
【Python・Tableau基礎 | PythonでData saber】Order1 fundamental 前編(2/2) a.k.a Newjeans TBS番組出演

分量が長かったので、計4編での分になります。
本題に入るまえに、また、ニュージンズで雑談させてください。
この間の7/13(土)TBSの音楽番組にニュージンズが出演しました!

皆さん、いい感じですが、とにかくハニちゃんがめっちゃくちゃ可愛いです。一人だけ、短髪であることがめっちゃくちゃいいです!💗
6月にリリースしたSupernaturalを歌ってますので、ぜいぜひ聞いてみてください。
それでは残りの問題を見ていけらばと思います。
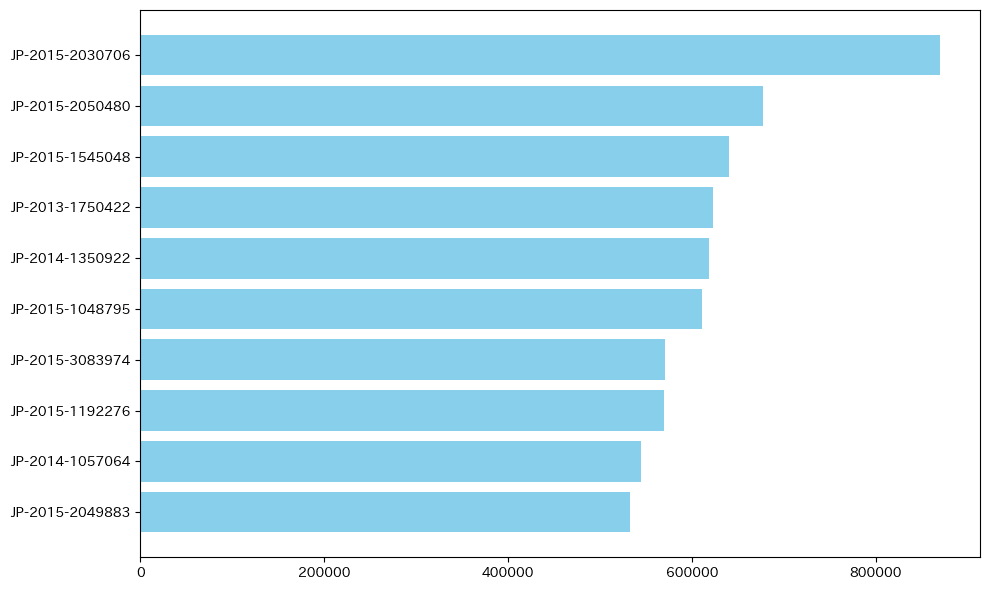
Question4(売上トップ10のオーダーIDを教えてください。) #sort ,groupby,rank横長棒グラフ
今回の問題も単純に、各オーダーIDの総計売上額を集計し、その中で10位になるIDを特定する問題になります。
まずは、どのオーダーIDが10位に入るのか見てみましょう。
オーダーIDをベースに売上を集計してみます。
前回利用したデータフレームを持ってきて、集計させたデータフレームを新しく作成します。
order_sales = df_store.groupby('オーダー ID')['売上'].sum().reset_index()
#集計値を降順に並び替え
order_sales = order_sales.sort_values(by='売上', ascending=False)
これで売上額が大きい順に並ばせました。
そこで10位に入るオーダーIDを特定すればいいわけで、特定する術として以下の二つあると思います。
①10行目に位置しているオーダーID
②ランクをつけて10位の値を持つランクのオーダーIDかと思います。
まず、①の場合ですと、前編でも使った行列数を特定するilocを使い
print(f"売上トップ10位のオーダーIDは:{order_sales.iloc[9]['オーダー ID']}")
→pythonは始まる数字が1ではなく、0からなので10から1を引いた9になります。
実行すると
売上トップ10位のオーダーIDは:JP-2015-2049883
10位となるオーダーIDがどのIDかわかるようになりましたね
次②の場合ですと、ランクを付ける必要があるので、選別したデータフレームにランク列を新しく追加しましょう
order_sales['ランク'] = order_sales['売上'].rank(ascending=False, method='min').astype(int)
⇒rank関数のmethod因数minは、同じスコアを持つデータに対して、そのグループの最小のランクを割り当てさせます。
例:スコアが [10, 20, 20, 30] の場合、ランクは [1, 2, 2, 4] になります。
他にもmax,averageなどがありますが、この場合だと、minから特定することになります。
method因数を使われると、有理数(小数点1位)になるので、astype関数を用いて整数に変換します。
ランクを付けることができましたので、10位となるランクを照会しましょう。
print(f"売上トップ10位のオーダーIDは:{order_sales[order_sales['ランク'] == 10]['オーダー ID']}")
これで①と同じ結果を求めることができます。
さあ、問題に対する答えがわかりました!最後にきれいに可視化してみましょう!前編で順序に表せるグラフは水平線の棒グラフが有効であると説明しました。
同じく作成してみます。
#売上が多い順に並び替えたorder_salesの横長の棒グラフ作成plt .figure(figsize=(10, 6))
plt.barh(order_sales['オーダー ID'].head(10), order_sales['売上'].head(10), color='skyblue')
# x軸の降順に並べ替え
plt.gca().invert_yaxis()
# y軸のラベルが重ならないように調整
plt.tight_layout()
# グラフを表示
plt.show()
ちなみにTableau上ではもっときれいな形(?)になります。

