
国会図書館デジタルコレクションをOCRする

国会図書館デジタルコレクションは、利用者登録することで複写サービスが必要な一部の資料を、Web上で複写(閲覧)することができます。
資料は印刷することができ、不正利用防止の透かしなどが入った状態でpdf変換されてダウンロードすることが可能です。
PDFを画像に変換する際のdpi
bunkoOCRでは、pdfを画像として変換しOCRをかけていますが、PDFの解像度dpiを指定して画像としての仕上がりpixelサイズを指定します。このときの数値が、100dpi付近がdot by dotになっているのではと思います。
300dpiだとbunkoOCRで失敗する
現在改良中のbunkoOCRのエンジンで、国会図書館デジタルコレクションから適当に選んだ資料をOCRしてみました。このときPDF->PNGに変換する際に300dpiとしました。

コマ番号8の一部を抜粋

縄の文字がOCRに失敗していることが分かります。
きれいに見えるのにどうしてだろう、とよく拡大してみると。


元々の1pixelが、どうやら3pixel程度に拡大されてしまっているようです。
findtextCenterNet(bunkoOCRのエンジン)の学習データの与え方
OCRエンジンを学習する際、色々なサイズで認識できるように画像を拡大縮小や、傾けたり歪めたり、ノイズを与えたりぼかしたり、変形して入力させています。


このとき、画像の拡大縮小に、バイリニア変換を使っています。元のピクセルサイズと変換先が違うときに、ガタガタのエッジになってはいけないので、間の値で補完するようにする変換です。
つまり、bunkoOCRは、ドットがガタガタのエッジの文字で学習していなかったということです。
100dpi相当に変換してOCRしてみる
同じエンジンで、先程の画像を1/3に縮小変換したものを、x3で読み込んでOCRしてみます。


先程失敗した、縄の部分が成功しています。

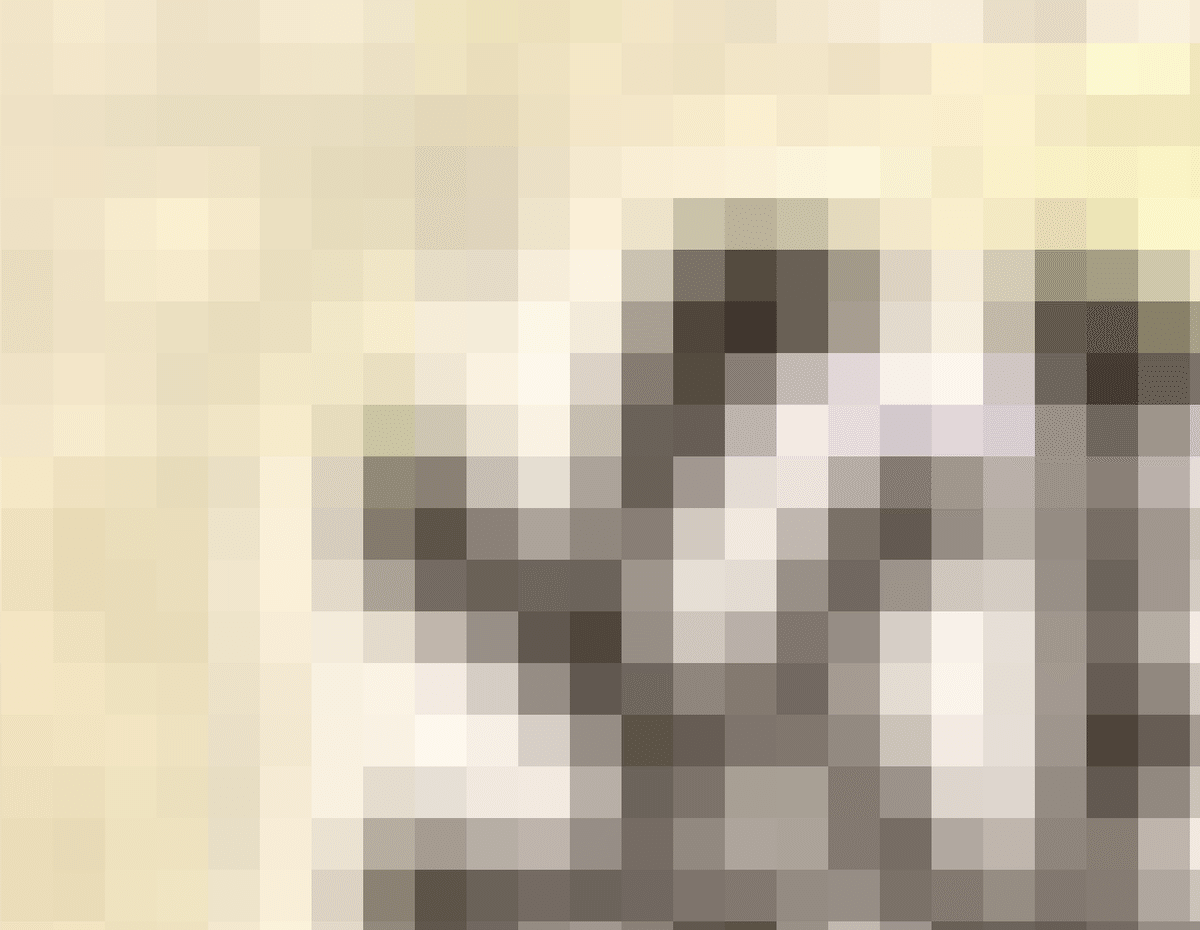
ピクセルサイズまで拡大すると、先程の画像で見られたブロックで拡大されている現象が、ピクセルサイズまで小さくできていることが分かります。
現在の結論
国会図書館デジタルコレクションをbunkoOCRにかける際は、ピクセルサイズが等倍になるくらいのdpi(多分100dpiくらい)で変換し、出てきた画像で文字が50-100pixelに見えるようにリサイズをかけるとよさそう。
エッジが拡大でごつごつしているフォントが読めないのは、今後の宿題とさせてください。