
MATLAB で Digital Lossy VST プラグインを作る ~ 聴覚心理特性とは? ~ 非同期バッファで MDCT

まえがき
「Bit Crusher」というエフェクターがあります。量子化ビットを削ったりサンプリング・レート下げたりして「チープ」なレトロサウンドにするものです。
これとは別に、「Digital Lossy」というのもあるようです。ビットクラッシュではなく、MP3のような音声圧縮でビットレートを落としたような「低品質」サウンドにするものです。
非同期バッファや聴覚心理特性を使うので、(他の「Digital Lossy」が聴覚心理特性を使っているかは不明ですが)題材としては面白そう。
使い道があるかどうかはともかく、MATLAB で VST プラグインを作ってみましょう。(要 Audio Toolbox)
VST プラグインの作り方自体は、こちらの記事をご参照ください。
・MATLABでVSTプラグイン開発 [初級編]~数分?で作れるVST~LMSで無相関プラグイン
・夏休みはVST! MATLABで楽々(?)VSTプラグイン開発
MATLAB なら VST 開発も簡単です!( ̄ー ̄)
動作例
まずは実際の音を聴いてみてください。
Digital Lossy VST 動作例 (Mode1-3)
audioTestBench でスペクトルを見てみましょう。
Digital Lossy VST 動作例 (Mode1-3 audioTestBench)
その後、Bass を Retrb Bass に名前を変え、Retrb Treb を追加、新たな処理モード、Mode4-6 を追加しました。
Digital Lossy VST 動作例 (Mode4-6)
Mode1-6 を同じ設定で切り替えてみましょう。
Digital Lossy VST 動作例 (Mode1-6)
Digital Lossy VST 動作例 (Mode1-6)
さらに勢い余って、ピッチシフトも入れてみました。
Digital Lossy VST 動作例 (Mode7-8)
ピッチシフトは、最終的にはアップ/ダウンを Mode7 にまとめました。
(この動画とは少しアルゴリズムが変わりました)
さらに、"Grade(0,100)" を DeGrade(-100,100)" に変更しました。
Digital Lossy VST 動作例(最終版)
詳しくは、「Lossy Codec」の章をご覧ください。
VST2/3プラグイン
この VST 自体の転載・再配布は禁止とさせていただきます。
これを用いて何かを加工するのは制限を設けません。
DAW 等に組み込んで遊んでみてください。
(使用に際し生じた損害に対する責任は一切負いません (u_u))
上の「Digital Lossy VST 動作例(最終版)」が、実際に Reaper で VST を挿して各パラメーターをオートメーションで動かしている例です。
「Digital Lossy VST 動作例 (Mode1-6)」の2つも、Reaper で Mode を自動で切り替えて作りました。
作った本人使い方がよく分かってないので、面白いのができたらぜひ聴かせてください。
聴覚心理特性とその応用
MP3等、比較的近年の音声圧縮には「聴覚心理特性」が利用されています。
信号を周波数的に解析して、人間の耳に聞こえにくい部分を優先して削ることによって、聴感上音質劣化の少ないデータ圧縮を可能にしています。
「MATLABでHRTF~頭部伝達関数とは?~聴覚の仕組みは解明されていない~」で、「聴覚は解明されていない」とタイトルにまで入れてしまいました。
確かに HRTF 関連はそうなのですが、半世紀以上前から分かっていることもたくさんあります。
もちろん、個人差・年齢差等はありますが、特性上、HRTF の個人差のような大きな問題になることはないでしょう。
・最小可聴限界 - (Absolute) Hearing Threshold
人間の耳は、高音から低音まで一様に聞きとることができるわけではなく、3~4 kHz 付近の中音域の音に対しては感度がよく、極端に高域の音や低域の音には感度が悪くなっています。そして、20 kHz 以上の高音や 20 Hz 以下の低音では、音として感じることができません。また、20 Hz ~ 20 kHz の可聴域であっても、当然音を小さくすると聞こえなくなりますが、聞こえなくなるレベルは音の高さ(周波数)によって異なります。その閾値をヒアリング・スレッショルドと呼び、周波数との関係は下のグラフのようになっています(近似式によるグラフ)。

絶対的な音のレベルがこの曲線より低いと人には聞こえないので、音声圧縮する際に、ヒアリング・スレッショルドが高くスペクトル成分の小さい音(特に高域)のビット量を削減することができます。
・(同時)マスキング(Masking)と臨界帯域(Critical Band)
周波数的に近い大きな音と小さな音が同時に鳴ると、小さい方の音が聞こえなくなったり聞きづらくなったりします。この現象をマスキングといいます。また、マスクする側の音をマスカーと呼び、マスクされる音をマスキーと呼びます。
例えば 400 Hz を中心とする狭帯域ノイズをマスカーとし、マスキーの周波数を変えてマスキング量(聞こえないレベル)を測定すると以下のようになります(模式図)。

カーブは高域側になだらかで非対称で、周波数や音圧レベルにより幅も形も異なります。
また、バンドノイズによる純音のマスキングにおいて純音の周波数を中心とするバンドノイズの 1 Hz あたりのパワーを一定にして帯域幅をしだいに広げていくと、容易に予想できるようにマスキング量は帯域幅に比例して増加します。ところが、ある帯域幅をこえると増加せず一定となることが実験で分かっています。この帯域幅をクリティカルバンド(臨界帯域)と呼びます。
これは内耳にある蝸牛の内部構造が、各周波数帯に相当する固有振動数を持つ部分に分かれているためと考えられています。(入り口から奥に向かって高音 → 低音)
大音量に長時間さらされると、蝸牛にある音刺激を神経に伝える有毛細胞が徐々に破壊されます。一旦死滅すると二度と再生されないので、一旦難聴を引き起こすとなかなか改善は望めません。
