
【Python・Tableau基礎 | PythonでData saber】Order1 fundamental 後編(1/2) /w 京都国際高校甲子園優勝

さてと、後半の残りの問題もみていきたいと思います。
今回は、結構統計的な可視化にも登場する散布図なども出てくるので、教育的なコンテンツになると思いますが、基礎的な面から使い方など見てもらえると嬉しいです。
本題に入るまえに、ちょうど最近あった夏の甲子園を語らせてください。
高校野球の聖地である甲子園で今年の夏優勝を果たしたのは、京都国際高校になりました。本当に本当におめでとうございます。
関東一高校との延長10回までの、点が入らず最後2:1で接戦し勝負がついた試合でした。実力は本当に紙一重といえるぐらいの試合でしたが、最後勝利の女神が手を挙げてくれた高校は京都国際高校でした。

高名に国際が入る分、前身が朝鮮、かつての在日韓国人向け民族学校で、日本と違い、最大の人気を誇るプロ野球とは異なり、中々高校野球が関心をもらえない韓国現地でも、各種ニュースはもちろん、大統領が祝福してくれるなど、すごく日中話題をトピックになっています。

この優勝によって、単発的な話題で終わるのではなく、韓国でもプロ野球じゃなく、高校野球の人気を増えていくことを祈るだけです。
さて、それでは本題の話に入ろうと思います。
Q7(顧客区分ごとに地域別の売上実績を教えてください。)#pivot_table関数、ヒットマップ表示
各軸に当てはめて集計した売上を問われていることから、よくエクセルでみるピボットテーブルみたいなものですね。
Pythonでも簡単にピボットテーブルを作成できるので、まずはデータを集計してみたいと思います。
一旦、どのような各軸には属性があるか、unique関数を使ってみてみます。
#顧客区分の属性把
print(pd.unique(df_store["顧客区分"]))
#地域区分の属性把握
print(pd.unique(df_store["地域"]))▼結果物
['消費者' '小規模事業所' '大企業']
['北海道' '中部地方' '関西地方' '九州' '関東地方' '東北地方' '中国地方' '四国']
顧客区分が3種類で地域区分よりも項目数が少ないので、列におき、地域区分を行においてピボットテーブルを作成してみたいと思います。
#横軸を地域と縦軸を顧客区分として、売上のピボットテーブルを作成
pivot_table = df_store.pivot_table(index='地域', columns='顧客区分', values='売上', aggfunc='sum')
#ピボットテーブルの数字のフォーマットを1000単位のコンマ(,.0f)に変更
pd.options.display.float_format = '{:,.0f}'.format
print(pivot_table)▽結果物
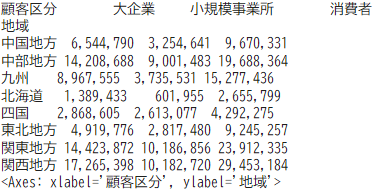
pandasライブラリのデータフレームの表示の仕方を1000単位ごと”,"をつめるようにformatを変更させています。フォーマット変更でデータの寄せなどデータフレーム値の表示の仕方を自由に変更できるので活用してみてください
今回のデータは、小数点があったfloatだったので、float_format関数を使っていますが、データタイプによって適切な関数を選ぶとよいですね!
これだけだときれいに可視化したわけではないので、テーブルのデータの強弱を確認しやすくヒートポンプ化します。
#ピボットされたデータを基にヒットマップを作成
plt.figure(figsize=(10, 6))
sns.heatmap(pivot_table, annot=True, cmap='YlGnBu', fmt=',.0f')
▼結果物

