
Agent Laboratory: LLMエージェントによる研究支援の最前線

1. Agent Laboratory の概要

Agent Laboratoryは、研究者が研究アイデアを実現するための支援を目的としたLLMエージェントを活用するシステムです。このシステムは、文献レビューから実験設計、実行、そしてレポート作成までの研究プロセス全体をサポートします。研究者の創造性を補完する役割を果たし、反復的で時間のかかる作業を自動化することで、研究の生産性を向上させることを目指しています。
主な特徴:
柔軟性のある設計: MacBookのような低リソース環境からGPUクラスタまで、さまざまな計算リソースに対応。
モジュラー設計: 文献レビュー、データ準備、実験実行、レポート作成といったフェーズごとに分けられたエージェントが協働。
効率的なワークフロー: 自動化されたタスク管理により、研究者はアイデアの創出や批判的思考に集中可能。
Agent Laboratoryの中心的な目的は、研究者がアイデアをより迅速かつ効率的に実現できるようにすることです。特に、大規模言語モデル(LLM)の力を活用することで、通常の研究プロセスでは困難だった部分を補完します。
次のセクションでは、このシステムがどのように研究プロセス全体をサポートするかを詳しく見ていきます。
2. 研究プロセスの流れ
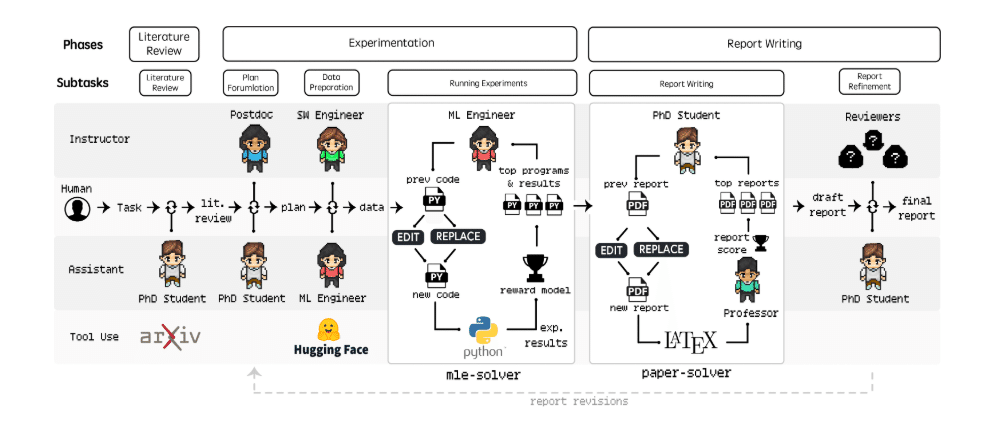
Agent Laboratoryは、研究プロセスを以下の3つの主要なフェーズに分けてサポートします。
文献レビュー: このフェーズでは、関連する研究論文やデータを収集し、分析します。エージェントは、外部ツール(例: arXivやHugging Face)を活用して、関連性の高い文献を抽出し、その内容を要約します。このプロセスは以下のステップで進行します。
データ収集: 検索クエリに基づき、対象となる文献を取得。
要約と分析: 長い論文の要点を短時間で把握可能に。
成果物: 要約レポートや参考文献リストの生成。
実験の設計と実行: 次のフェーズでは、研究計画を立案し、実験を実施します。この段階では、データセットの準備、モデルの構築、評価指標の設定などを含みます。
計画立案: 研究のゴールと方法論を策定。
データ準備: 必要なデータセットを収集および整備。
モデル構築: 実験に使用する機械学習モデルを選定および最適化。
レポート作成: 最後に、得られた結果をもとに学術論文形式のレポートを作成します。paper-solverエージェントがこのフェーズを担当し、データから洞察を引き出し、それを明確で説得力のある形式で提示します。
ドラフト生成: 実験結果の要点を含む初稿の作成。
編集と改善: ヒューマンレビューを取り入れ、最終稿を完成。
これらのプロセスにより、研究者は効率的かつ効果的に研究を進めることが可能になります。
3. MLE-Solver による機械学習問題の解決

MLE-Solverは、機械学習(ML)問題を解決するために設計された強力なツールであり、研究プロセスの中核的な役割を果たします。このソルバーは、以下のような手順で実験コードを最適化します。
入力の処理:
タスクの指示、コマンドの説明、蒸留された知識を入力。
これらの情報を基に、最適化するコードの条件付けを実施。
コードの改良:
2つのコマンド(REPLACE: 全コードの書き換え、EDIT: 特定の行を修正)を活用。
コードの修正後、実行結果に基づいてスコアリングを実施。
エラー修正:
エラーが発生した場合、最大3回の修正試行を行い、それでも解決しない場合は新しいコードを生成。
結果の反映:
成功したコードはスコアに基づきトッププログラムに反映。
各ステップで自己反省を行い、結果をさらに洗練。
MLE-Benchでの評価結果: MLE-Solverは、独立した評価環境であるMLE-Benchを用いてその効果が検証されました。この評価では、以下のような結果が得られました。
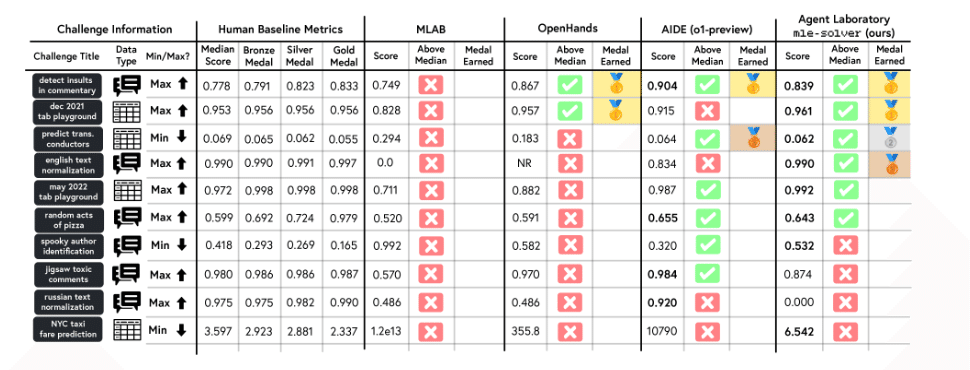
Kaggleコンペティションの10のML課題において、他のソルバーを凌駕する一貫した高スコアを達成。
金メダル2つ、銀メダル1つ、銅メダル1つを獲得。
人間の中央値パフォーマンスを10課題中6つで上回る。
このように、MLE-Solverは高度な自動化と効率的な問題解決能力を備えたツールとして評価されています。
4. Paper-Solver によるレポート作成