イヤホンの音量を以前より大きくしないとよく聞こえない、TVの音がうるさいと家族に言われる、話し声が大きいと言われる、などはその前兆かもしれません。大音量を避け、耳を十分休ませるよう気を付けましょう。
話がそれましたが、クリティカルバンド内のノイズは累積されマスキング量が増えますが、クリティカルバンド幅以上に帯域を広げてもクリティカルバンドの外の成分はマスキングには寄与しません。
逆に言えば、そのマスキングカーブ内に他の音があっても音圧が上がっては聞こえませんが、その外にあると音圧が上がって聞こえることになり、ラウドネス測定ではマスキングの影響も考慮されます。
この臨界帯域幅は周波数によって変わりますが、臨界帯域幅で正規化した Bark 単位を用いると、マスキングスレッショルドは帯域に寄らず似た形状になります。Bark は以下の近似式で周波数との変換ができます。
$${Bark = 13arctan(0.76f/1000)+3.5arctan(f/7500)^2}$$
MATLAB の Audio Toolbox には hz2bark(), bark2hz() という相互変換のための関数が用意されています。
また、抹消神経系での処理シミュレーションでは、基底膜上の最大振動位置から導かれた ERB 尺度がよく用いられます。ERB の近似式は以下の通りです。
$${ERBs = 21.4log(4.37f/1000+1)}$$
これも MATLAB では、hz2erb(), erb2hz() 関数が用意されています。

ERBは聴覚モデルとしては良いのですがインパルス応答が求まらない等使いにくいので、インパルス応答を先に定義して求めたガンマトーン(gammatone)フィルタも用いられます。
MATLAB には、このガンマトーン・フィルターバンクを一行で生成・処理ができる gammatoneFilterBank() 関数が R2019a で実装されました。ガンマトーン・フィルターバンクは対称型ですが、これに修正項を入れて非対称にして近似精度を上げたガンマチャープ(gammachirp)フィルターも提案されています。こちらはまだ MATLAB の関数としてはありませんが、その内入るかもしれませんね。
聴覚系においても、ガンマトーンフィルターで近似したり、マスキングがマスカーの高域側だけに及ぶとして簡略化する場合もあるようです。

ERB では低域も帯域幅が変わっていますが、実験で得られた臨界帯域幅は 500Hz以下では一定で、Bark もそうなっています。

・継時マスキング - Temporal Masking
(同時)マスキングは、マスカーとマスキーが周波数的に近い場合でしたが、時間的に近い場合もマスキングが起こります。
後から鳴った小さい音がマスキングされる場合を順向マスキング(forward masking)、その逆に先に鳴った小さい音が後から鳴った大きい音にマスキングされる場合を逆向マスキング(backward masking)と呼びます。
マスキングが起こる時間差は、順向マスキングの場合は約 100 ms まで、逆向マスキングの場合は約 20 ms までとされています。
順向マスキングは、脳内ネットワークのシナプスがまだ興奮状態にあるときに小さな刺激が入ってきても認識されないことで容易に理解できます。
後から入ってきた音で先の音が聞こえなくなる逆向マスキングは少し不思議に思えるかもしれません。
シナプスの興奮は他の複数のシナプスからの刺激の総和が閾値を超えたときに起こり、大きな刺激の方が早く閾値を超えます。逆向マスキングが起こるのは、大きな刺激の方が脳内ネットワークの伝達速度が速くなり、先に起こった小さな刺激を追い越して認識されるためと考えられています。
同時マスキングに比べると効果が小さいためあまり積極的には用いられないようですが、急峻な変化のある信号をブロック毎に圧縮・伸張することによってブロック内に歪みが拡散して生ずるプリ・ポストエコーを認識しづらくする効果があると言われています。
・QMF - Quadrature Mirror Filter
聴覚心理特性は周波数によって特性が大きく変わるので、それを利用するには周波数毎の帯域に分けて処理をする必要があります。
理想的には、例えば帯域を2つに分けた場合、(拡張された)サンプリング定理により、それぞれ元の半分のサンプリング周波数で信号を保持することができます。
しかし、急峻なフィルター特性で帯域を分割して帯域毎に別の処理を施すと、異音が発生する恐れがあります。また実際には、矩形の周波数特性を実現するには無限のタップ長が必要となるため緩やかな周波数遮断特性を使う必要があり、結局帯域がオーバーラップすることになります。その場合、それぞれの信号を保持するのに必要なサンプリング周波数は 1/2 より高い周波数が必要となるため、元よりデータ量が増えてしまいます。データ圧縮をしたいのに、その前処理でデータが増えてしまうのはよろしくありません。
そこでミラーフィルターが用いられます。これは通過帯域を隣とオーバーラップさせながらクリティカル・サンプリングレート(分割後のデータ量が元と同じになるサンプリングレート)でダウンサンプリングを行います。当然折り返し雑音が発生しますが、分析・合成の課程で折り返しと隣接バンドの折り返しのイメージ成分が相殺されるような窓条件を求めることによって、「完全再構成」を可能とします。この条件を満たすのは比較的簡単で、振幅特性が足して1で折り返しの符号が反転すれば良いので窓関数的には自由度が高く、複数帯域分割へも容易に拡張できます。ただしフィルター特性としては制限があるので、実用上問題のない(わずかな)誤差を含む「疑似 QMF」 もよく使われます。

MATLAB の DSP System Toolbox には、この分析・合成 4 つのフィルターを一度に設計できる firpr2chfb() という関数が用意されています。
・MDCT - Modified Discrete Cosine Transform
一方、フーリエ変換等を使って周波数軸にデータを変換して処理を行う方法もあります。この場合、時間軸上でフーリエ変換長にブロックを切って処理を行うわけですが、そのブロックごとに別の処理を行うと、時間軸に戻したときにつなぎ目がなめらかに繋がらなくなってしまいノイズが出ます。そのため時間軸でのオーバーラップ(クロスフェードに相当する)処理が必要になり、この場合もやはりデータ量は増えてしまいます。
