付けはしておくこと
デリバリーが決まったバックログは、随時開発チームのプロダクトバックログに移動する
全体のフローは下記のようなイメージになります。
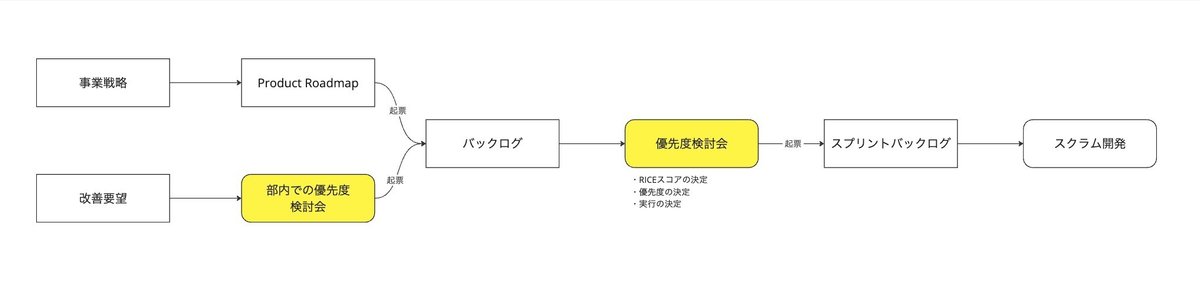
重要なのは、「優先度検討会」です。
例えば、SalesやCSで優先度が一致しない、というケースが多くあります。
Salesは新規顧客獲得に効果のある機能追加や改善
CSはチャーン抑止に繋がる機能改善、問い合わせを低減させる機能改善
部門間のギャップが解消されない状態で、それぞれの部門から開発チームへ優先度を突きつけられるケースがたまに見受けられます。
開発チームが頑張って2つとも対応したり、片方しか対応しない(早い者順でシリアルに対応するなど)、になると、後々問題が起きそうなので避けておいた方が無難です。
そのためにも、「優先度検討会」を開きます。
要するに、部門長が全員集まって、そこですべてのタスクについて優先度を決めて納得すれば、それが関連部門全体での意思決定となるので、もう開発チームが迷うことはありません。
※上記の内容は、SmartHRさんのこちらのブログを拝見し、参考にさせていただいております。
不具合に対しての対応優先度を決める
不具合の発生は予測が出来ず、報告チャネルも様々なので、しっかりと情報を整理する必要があります。
情報の整理のために、不具合のマネジメントルールを決めて、全社向けに説明を行い、全メンバーの理解を得た上で運用を始めましょう。
下記は、最低限やっておいた方がよいものになります。
クリティカル度の基準を決める
どの程度の不具合が即時対応レベルのものか、などなど、全社で統一基準を決めておきます。
そうしておくと、不具合報告があったときに、開発チームのメンバーが不具合のトリアージを行えるようになり、自発的に行動できるようになります。
また、他の部門のメンバーも、この内容を理解することで、今後の対応方法を直感的に把握する子ができるかと思います。
さらに、属人的なクリティカル度の判断がなくなり、建設的な会話が生まれます。(「これは重大なバグです!」「いや、重大ではないです」のような会話がなくなります)
下記は、大まかな例です。(実際はもっと細かく定義します)

不具合はチケット化(可視化)する
ツールはなんでもよいので、まずはチケット化してリスト化し、ステータスがわかるようにします。報告は、Slackのワークフロー経由で報告してもらい、ツールへ自動起票するのが良いかと思います。
ステータスは常に誰でもいつでも確認できるようにする
不具合の対応ステータスはチケットで管理し、いつでも誰でも閲覧可能にしておきます。
いつ不具合が解消されるのかも把握できるようにしておきます。
Jiraであれば、不具合チケットを作成しカンバンで管理を行い、リリースするものをバージョンで管理しておき、それを誰でも見れる状態にしておく、といった感じです。
不具合対応専用のチャンネルを作成し、そこでやりとりを行う
Slackで専用チャンネルを作成して、すべてのやりとりをそのチャンネルで行うようにします。
場合によっては、各チームのチャンネルでも問題ありませんが、できれば状況はすべてOpenにしておくと、誰も不安にならずに済みます。「あ、今こういう不具合が起きているんだな」という認識があると重複報告などはなくなりますし、営業する場合、事前に不具合内容を知っておくと、冷や汗をかかずに済みます。
もしくは、開発チームの責任者やPdMなどが、「今こういう不具合が起きています」という状況を発信する形でも良いかと思います。
とにかく情報共有が重要です。
スクラムの導入
前述でバックログなどの概念が入ってきますし、やはりカンバンやスプリント計画などは導入した方がマネジメントしやすいかと思います。
特にタスクの進行状況を可視化すると、チーム内はもちろん、他のチームにも状況をビジュアル的に共有することができます。
また、スプリント計画などでリリーススケジュールが安定的に実行されるようになると、例えばSalesチーム、CSチームへ「いつ何が出るのか?」を共有することができるので、営業戦略やチャーンの防止などに役立ててもらえることになります。
こういった情報の流れができると、互いのチームでリスペクトが高まり、よいコラボレーションが発生する確率も高くなります。
人は、どうなっているのか状況がわからない、という状況が高ストレスで、よりネガティブな感情が生まれやすくなるので、そこへの解決策にもなったりしますね。
ツールについて
余談ですが、やはり「プロダクトマネジメント方法を見直す」を実現するには、ツールの導入はしておいた方が管理しやすいかと思います。
参考までに、経験上は、Jira+Jira Product Discoveryが便利でした。(Notionでもできるかとは思いますが)
気をつけること
今回テーマとなっている状況下では、開発チームが日々のタスク消化に注力するあまり、視座が低くなる傾向があります。
具体的には、ゴールが開発を完了させる、リリースに間に合わせる、などの目標にフォーカスしてしまい、なぜやるのか?(Why)が抜け落ち、最悪の場合、言われたものを作る「社内受託」のような体制になってしまうリスクが生じます。
そうならないためにも、開発チームへは定期的に事業計画(戦略)、プロダクトロードマップのインプットや、開発担当した機能のフィードバック(特に良かった点を強調する)、PdMとのDiscoveryなどに参加してもらい、なぜやるのかを理解したうえで、開発を進めてもらうようにすると、自然と視座は高くなってくると思います。
しっかりとプロダクト開発に参加してもらう、ということですね。
視座が高くなれば、自ずと貢献意欲も出てくるはずですし、なにより、まだ数名の小さなチームであれば、結束力も高まりやすく、ひとついい流れができれば一気に良い方向に進んでいくと思います。
そんな経験をしたメンバーは、将来、組織が拡大したときにコアメンバーとしてメンバーを牽引してくれるはずです。
そういった意味でも組織のコアを作る重要な時期だと思いますので、しっかり「選択と集中」ができる環境を構築していくのが良いかと思います。