Question5(年月ごと売上の前年比成長率を確認してください。カテゴリごとの成長率を見たときに、2016年の成長率が年の後半に向かってより高く上がる傾向にあるカテゴリは どれでしょうか。傾向は線形で確認してください。) #datetime ,unstack,折れ線グラフ
ついに出ました年月日の日付データ!エクセル初心者のころデータのタイプを理解度が低かった時、日付のデータは文字列として同一視していた苦い思い出があります。
後々、SQLの学習の際、データタイプとして日付独自のタイプがあることを理解し、もはやちゃんと別のタイプとして整理しています。
pythonでも日付データを編集及び利用することができるdatetimeという基本パッケージがあるので、まず、それを読み込んでみましょう。
import datetime as dt
問題を見てみると、カテゴリ別に年間の売上を集計させ、その成長曲線を追っていくようなタイプですね。
集計はgroupby関数を今まで使ったので、使ってみたいところですが、年別に集計しないといけないので、ここはまず、年の列を追加します。
# 年の列を追加
df_store['年'] = df_store['オーダー日'].dt.year
# 年とカテゴリ別に売上を集計
category_sales_all_years = df_store.groupby(['年', 'カテゴリ'])['売上'].sum().reset_index()
print(category_sales_all_years)

年ごとに各カテゴリの売上の総計を取得していますが、年が重複していて個人的には気持ち悪いです。ここは列をカテゴリの要素で並べて、各年毎ごとに集計したピボットテーブルでみたいですね。その際に行データを列に変換させてくれるのが、unstack関数になります。
category_sales_all_years = df_store.groupby(['年', 'カテゴリ'])['売上'].sum().unstack()
print(category_sales_all_years)

これでピボットの前処理は終わらせました!
よく統計学の授業や資格として取っていた統計検定で時系列の可視化は、折れ線グラフ、棒グラフということですが、ここはカテゴリといった凡例が三つも入っているので、折れ線グラフを作成したいと思います。
元々なら凡例値が、列名ではなく、カテゴリ列名での値で含まれているわけですが、我々は見やすくさせるため、その凡例値を列名として持ってきたので、その列名のデータを取得させる必要が出てきます一個ずつ全部取る手段として難しいが、for in 反復文をいれます。
# 折れ線グラフを作成
plt.figure(figsize=(12, 8))
for category in category_sales_all_years.columns:
plt.plot(category_sales_all_years.index, category_sales_all_years[category], marker='o', label=category)
⇒取得先を列名とその列のデータをY軸(売上データ)で設定させたコードになります。少しわかりやすく解説するとカテゴリといった変数は、ピボットデータフレームの列名に指名させたことになります。
# グラフのタイトルと軸ラベルを設定
plt.title('カテゴリ別年間売上合計')
plt.xlabel('年')
plt.ylabel('売り上げ')
plt.legend(title='カテゴリ')
# X軸のスケールを1年単位に設定
plt.xticks(category_sales_all_years.index)
# グラフを表示
plt.grid(True)
plt.tight_layout()
plt.show()
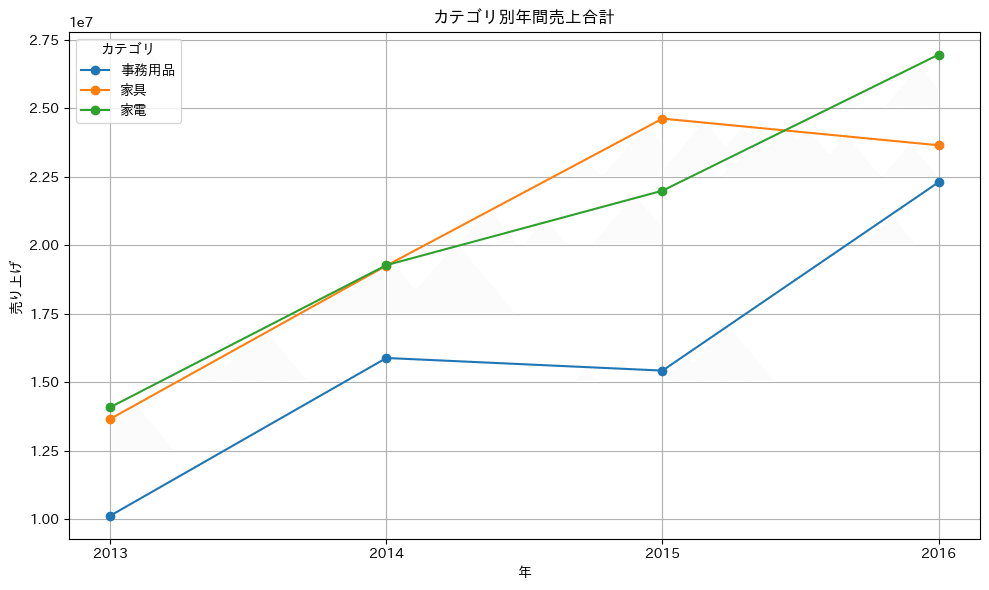
グラフをみてみると、2016年は前年度に比較して非常に上がっているのは、青い線(事務用品)になるでしょうかね?
ちなみに、成長率%を計算して折れ線グラフにしたものがこちらです。