「折り返し雑音とは?~なぜ車のホイールは逆回転するのか~デジタルはアナログの近似ではない」で、周波数と時間軸は双対関係にあると書きました。QMFでは時間軸でデシメーションすることにより生じる周波数軸上の折り返し相殺条件を求めたわけですが、それと双対関係の、周波数軸上でデシメーションを行い、時間軸上で折り返しを相殺することも可能であることが類推できます。その折り返し相殺条件を求めたのが TDAC (Time Domain Aliasing Cancellation)です。
これは Oddly Stacked SSB フィルターバンクにクリティカルサンプリングレートへのダウンサンプリングと位相シフトを導入、その上で時間軸での折り返し雑音が相殺されるような窓条件を求めたものです。DCT だけで演算することが可能であり、MDCT とも呼ばれます。もともとは窓付 DCT を全て MDCT と呼んでいましたが、その有効性により今では MDCT と言えば TDAC ベースのものを指すことがほとんどでしょう。
TDAC をフィルタバンクとしてみた場合、同じ分割数の(QMFなどの)周波数領域フィルタバンクと比較すると各バンドの遮断特性は一般的に劣りますが演算量が少なく、同じ演算量で分割数を多く取ることができます。したがって、結果的に高い周波数分解能を実現できます。また、周波数領域フィルタバンクでは困難な、聴覚特性に合った不均一分割が、変換係数のグルーピングにより簡単に実現でき、音質・圧縮効率的に有利とされています。変換符号化の欠点であるプリエコーの発生は、信号の過渡特性に合わせた変換ブロック長の動的切り替えにより、テンポラルマスキングの効果も手伝って抑制することができます。
MDCT も折り返し相殺条件を満たす窓関数は色々ありますが、周波数分解能とサイドローブ漏れのバランスがパラメータで調整可能なカイザーベッセル窓を MDCT 用にした(Princen-Bradley 条件を満たす)カイザーベッセル派生窓がよく用いられます。MATLAB の Audio Toolbox(R2019a ~)ではMDCT に適したN ポイントのカイザーベッセル派生窓が kbdwin(N) で生成できます(デフォルト $${\beta=5}$$)。
カイザーベッセル派生窓の式は以下の通りです。
$$
kbdw[n] = \begin{cases}
\sqrt \frac{\sum^n_{i=1} w[i]} {\sum^{N/2+1}_{i=1} w[i]}
&\text{if } 1\le n \lt N/2 \\
\sqrt \frac{\sum^{N-n}_{i=1} w[i]} {\sum^{N/2+1}_{i=1} w[i]}
&\text{if } N/2+1\le n \lt N \\
\end{cases}
$$
$${w}$$ はカイザー窓で、以下の式で表されます・
$$
w[n] = \frac {I_0\bigg(\beta \sqrt {1-\big(\frac {n-N/2}{N/2}}\big)^2\bigg)} {I_0(\beta)} ,\; 0\le n \le N
$$
$${I_0}$$ はゼロ次の第1種変形ベッセル関数です。
N = 1024;
kbdw= kbdwin(N);
wvtool(kbdw)
窓を分析・合成で2回かけ、オーバーラップさせて足すと1になります。
win1 = wdw(N/2+1:N);
win2 = wdw(1:N/2);
hold off
plot(win1, DisplayName='win1')
hold on
plot(win2, DisplayName='win2')
plot(win1.^2 + win2.^2, DisplayName='sum')
xlim([1 N/2])
ylim([0 1.1])
xlabel('Sample')
ylabel('Amplitude')
legend(Location="best")
title('Analysis / Synthesis Window')
もちろん MDCT も Audio Toolbox (R2019a ~)に実装されています。
時間軸信号 $${x(n)}$$ の MDCT、$${X(K)}$$ の定義式は以下の通りです。
$$
X(k)=\sum^{N-1} _{n=0}x(n)\cos
\bigg[\frac{\pi}{(N/2)}\Big(n+\frac{(N/2)+1}{2}\Big)(k+\frac{1}{2})\bigg],
\\k=0,1,… (N/2)-1
$$
逆変換 IMDCT も同型で、以下のようになります。
$$
x(n)=\sum^{N/2-1} _{k=0}X(k)\cos
\bigg[\frac{\pi}{(N/2)}\Big(n+\frac{(N/2)+1}{2}\Big)(k+\frac{1}{2})\bigg],
\\n=0,1,… N-1
$$
基本的にはフーリエ変換の一部を取りだした形なので、 FFT を利用しての高速演算が可能です。
N が 4 の倍数の場合は、N/4 点の FFT とプリ・ポスト処理を使って求めることもできます。
MDCT によって変換された各係数(フーリエ変換の定義から「係数」と呼ばれます)は、フーリエ変換同様、低次~高次がそれぞれ(折り返し成分を含んではいますが)低周波~高周波成分に当たります。
フーリエ変換と違うのは、DCT 係数のみですので複素数ではなく実数で、N 点のデータから N/2 点のみが得られることです。
ちなみに組み込み系で N を変えて FFT を(自分で組んで)使う必要がある場合、回転子テーブルへのアクセスをビットリバースオーダーで行うように FFT を組むと、N が変わってもテーブルアクセスのポインターがインクリメントだけで済むようにできます。
結局 QMF も MDCT も、信号を各周波数成分に分割して解析・処理するための手法であり、原理的には同じと言えます。
画像圧縮で使われる DCT とはちょっと意味合いが違いますね?