heatmap関数の因数の説明は下記になります。
annot=True: 各セルに値を表示します。
cmap='YlGnBu': カラーマップを指定します。'YlGnBu'は黄色から緑、青へのグラデーションを示します。
fmt=',.0f': 数値のフォーマットを指定します。ここではカンマ区切りの整数として表示されます。
結果物をみると、関西・関東地方の消費者が非常に売上実績が高いことが分かりますね!人口が多い分、それほどお客さんが多いということからこの結果になったんじゃないかと簡単に予想されますね。
Q8.家具と家電の数量を累計で見たとき、差が開く始めるのは何年何月からですか?#datetime,絶対値,折れ線グラフ
ここは、またカテゴリ別で一回数量を集計する必要がありそうですね。
いつもの通りgroupbyでデータを集計してみましょう。だが、今回は時系列別に累計で集計する必要があるので、もう一工程増えることになりますね。
まずは、簡単にオーダー日に対するカテゴリ別の数量を集計した新しいデータフレームを作成します。
#groupbyを使用してサブカテゴリの数量を時系列(年月粒度)に集計
grouped_df = df_store.groupby(['オーダー日', 'カテゴリ'])['数量'].sum().reset_index()
print(grouped_df)▽結果物

次は、累積分布の作成になりますね。年月による累積なので、datetimeを利用し、オーダー日から年月を取得し、そこから家電・家具の数量を累積分布を作成します。
#年月の取得
grouped_df['年'] = grouped_df['オーダー日'].dt.year
grouped_df['月'] = grouped_df['オーダー日'].dt.month
#取得した年月によるグループ化
grouped_df = grouped_df.groupby(['年', '月', 'カテゴリ'])['数量'].sum().reset_index()
#カテゴリによる累積分布列を挿入
grouped_df['累積数量'] = grouped_df.groupby(['カテゴリ'])['数量'].cumsum()
#カテゴリの中、家具と家電だけ抜き取る
grouped_df = grouped_df[(grouped_df['カテゴリ'] == '家具') | (grouped_df['カテゴリ'] == '家電')]
print(grouped_df)▽結果物

groupbyの[].cumsum()メソッドを利用して、累計した数量を取得することができました。
X軸をオーダー日を利用したいことなので、データフレームに一回つけ戻しの作業を経て、カテゴリによる二本線の折れ線グラフを作成してみます。
#累積数量を基に時系列の折れ線グラフ
plt.figure(figsize=(10, 6))
for category in grouped_df['カテゴリ'].unique():
category_data = grouped_df[grouped_df['カテゴリ'] == category]
plt.plot(category_data['オーダー日'], category_data['累積数量'], label=category)
# グラフのタイトルと軸ラベルを設定
plt.title('累積数量 by カテゴリ')
plt.xlabel('オーダー日')
plt.ylabel('累積数量')
plt.legend()▼結果物

こちら、結果になりますね。詳細説明は以下の通りです。
折れ線グラフの作成:
plt.figureを使用して、グラフのサイズを設定します。
forループを使用して、各カテゴリごとにデータをフィルタリングし、折れ線グラフを描画します。
plt.plotを使用して、オーダー日をx軸、累積数量をy軸に設定して線を描画します。
結果を見てみると2014年の9月あたりから、差が開き始めているのが確認できますね!
Q10.サブカテゴリ別の売上と顧客数の間に関連性は見えますか?#相関図、相関係数
売上と顧客数の間で関連性を問われるところですね。大体顧客数が多ければ売上もなんとなく増加するイメージですが、客単価向上による売上向上もあるので、データとしてどうなのかをみてみましょう。
まずは、いつもの通りgroupbyを使い、サブカテゴリ別の売上を集計し、それに加えて、顧客数も重複を排除したIDを基にカウントしてみます。
#サブカテゴリ売り上げ集計
# 「サブカテゴリ」列のデータ種類を基に、「売り上げ」列の売り上げを集計
grouped_df = df_store.groupby(['サブカテゴリ'])['売上'].sum().reset_index()
grouped_df2 = df_store.groupby(['サブカテゴリ'])['顧客 ID'].nunique().reset_index() #重複を排除したカウント
# 集計結果をマージ
grouped_df = pd.merge(grouped_df, grouped_df2, on='サブカテゴリ')
# 集計結果を表示
print(grouped_df)▼結果物

