
Androidアプリでドラム演奏のリアルタイム推論

モバイルでの推論を行うことを前提とした、モデルの構築からアプリの実装までのおおまかなメモです。
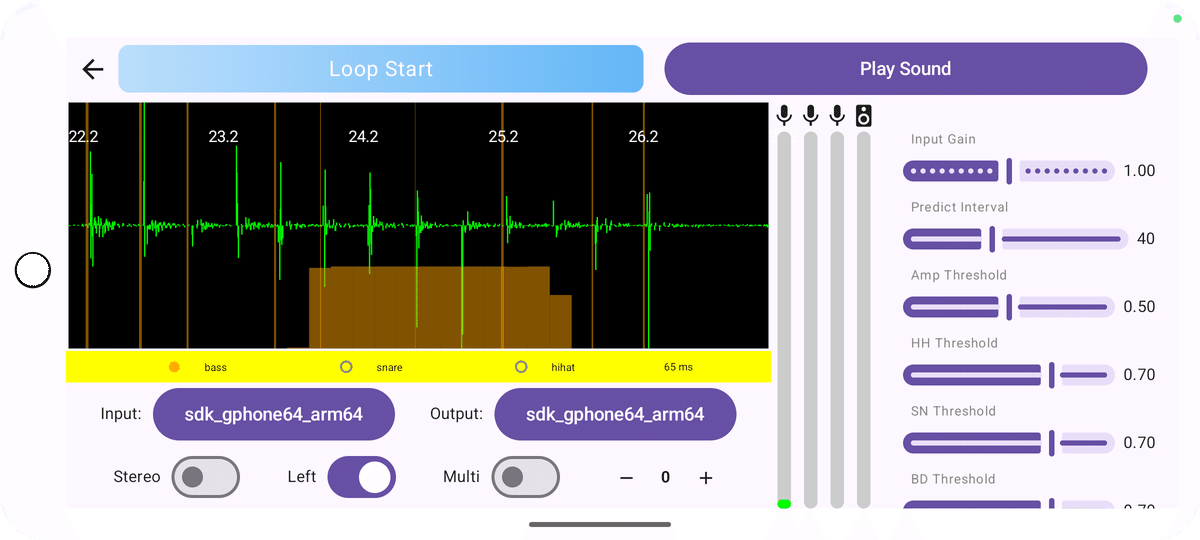
モバイル画面
現時点の推論を試す画面です。ひとまず何を変更すればどのようになるのかを検証するための画面となっています。確認したい項目が多いのでみっちみちです。
・入出力デバイスの変更
・テストオーディオの再生
・入力チャンネルの切り替え
・入力ゲインの変更
・各種閾値の変更
・入力波形、入出力レベルの表示
・推論状態の可視化
フレームワークの選定
普段使いはほぼiOSのデバイスなのですが、Pixel8を活用したいためAndroidで進めることにしました。iPad miniの方が持ち運びやすさや画面の大きさがいいなと思っていますがそちらは後ほど進めたいと考えています。
また、推論モデルはモバイル用に変換することを前提としていたので、TensorFlowとしました。PyTorchからは少し苦労した覚えがあるので、TensorFlowからTFLiteへの変換とモバイルとの親和性に期待したところです。
CoreMLまで変換するかは後ほど検討したいと考えています。
モデルの構築
まず、普通に推論モデルを構築し、学習済みのモデルを保存しておきます。
そして、モバイルでは算術関数のライブラリが充実していないので、外部ライブラリとしても期待するものが無い場合は、tf.functionとして作成しておきます。
最終的にモバイル変換用モデルとして、推論モデルや算術関数などを含めたものをビルドします。
なお、モバイル側でどこまで入力データを用意できるか確認した上でモバイル変換用モデルを準備することになります。入出力の形状は固定となるため、モバイルのオーディオ入力の最低バッファサイズなども考慮しながら構築しました。