確か、アダマール変換 → スラント変換ときて、スラント変換と基底が似ている DCT 使ってみたら圧縮効率が上がった!?、という流れだったと記憶しています。最初はなぜ DCT を使うと良いのか理論的な理由が不明で、のちに、画像のように2次元の自己相関が高い場合は、(独立性の意味で)最適な変換である KL 変換の基底の良い近似となるから、と説明されていましたが、今はもっとよい説明があるんですかね?
・MPEG-Audio
MPEG-Audio(MP3、AAC)や Dolby Digital(AC-3)などは、これらの聴覚心理特性を利用して聴感上の差が小さくなるような圧縮を行っており、サイコアコースティック・コーディングとも呼ばれます。

MPEG-Audio 規格は、MUSICAMという提案方式を元に LayerⅠ/Ⅱが、それに ASPEC という提案方式を統合する形で LayerⅢ が作られました。
数字が大きいほど処理は重くなりますが、圧縮率が高くなっています。
MDCT は LayerⅢ でのみ用いられます。聴覚心理モデル(Psychoacoustitic Model) は、元々 ASPEC 用の少し処理が重めのと MUSICAM 用の軽めのがあり、どちらでも選択できるようになっています。
MPEG2 の規格化に際し、ビデオはより解像度の高い映像に適した新たな方式が作られましたが、オーディオはすでに圧縮率・音質ともに要求仕様を満たしていたため MPEG1オーディオがそのまま採用され、
MPEG1 オーディオ LayerⅠ/Ⅱ/Ⅲ = MPEG2 オーディオ LayerⅠ/Ⅱ/Ⅲ
となっています(多少の拡張はあったかも?)。
( USB 規格みたいで分かりにくいですが・・)
今では信じられないと思いますが、当初、LayerⅢ(MP3)は処理が重く、「実際には使われないのではないか?」とさえ思われていました。
実際 LayerⅢ は、組み込み系での必須コーデックとしては採用されませんでした。
しかし、PC プラットフォームではエンコードの重さはそれほど問題とならなかったため、圧縮率の高さ(ファイルサイズが小さく高音質)から、Napster 等の影響もありインターネット上で(正式名の LayerⅢ ではなく、拡張子の mp3 として)急速に広まりました。
その後、マルチチャネル対応に際しては、議長が「失敗した・・」と発言するなどちょっと色々ありましたが、後方互換性を捨てることによりのちの AAC 規格等へ繋がっていきました。
MATLAB によるインプリメンテ-ション
またかなり話がそれましたが、ここから MATLAB での実装を見ていきましょう。
・MDCT 非同期バッファを用いたオーバーラップ加算
MATLABには、N 点入れて変換すると N/2 点出てくる MDCT 関数があるのでそのまま使えます。N/2 点の MDCT 係数から元の N 点へ戻す逆変換は IMDCT 関数です。
MDCT を用いた分析・合成を行うには、入力 PCM をオーバーラップさせて取り出し、最後にオーバーラップ加算する必要があります。
「非同期バッファ」は「MATLABでGUI付きアプリ開発 ~ App Designer を使おう(3)~タイマー割り込みでスペクトル表示(非同期FIFOを使う)」でオーバーラップなしで使いましたが、今回はオーバーラップ読み出しも使います。
ステレオの音楽ファイルをストリーミング読み出しして、途中で何もせず MDCT / IMDCT する手順とスクリプトは以下のようになります。
-ファイルから読み出し
-バッファに書き込み
-バッファが溜まったらオーバーラップ読み出し
-MDCT
-IMDCT
-オーバーラップ加算
-(次回)オーバーラップ用データストア
clear
N = 512;
win = kbdwin(N);
mem = zeros(N/2,2); % for overlap add
fileReader = dsp.AudioFileReader('C:\User\audio\JustFeelsRight.wav');
logger = dsp.SignalSink; % for comparison
buff = dsp.AsyncBuffer; % for overlap read
while ~isDone(fileReader)
audioIn = fileReader();
write(buff,audioIn); % write to FIFO
while buff.NumUnreadSamples >= N/2
x = read(buff,N,N/2); % overlap read
C = mdct(x,win,'PadInput',false);
% do something
y = imdct(C,win,'PadInput',false);
logger(y(1:N/2,:)+mem) % overlap add and data logging for comparison with original signal
mem = y(N/2+1:end,:); % store for overlap add
end
end
% care for last block data
x = read(buff,N,N/2);
C = mdct(x,win,'PadInput',false);
y = imdct(C,win,'PadInput',false);