関連があるのかを相関係数を確認してみてましょう。
王道として使われるピアソンの相関係数を出してみます。
#相関係数
from scipy.stats import pearsonr
correlation, p_value = pearsonr(grouped_df['売上'], grouped_df['顧客 ID'])
print("相関係数:", correlation)
print("p値:", p_value)▼結果物
相関係数: -0.0002620312396110526
p値: 0.9992036466893343
数値だけみると、あんまり相関性があるとはみえないですね。。。。
この係数だど相関図も結構バラバラに散乱しているようです。
実際相関図を作成してみました。
# 相関図の作成
plt.figure(figsize=(10, 6))
sns.scatterplot(data=grouped_df, x='顧客 ID', y='売上')
plt.title('売上と顧客数の相関図')
plt.xlabel('顧客数')
plt.ylabel('売上')
plt.grid(True)
plt.show()▼結果物

やっぱ、ばらばらで顧客数と売上の間には関連性がみれないことがわかります。
Q11.4年間を通じて、顧客数が最も多い曜日はどれですか、その人数は何人ですか?#datetime.day_name,nunique
曜日まで特定して集計する問題ですよね。よく使うエクセルだと表示形式だけ"aaa"にすれば、簡単に表示できる問題なのですが、Pythonでの曜日表示をしてみます。4年といった全期間なので、年度別に集計する必要がなくて一旦安心しました。オーダー日を基準に曜日を出してみましょう。
また、その曜日で顧客ID数を重複除き、集計してみたいと思います。
#オーダー日の曜日を表示するセールを作成
df_store['オーダー日_曜日'] = df_store['オーダー日'].dt.day_name()
#曜日を軸に顧客IDから顧客数をカウント
grouped_df = df_store.groupby(['オーダー日_曜日'])['顧客 ID'].nunique().reset_index()
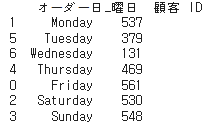
print(grouped_df)▼結果物

一番多い顧客数であった曜日は金曜日で561人ですね!
このテーブルだけでは、物足りないため、可視化までしてわかりやすくさせてみたいと思います。
まず、曜日を顧客数での降順ではなく、月・火・水。。。といった順序に
pandasライブラリのデータタイプはdtypeといった特殊のタイプであるため、基礎の時やったリスト型の変更をさせることとは違い、一回リスト型に変えさせる必要があります。その時に使われるのはpandasのCategoricalメッソドです。
自分のやり方としては、月・火・水。。。といった曜日順序通りのリストを作成し、リストにカテゴリされたデータフレームの曜日の順序で指定させます。
# 曜日の順序を指定
days_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
# オーダー日_曜日列をカテゴリ型に変換し、順序を指定
grouped_df['オーダー日_曜日'] = pd.Categorical(grouped_df['オーダー日_曜日'], categories=days_order, ordered=True)
# オーダー日_曜日列で並び替え
grouped_df = grouped_df.sort_values('オーダー日_曜日')
# 結果を表示
print(grouped_df)▼結果物
指定した順に並び替えたことで、そのまま棒グラフで出します。
今回の場合は、実際の数字もみたいことなので、棒の上に顧客数(y値)も付けます。
#棒グラフの作成
plt.figure(figsize=(10, 6))
plt.bar(grouped_df['オーダー日_曜日'], grouped_df['顧客 ID'])
#y軸の範囲を700まで設定
plt.ylim(0, 700)
#棒の上に数値を表示
for i, v in enumerate(grouped_df['顧客 ID']):
plt.text(i, v, str(v), ha='center', va='bottom')
#グラフのタイトルと軸ラベルを設定
plt.title('顧客数の多い曜日')
plt.xlabel('曜日')
plt.ylabel('顧客数')▼結果物

きれいですね!(笑)
plt.textメッソドを使い、各棒の上に顧客数を表示しました。
今回はこれまでにして、また次回にお会いしたいと思います!