Paper-Solverは、研究プロセスの最終段階を担当し、実験結果や洞察を学術論文形式にまとめるためのエージェントです。このツールは、以下のようなプロセスでレポートを生成します。
入力の統合:
研究計画、実験結果、派生した洞察、文献レビューなどを統合。
初稿の生成:
データを分析し、標準的な学術論文フォーマットに従ったドラフトを生成。
構成要素には、概要、導入、方法論、結果、考察、結論が含まれる。
編集と改善:
ヒューマンレビューアのフィードバックを取り入れ、内容を洗練。
書式や引用スタイルを整え、最終版を完成。
ヒューマンレビューによる評価結果: Paper-Solverが生成したレポートは、PhD学生や研究者によるレビューを受けました。その評価結果は以下の通りです。
有用性: 提供された洞察が研究に役立つと評価。
品質: 学術基準において十分な品質を達成。
改善点: 一部のセクションでさらなる精緻化が求められる。
このように、Paper-Solverは研究者が効率的に高品質なレポートを作成するのを支援する重要な役割を果たしています。
5. LLMエージェントの評価と比較




LLMエージェントは、その性能や結果の品質が多角的に評価されています。本セクションでは、3つの主要モデル(gpt-4o, o1-mini, o1-preview)の生成品質と、それに基づく人間レビューアの評価結果を比較します。
生成品質の比較:
gpt-4o: 実験品質が最も低いが、実用性においては比較的高いスコアを記録。
o1-mini: 実験品質で最高スコアを記録し、他の2モデルと比較して安定したパフォーマンス。
o1-preview: 全体的に高いスコアを獲得し、報告品質と実用性で最良の結果を達成。
人間レビューアによるスコア分析:
平均スコア: o1-preview > o1-mini > gpt-4o の順。
特定の研究トピック(例: 画像ノイズ、認知バイアス)でスコアが大きく変動。
結論: o1-previewが全体的に優れた性能を示した一方で、gpt-4oはコスト効率の高さで際立っています。各モデルは用途に応じて適切に選択されるべきです。
6. コストとパフォーマンスの評価
コストと実行時間の観点から、各エージェントの効率性を評価しました。
実行時間:
gpt-4o: 全ワークフローを1165.4秒で完了し、最も高速。
o1-mini: 3616.8秒を要し、gpt-4oの約3倍の時間がかかる。
o1-preview: 6201.3秒で最も遅い結果となる。
コスト:
gpt-4o: 全体コストは$2.33で、最もコスト効率が高い。
o1-mini: $7.51と中程度のコスト。
o1-preview: $13.10で最も高額。
フェーズ別評価:
レポート作成フェーズが最もコストと時間を要する。
gpt-4oはすべてのフェーズで他モデルを上回る効率性を示す。
結論: gpt-4oは、時間とコストの両面で最も効率的であり、リソースが限られている場合に最適です。一方、o1-previewは高品質な生成結果を提供するものの、コストと時間の面で課題があります。
次のセクションでは、「7. 関連研究と今後の展望」について詳述します。
7. 関連研究と今後の展望
LLMエージェントを活用した研究支援システムは、Agent Laboratory以外にも多くのプロジェクトで実現されています。本セクションでは、それらの関連研究を紹介し、今後の展望について議論します。
関連研究:
Virtual Lab: Virtual Labは、LLMエージェントを活用して科学者がSARS-CoV-2の変異株に対応するナノボディ結合剤を設計するプロジェクトです。人間研究者の高レベルなフィードバックを取り入れることで、新しい発見を実現しました。
ChemCrow: 化学分野に特化したLLMエージェントであり、自律的な実験設計と実行を行います。
ResearchAgent: 研究アイデアの生成から実験設計、さらにその結果のレビューまでを自動化するエージェントです。
AI Scientist: 全自動の科学的発見プロセスを可能にするエージェントで、実験実行や学術論文の生成まで含まれます。
Agent Laboratoryの位置付け:
Agent Laboratoryは、これらのシステムの強みを取り入れつつ、文献レビューからレポート作成までの全フェーズをカバーする点でユニークです。
柔軟な設計により、さまざまな計算リソースに対応可能であり、幅広い研究者に適用できます。
今後の展望:
LLMエージェントの精度向上: より高度なモデルを導入することで、研究結果の信頼性と効率をさらに向上させることが期待されます。
ユーザーインターフェースの改良: 研究者が簡単にシステムを操作できるよう、直感的なインターフェースを提供することが必要です。
新しい応用分野: 現在の科学研究に加え、ビジネス分析や教育分野での応用可能性も検討されています。
Agent Laboratoryは、科学的発見の効率化と革新に寄与する重要なツールとして、今後ますます注目されるでしょう。その発展と普及により、研究プロセス全体がより迅速かつ効果的になることが期待されます。
いいなと思ったら応援しよう!