logger(y(1:N/2,:)+mem)
[orgSig,~] = audioread(fileReader.Filename);
recSig = logger.Buffer((N/2+1):(N/2+1)+length(orgSig)-1,:); % trim 1st and last 0 frames
release(logger)
release(buff)
release(fileReader)
figure(1)
tiledlayout flow
nexttile
plot(orgSig(:,1))
title('Original Signal')
ylim([-1 1])
nexttile
plot(recSig(:,1))
title('Reconstructed Signal')
ylim([-1 1])
nexttile
plot(recSig(:,1)-orgSig(:,1),'r')
maxErr = max(abs(orgSig(:,1)-recSig(:,1)),[],'all')
strtmp = sprintf('Error (max error = %4.2e)',maxErr);
title(strtmp)
途中で何も処理をしなければ「完全再構成」されます。

実際に差を見てみると、最大誤差は 6.94e-15 です。16bit PCM の 1LSB の振幅が 1/2^15 = 3.05e-05、24bit PCM で 1/2^23 = 1.19e-07 ですから、「完全再構成」されていることが分かります。
logger = dsp.SignalSink;は比較のために用いてるだけなので、通常のストリーミング処理では不要です。
最初と最後の N/2 は不要な 0 データが入るので、比較に際してはトリミングしています。これも、通常のストリーミング処理では特に必要はありません。
・Lossy Codec
ではいよいよ(やっと)これに、データを壊す処理を入れていきましょう。
MP3 等は、MDCT とは別に FFT 解析を行ってビット割り当てを計算するのですが、ここでは MDCT 結果をそのまま解析にも使いましょう。Dolby の AC-3 はそうやっています。
破壊方法としては、7 種類つくってみました。
1.Mode1 - Cut Lower Power
まず「データ破壊」の方法として考えつくのは、MDCT 係数を大きさで並び替え、指定された "DeGrade" によって小さい順に 0 にしてしまうことです。MDCT を使う以外、聴覚心理特性は利用しません。
音楽信号は通常、高域に行くに従ってパワーが小さくなるのでほぼ高域側から順に打ち切る事になりますが、もし高域側にパワーの大きな信号があればそれはある程度保持されます。
ある特定の係数だけ突然 0 にしているため、ピロピロといういわゆるミュージカルノイズが発生することがあります。MDCT のポイント数を増やせばもっと自然な感じになりますが面白みが減るので、今回はあえて N=1024 としています。
MDCT 関数の返値は 3 次元で、
次元 1:周波数
次元 2:各フレーム(ブロック)
次元 3:チャネル(L/R)
です。
L/R 分けずに同時処理することも可能ですが、分けた方が分かりやすく、L/R 別の処理をしたくなった場合等に便利かと思います。
実は昔からそうなのですが、MATLAB は何でも行列のまま処理した方が必ずしも速いわけではなく、最近は特に for 文とかも速くなっているので、個人的には分かりやすさを優先した方が良いと思っています。VST はネイティブ動作なので速いですし。
2.Mode2 - Cut inaudible
ヒアリングスレッショルドと、フレーム毎の MDCT 係数からマスキングカーブを計算します。
指定された "DeGrade" によってマスキングカーブのオフセットを上下させ、それ以下の MDCT 係数を 0 とします。
ヒアリングスレッショルドの縦軸 SPL (音圧レベル)は 以下の式で表されます。
$${SPL = 20log10(p/p_0)}$$
以前は 単位を dB SPL と表記する場合もありましたが、今は単に dB とします。
基準音圧 $${p_0}$$ は空気中の音の場合 $${20 μPa}$$ であり、ほぼ正常な聴覚を有する人間の 1 kHz の純音に対する最小可聴値となります。
つまり、SPL は実際に再生した時の音圧$${p}$$を測定しないと計算できません。
音声ファイルはどのような環境(音量)で再生されるか分からないので実際の音圧は計算できません。そのため、再生可能な最小レベル信号を $${p0}$$ として設定したりします。
試しに 振幅が 24bit-LSB の sin 波を MDCT してみると
N = 1024;
win = kbdwin(N);
bw = 24;
Amax = 1/2^(bw-1);
Fs = 48000;
f = Fs/16;
t=(0:1/Fs:1)';
x=cos(f*t*2*pi)*Amax;
C = mdct(x,win,'PadInput',false);
20*log10(c)
ans = -147.5863になります(周波数によって値は多少変わります)。
今回は特に正確に設定する必要はないので適当に、MDCT 係数に対して $${po}$$ = -148 dB に設定します。