40%超えの成長率で断トツに事務用品の成長率が他のカテゴリよりも高いですね!pct_change()関数を用いて前年比成長率を出せるので興味がある方はやってみてください!やり方は同じです!

上記結果のタブローで描いたものですが、やはりX,Y軸の設定がツールだと自動にきれいにやってくれるので、すごくいいなと思います。。。
Question6("ー"で区切りをして、製品IDのマスター抽出し、売上を集計) #split ,str
これは可視化というよりかは、単純にデータの編集になる部分ですね。
Tableau上でもエクセルと同様同じく、Split関数ですぐ終わらせるですが、pythonも同様に超簡単に終わらせます。一旦製品IDがどのようになっているかみてみると、、、
print(df_store[製品 ID])

カテゴリ-サブカテゴリ-品番?という形ですかね?問題は-で区切り、先頭のデータを持ってくることになります。よくpythonの基礎講座で文字列データのsplit関数の問題で出てくるので、その記憶に頼ってやってみましょう。
#製品マスター列の作成
df_store["製品マスター"] = df_store["製品 ID"].str.split("-").str[0]
⇒基礎講座の際はただの文字列データでありますが、pandasでのデータフレームのデータはseriesデータなゆえ、文字列データに変換させるstr関数を用いる必要があります。
print(pd.unique(df_store["製品マスター"]))
⤵実行結果:['家具' '事務用' '家電']
これカテゴリの値ですね(笑)
ま、製品マスターが出てきたので残りは、groupby関数を使い、売上を集計してそれを基に、売上順での可視化を行えば終わりです。
df_store = df_store.groupby(['製品マスター'])['売上'].sum().reset_index()
#水平線グラフ作成
plt.figure(figsize=(10, 6))
plt.barh(df_123['製品マスター'], df_123['売上'], color='skyblue')
#グラフのタイトルと軸ラベルを設定
plt.title('売上 by 製品マスター')
plt.xlabel('売上')
plt.ylabel('製品マスター')
#グラフを表示
plt.show()

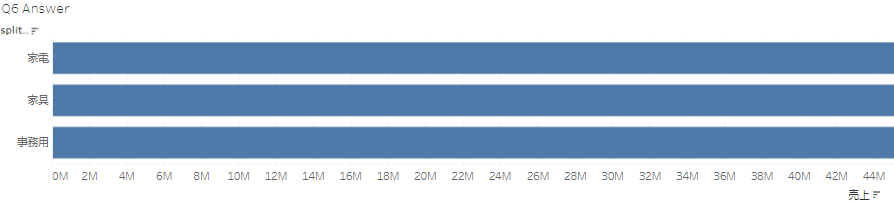
今回は、sort,groupby,rank,split,str,datetime,unstack関数を使い、目的に応じたグラフ(棒グラフ、折れ線グラフ)を作成してみました!
残りの問題も次回の投稿で解説できればと思います!
Auf Wiedersehen!