tf.signal.stftなどは使いやすく、推論モデル構築のデータセット作成時に使用していましたが、虚数を扱う計算はTFLite変換時にオプション指定などが必要となるため独自実装しました。
Androidで使えるライブラリで探したのですが、標準では用意されておらず、外部ライブラリも更新が古かったり、期待するものを探しきれませんでした。
モバイル用モデル変換
モバイルで使えるようにTFLiteへの変換ですが、`custom op`や`flex op`のエラー?はモバイルで正常に扱えるか分からないので、このエラーを解消するように算術関数などを修正しながら進めました。
なお、変換後のモデルのパラメータの順番が想定しているものと異なる可能性があるので、後々つまずかないように以下のように確認しておくのが良さそうです。
interpreter = tf.lite.Interpreter(model_path=tflite_model_path)
interpreter.allocate_tensors()
# 入力テンソルと出力テンソルの詳細を表示
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print("入力テンソル:", input_details)
print("出力テンソル:", output_details)Androidへの組み込み
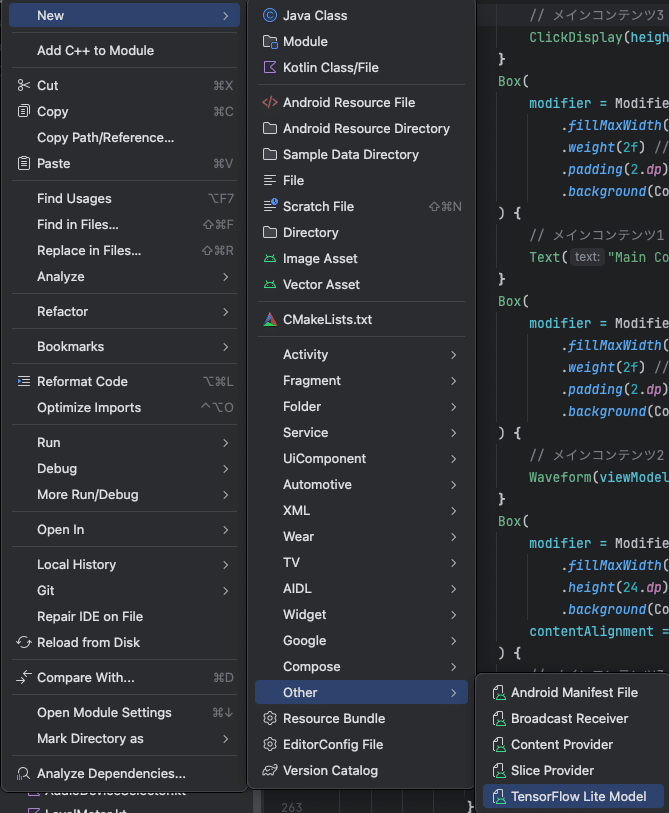
Android Studioを使っていると、プロジェクトを右クリックで「New」->「Other」->「TensorFlow Lite Model」を選択すると、モデル選択のダイヤログが表示されるのでそれに従うだけで導入できます。
なお、推論モデルを追加すると使用方法も表示されるので分かりやすいです。
ただ、推論結果は多次元を想定していてもフラットな出力となるようなので?期待する形状へ変換する処理が必要です。
なお、GPUを使うか、という選択肢もあるのですが、Pixel8の場合は明確なGPUというものが無さそうで?TensorCoreがいい感じに使われる?ようなので、GPU用のライブラリは追加せずに進めました。今の所推論性能も悪く無さそうです。
ちなみに、算術関数のみをモデル化してTFLiteへ変換することで、ベクトル計算のようなものは高速処理できるのは良かったです。
人によっては、ネイティブでがんばるよりもさくっと出来るかもしれません。
Androidでのオーディオ入力処理
オーディオ入力の扱いがモバイルアプリ実装での結構なウェイトを占めていると思います。
オーディオデバイス詳細の可視化
画面でもデバッグログでもいいと思いますが、各オーディオデバイスの詳細を確認できるようにしておくと処理を実装する際にもスムーズに進められると思います。

チャンネル構成
選択するオーディオ入力デバイスによって、L/Rの2チャンネルの構成なのか、MultiChannelのような構成なのかが変わり、それに合わせてモノラルデータ取得やチャンネルインデックス指定のデータ取得などがあるので、構成と目的を考えながら整理する必要があります。
今回はPCで使っていたUSB-C対応の外部オーディオインターフェースも試してみたいのでMultiChannelでも入力できるようにしました。
サンプリングレート、ビット深度、エンコーディング
オーディオ入力から取得できるバッファの最低サイズなどを計算したり、バッファの型が異なったりしてくるので、この辺りも選択によって処理を整理する必要があります。
ブロッキング、並列処理
リアルタイム性を重視するならば、オーディオ入力のバッファ取得をノンブロッキング処理としておくのが良さそうです。その場合はデータサイズが期待するものになるように切り出しやパディングを考慮しておくのが良さそうです。
また、どのスレッドにするか、どこでスレッドを開始するか、スレッドが親子のようになってしまっている場合は、親スレッドが停止された場合に子スレッドでエラーとならないようにする考慮なども必要です。
オーディオ入力バッファの取得が非同期処理で、その取得したバッファの推論処理をさらに非同期処理にして、としているとオーディオ入力を停止した場合に推論処理がまだ動いているとエラーになる場合があります。
入力ゲイン調整
Android OS(になるのかな?)にまかせた入力ゲイン調整はオートか何もしないだけとなり、ユーザーによるゲイン調整のライブラリは用意されていないようです。なので、ひとまずプログラム的にオーディオ入力バッファを取得した後増減するようにしてみました。
さいごに
調べきれていない部分も多々ありますが、ひとまずここまでの実装メモとして後から見返せるようにしておきます。
ちなみに、バンドスタジオで試してみると、Pixel8でのマイクでもパラメータの調整次第で少しはリアルタイムに推論できているので、入力・推論・結果整理の処理を改善してまた試してみたいです。
USBオーディオインターフェースも持って行って試してみたいところです。
がんがんロックなスタジオだったのでベース音でバスドラが検出されたり(共鳴なのかベース音自体か?)もろもろ改善する部分があるので楽しみです。