マスキングスレッショルドは、音楽信号の場合は純音ということはまずないので、狭帯域ノイズに近い扱いとし臨界帯域内の MDCT 係数の平均を取って、その -4dB くらいからとしてみます。
もっとちゃんとやるなら、純音かノイズかを区別して、PSD(パワースペクトル密度)相当を計算して、とかした方が良いと思いますが、今回は「劣化させる」のが目的なので簡略化します。(PSDに関してはここで多少解説しています)
マスキングカーブも本来は左右非対称ですが、臨界帯域のセンター周波数から二等辺三角形で近似し、各バンド境界に相当する MDCT 係数はマスキングの影響を受けないとします。
実際のマスキングが影響を及ぼす範囲は Fig.2 に示したようにもっと広帯域ですが、今回はこれを上げ下げして使うため、クリティカルバンド内としてみました。
その後ヒアリングスレッショルドと重ね合わせ、マスキングカーブを作ります。

3.Mode3 - Quantize inaudible
Mode2 ではマスキングカーブ以下を一様に 0 にしましたが、Mode3 ではマスキングカーブによって量子化精度を変えています。
マスキングカーブ算出自体は Mode2 と同じです。
・Retrv Bass / Retrv Treb オプション
Mode3 まで作って聞いてみたところ、原理通りなのですが、Mode2/3 では Mode1 と違って 4 kHz 付近のボーカルが最後まで残り、リズム系が先に消えてしまいます。なんか 聴覚心理特性も使っていない、思いついてすぐ作れた Mode1 が音楽的に一番面白い感じがしてしまいました。(^^;
なのでオプションとして、低域側の MDCT 係数を復活させる "Retrv Bass" パラメータも加えてみました。リズム系をキープすることができると思います。
単純に、MDCT 係数を低域側から "Retrv Bass" で指定したパーセンテージだけ元に戻しています。
"Retrv Treb" は "Retrv Bass" とは逆に、MDCT 係数を高域側から "Retrv Treb" で指定したパーセンテージだけ元に戻します。
両方とも聴感特性に合わせ、低域側で細かな調整ができるよう、GUI パラメータを Power Parameter Mapping 指定してあります。
'DisplayName','Retrv Bass', 'Label','%', 'Mapping',{'pow', 2, 0, 100}
'DisplayName','Retrv Treb', 'Label','%', 'Mapping',{'pow', 1/2, 0, 100}
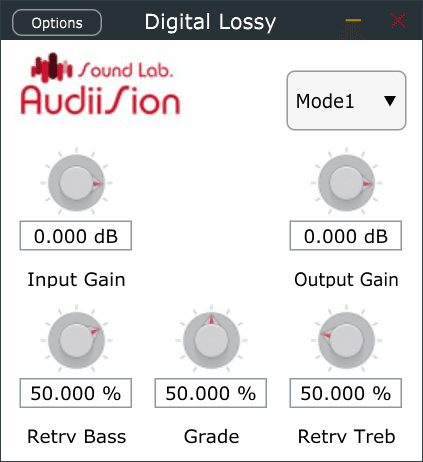
このように同じ 50% でも中央の "Grade" のリニア-マッピングに比べ、それぞれツマミの位置が異なります。
4.Mode4 - Cut High Frequency
MDCT係数全体を、"DeGrade" で指定された低域からの範囲で打ち切ります。
ローパスフィルター効果が得られます。
5.Mode5 - Rotate Frequncy
MDCT係数の順番を、cyclic にシフトします。
当然、めちゃくちゃになります。
音がキンキンしすぎる場合は、"Retrv Treb" を上げてみてください。
6.Mode6 - Time Average
MDCT係数を、フレーム単位で時間方向に移動平均化します。
これも非同期バッファを使い、平均時間分データが溜まったらオーバーラップ読み出しをして平均化することで、移動平均を取ります。
最小約 23ms、最大約 580ms を使って平均化します。
(44.1 k / 48 kHz サンプリング時)
7.Mode7 - Pitch Shifter
MDCT係数の低域から 1/2 だけを取ることによって帯域制限し、リニア補間で簡易的にレート変換をします。
再生のサンプリングレートは変わらないため、音程が変わることになります。
最初はアップ/ダウンを Mode7/8 に分けていましたが、アルゴリズムを共通化し、Mode7 としてまとめました。
ピッチシフトは少し細かく調整したかったため、このモードだけ N=8192 に切り替えています。
"DeGrade" に関しては、Mode1-6 では、DeGrade < 0 の場合は処理結果を元信号から引くことにより、処理の極性(?)を反転しています。
Mode7 では、DeGrade > 0 でピッチアップ、 DeGrade < 0 でピッチダウンになります。
DeGrade = 0 では、効果 OFF となります。
Mode = OFF の時以外は、最後にリミッターが入ります。
MATLAB のアタック/リリースタイムも設定できる limiter システムオブジェクトをそのままデフォルト設定で使っています。
AttackTime = 0, ReleaseTime = 0.2 s です。
ステレオリンクは取っていません。
レベルをいじるダイナミックレンジコントロール系は、左右の適用ゲインを合わせないと適用前後で定位が変わってしまいます。例えばコンプ、DRC 等は「LR 同じ設定」にしても、左右の入力レベルによってゲインコンピューティング結果が変わるので、定位が変わります。「ちゃんとやるとき」は注意しましょう。
ソーススクリプト
classdef DLossy7 < audioPlugin
% Copyright 2022
% AudiiSion Sound Lab. LLC.
