
MiniGPT4-Videoで動画理解の時代へ

MiniGPT4-Videoという革新的な面白い技術が出たのでまとめました。
MiniGPT4-Videoとは?
動画理解タスクの難しさ
今まで画像認識の研究は順調に進んでいましたが、動画を理解しそれに関する質問に答えることは、これまでのAIにとって非常に困難な課題でした。
MiniGPT4-Videoの登場
MiniGPT4-Videoの登場により、この分野に画期的な進歩がもたらされました。MiniGPT4-Videoは、動画の視覚情報とテキスト情報を巧みに融合させることで、動画に関する複雑な質問に的確に答えることができる革新的なマルチモーダルLLM(Large Language Model)です。
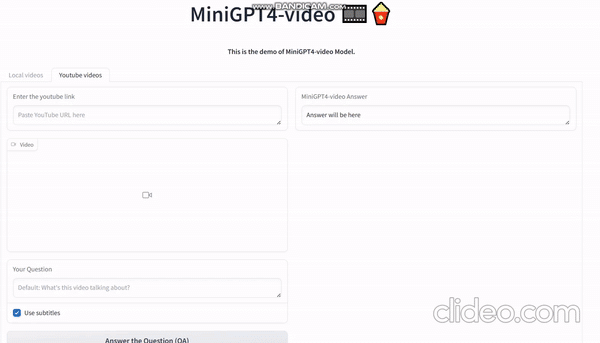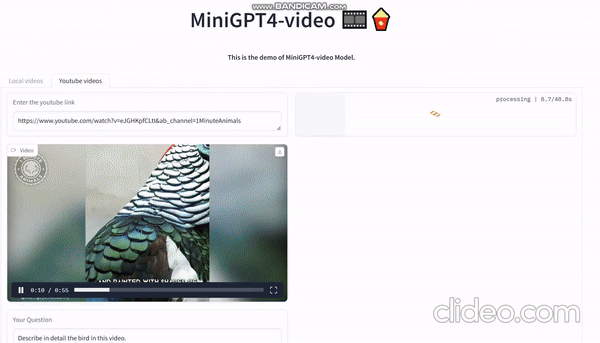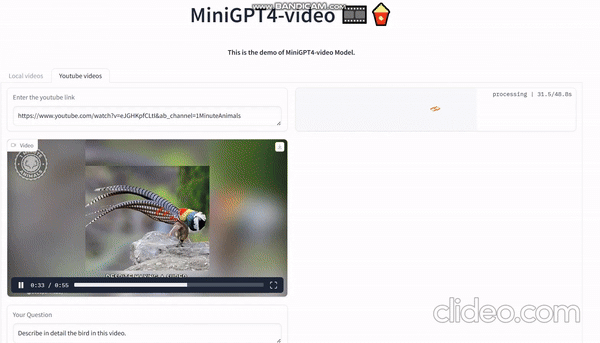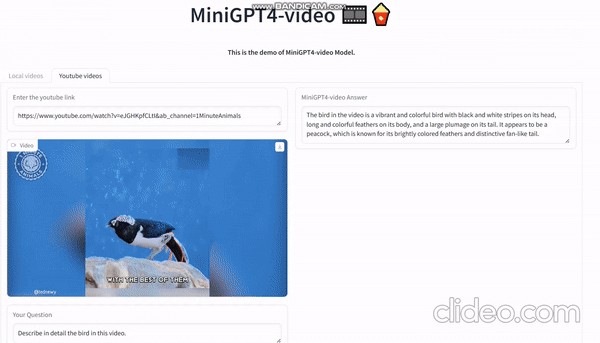
具体的な応用例
例えば、以下のような応用が可能になります:
スポーツの試合の動画を見て、「ゴールを決めたプレーヤーは誰で、どのようなテクニックを使ったのか」といった具体的な質問に答える
料理の動画を見て、「このレシピに必要な材料の分量と調理手順を教えてください」といった詳細な説明を求める
学生が講義の動画を視聴し、「この概念の具体的な適用例を教えてください」といった質問をすることで、より深い理解を得ることができる
視聴者が映画やドラマの場面について、「この登場人物の心情を詳しく説明してください」といった詳細な質問をすることで、作品世界により深く没入することができるようになる。
MiniGPT4-Videoの特徴
革新的な特徴
MiniGPT4-Videoは、以下の革新的な特徴を持つマルチモーダルLLMです:
時系列の視覚情報とテキスト情報を同時に処理し、統合的に理解することが可能
動画の内容を深く理解し、それに関する複雑な質問に的確に回答することが可能
MSVD、MSRVTT、TGIF、TVQAなどの著名なベンチマークにおいて、既存の最先端手法を大幅に上回る優れた性能を達成
技術的な背景
MiniGPT4-Videoは、画像の視覚的特徴をLLMの空間に変換し、様々な画像-テキストのベンチマークで優れた結果を達成したMiniGPT-v2をベースに開発されました。MiniGPT4-Videoは、この革新的な技術を動画に適用し、動画の連続フレームを処理できるように拡張されています。さらに、字幕などのテキスト情報も巧みに統合することで、動画の内容をより深く理解することを可能にしました。

MiniGPT4-Videoを試す
手順
MiniGPT4-Videoの性能を実際に体験するには、以下の手順に従ってください:
リポジトリのクローン
git clone https://github.com/Vision-CAIR/MiniGPT4-video.git
cd MiniGPT4-video環境のセットアップ
conda env create -f environment.ymlチェックポイントのダウンロード
デモの実行
# Llama2
python minigpt4_video_demo.py --ckpt path_to_video_checkpoint --cfg-path test_configs/llama2_test_config.yaml
# Mistral
python minigpt4_video_demo.py --ckpt path_to_video_checkpoint --cfg-path test_configs/mistral_test_config.yaml実行するとdemo画面が立ち上がり、動画をアップロードして色々試すことができます。
MiniGPT4-Videoの未来
様々な分野での応用
MiniGPT4-Videoは、動画理解タスクにおけるマルチモーダルLLMの可能性を大きく広げる革新的なモデルです。動画に関する複雑な質問に的確に答えることができるMiniGPT4-Videoは、教育、エンターテインメント、監視など、様々な分野での応用が大いに期待されます。

動画が未来の「入力」になる日
動画から文字起こしや情報抽出、タスク生成・実行などが自在にできるようになれば、動画はあらゆる知的活動の入力として活用できるようになります。例えば、ビジネスや料理、スポーツ、会議など、あらゆる場面で動画から必要な情報を即座に得られそうです。
未来では、誰もが日常的に動画を撮影し、AIがそこから価値を引き出してくれる時代が訪れるかもしれません。MiniGPT4-Videoの今後の発展に期待です。