% All rights reserved.
properties
inputGaindB = 0;
outputGaindB = 0;
LimitdB = 0;
Quality = 100;
DeGrade = 0;
Treb = 0;
Bass = 0;
dBL; % limiter obj
buff, outbuff, coeffbuff;
N = 8192;
win = kbdwin(8192); % N
mem = zeros(4096,2); % N/2
N2 = 1024;
win2 = kbdwin(1024); % N2
hth = zeros(512,1); % N2/2 hearing threshould
cHz = zeros(512,1); % N2/2 center frequencys of each DCT coefficient
criticalBandCenterFIdx = zeros(1,25); % center frequencys of each critical band in Bark
criticalBandBandaryFIdx = zeros(1,25); % banundary frequencys of each critical band in Bark
cBandIdx = zeros(1,512); % N2/2
minSPL = -148;
ModeC = {'Cut Lower Power','Cut inaudible','Quantize inaudible', 'Cut High Frequency', ...
'Rotate Frequency','Time Averaging','Pitch Shifter'};
Mode = 'OFF';
ModeN = 0;
ModeN_old = 0;
end
properties (Constant)
PluginInterface = audioPluginInterface( ...
'PluginName','Digital Lossy',...
'VendorName', 'AudiiSion Sound Lab.', ...
'VendorVersion', '0.0.1', ...
'UniqueId', 'hiro',...
audioPluginParameter('inputGaindB', ...
'DisplayName','Input Gain', 'Label','dB','Mapping',{'pow', 1/3, -80, 6}, ...
'Layout',[2,1;2,2], 'Style','rotary'), ...
audioPluginParameter('outputGaindB', ...
'DisplayName','Output Gain', 'Label','dB','Mapping',{'pow', 1/3, -80, 6}, ...
'Layout',[2,3;2,4], 'Style','rotary'), ...
audioPluginParameter('LimitdB', ...
'DisplayName','Limiter', 'Label','dB','Mapping',{'pow', 1/3, -80, 6}, ...
'Layout',[2,5;2,6], 'Style','rotary'), ...
audioPluginParameter('Mode','Mapping',{'enum', 'OFF','Cut Lower Power','Cut inaudible', ...
'Quantize inaudible', 'Cut High Frequency','Rotate Frequency','Time Averaging', 'Pitch Shifter'}, ...
'Layout',[1,4;1,6], 'DisplayNameLocation','none'), ...
audioPluginParameter('DeGrade', ...
'DisplayName','DeGrade', 'Label','%', 'Mapping',{'lin', -100, 100}, ...
'Layout',[4,3;4,4], 'Style','rotary'), ...
audioPluginParameter('Bass', ...
'DisplayName','Retrv Bass', 'Label','%', 'Mapping',{'pow', 2, 0, 100}, ...
'Layout',[4,1;4,2], 'Style','rotary'), ...
audioPluginParameter('Treb', ...
'DisplayName','Retrv Treb', 'Label','%', 'Mapping',{'pow', 1/2, 0, 100}, ...
'Layout',[4,5;4,6], 'Style','rotary'), ...
audioPluginGridLayout('RowHeight', [40 70 15 70 15], ...
'ColumnWidth', [repmat([40 40],1,3)], 'Padding', [10 10 10 20]), ...
'BackgroundColor',[1 1 1],'BackgroundImage','DLossy_bk3.jpg' ...
);
end
methods
function plugin = DLossy7 % constructor
plugin@audioPlugin;
Fs = getSampleRate(plugin);
plugin.buff = dsp.AsyncBuffer;
plugin.outbuff = dsp.AsyncBuffer;
plugin.coeffbuff = dsp.AsyncBuffer;
% initialize
write(plugin.buff,[0 0;0 0]);
read(plugin.buff,2);
write(plugin.outbuff,[0 0;0 0]);
read(plugin.outbuff,2);
write(plugin.coeffbuff,[0 0;0 0]);
read(plugin.coeffbuff,2);
% limiter
plugin.dBL = limiter(plugin.LimitdB, SampleRate=Fs);
% center frequencys of each MDCT coefficient
df = Fs/plugin.N2;
plugin.cHz = (0:df:(Fs/2-df))'; % center frequencys of each MDCT coefficient
% hearing threshould
f = plugin.cHz;
plugin.hth = 3.64*(f/1000).^(-0.8) - 6.5*exp(-0.6*(f/1000-3.3).^2) + 10^(-3)*(f/1000).^4;
plugin.hth(1) = 83.2193; % set hth value at 20Hz
minhth = min(plugin.hth);
plugin.hth = plugin.hth - minhth + plugin.minSPL;
plugin.hth = min(plugin.hth, 0);
% critical band
criticalBandCenterF = bark2hz(0.5:25);
plugin.criticalBandCenterFIdx = floor(criticalBandCenterF/df);
criticalBandBandaryF = bark2hz(0:24);
plugin.criticalBandBandaryFIdx = floor(criticalBandBandaryF/df);
% critical band index for each MDCT coefficient
plugin.cBandIdx = max(floor(hz2bark(plugin.cHz)),0);
end
function out = process(plugin,in)
out = zeros(length(in),2);
inGain = 10^(plugin.inputGaindB/20);
outGain = 10^(plugin.outputGaindB/20);
write(plugin.buff,in);
% set ModeN in out of frame loop
% prevent Mode change within frame
switch plugin.Mode
case plugin.ModeC{1}
plugin.ModeN = 1;
case plugin.ModeC{2}
plugin.ModeN = 2;
case plugin.ModeC{3}
plugin.ModeN = 3;
case plugin.ModeC{4}
plugin.ModeN = 4;
case plugin.ModeC{5}
plugin.ModeN = 5;
case plugin.ModeC{6}
plugin.ModeN = 6;
case plugin.ModeC{7}
plugin.ModeN = 7;
otherwise % OFF
plugin.ModeN = 0;
end
if (plugin.ModeN ~= plugin.ModeN_old)
plugin.ModeN_old = plugin.ModeN;
% if you want to clear buffers at changing Mode
% plugin.mem = zeros(plugin.N/2,2);
% reset(plugin.buff)
% reset(plugin.outbuff)
% reset(plugin.coeffbuff)
end
if (plugin.ModeN == 7) % pitch shift Mode
read_N = plugin.N;
mWin = plugin.win;
else
read_N = plugin.N2;
mWin = plugin.win2;
end
MDCT_N = read_N/2;
while plugin.buff.NumUnreadSamples >= MDCT_N
x = read(plugin.buff,read_N,MDCT_N) * inGain;
C = mdct(x,mWin,'PadInput',false);
L = C(:,:,1); R = C(:,:,2);
degL = L; degR = R;
% for Psychoacoustic Mode - set initial value for masking threshold
maskingTh0 = NaN(plugin.N2/2,1);
maskingTh0(end) = plugin.minSPL;
maskingTh0((plugin.criticalBandBandaryFIdx+1),1) = plugin.minSPL;
if (plugin.DeGrade >= 0)
grade = 100 - plugin.DeGrade;
else
grade = abs(plugin.DeGrade);
end
switch plugin.ModeN
case 1
% Cut Lower Power
% cut larger MDCT coefficients
Q = max(grade,1);
Q = log10(Q)/4 + 0.5;
[~,indL] = sort(abs(L),'descend');
[~,indR] = sort(abs(R),'descend');
% Lch
need = 1;
while norm(L(indL(1:need)))/norm(L) < Q
need = need+1;
if (need >= MDCT_N-2); break; end
end
degL = L;
degL(indL(need+1:end)) = 0;
% Rch
need = 1;
while norm(R(indR(1:need)))/norm(R) < Q
need = need+1;
if (need >= MDCT_N-2); break; end
end
degR = R;
degR(indR(need+1:end)) = 0;
case 2
% Cut inaudible
% erase MDCT coefficients below masking curve
dRange = -plugin.minSPL;
splmag = abs(L) / sum(mWin);
cBspl = zeros(25,1);
for k=1:25
cBspl(k) = 20*log10(mean(splmag(plugin.cBandIdx==(k-1))));
end
maskingTh = maskingTh0;
maskingTh((plugin.criticalBandCenterFIdx+1),1) = cBspl - 4;
maskingTh = interp1(find(~isnan(maskingTh)),maskingTh(~isnan(maskingTh)),1:MDCT_N);
maskingCrv = max(maskingTh', plugin.hth);
degL = L;
idx = 20*log10(splmag) < (maskingCrv + (100-grade)*0.75*(dRange/100));
degL(idx) = 0;
splmag = abs(R) / sum(mWin);
cBspl = zeros(25,1);
for k=1:25
cBspl(k) = 20*log10(mean(splmag(plugin.cBandIdx==(k-1))));
end
maskingTh = maskingTh0;
maskingTh((plugin.criticalBandCenterFIdx+1),1) = cBspl - 4;
maskingTh = interp1(find(~isnan(maskingTh)),maskingTh(~isnan(maskingTh)),1:MDCT_N);
maskingCrv = max(maskingTh', plugin.hth);
degR = R;
idx = 20*log10(splmag) < (maskingCrv + (100-grade)*0.75*(dRange/100));
degR(idx) = 0;
case 3
% Quantize inaudible
% quantize MDCT coefficients along with masking curve
dRange = -plugin.minSPL;
splmag = abs(L) / sum(mWin);
cBspl = zeros(25,1);
for k=1:25
cBspl(k) = 20*log10(mean(splmag(plugin.cBandIdx==(k-1))));
end
maskingTh = maskingTh0;
maskingTh((plugin.criticalBandCenterFIdx+1),1) = cBspl - 4;
maskingTh = interp1(find(~isnan(maskingTh)),maskingTh(~isnan(maskingTh)),1:MDCT_N);
maskingCrv = max(maskingTh', plugin.hth);
scale = max(-(maskingCrv + (100-grade)*(dRange/100))/dRange,2^-23)*2^15 ./ abs(L);
degL = round(L .* scale) ./ scale;
splmag = abs(R) / sum(mWin);
cBspl = zeros(25,1);
for k=1:25
cBspl(k) = 20*log10(mean(splmag(plugin.cBandIdx==(k-1))));
end
maskingTh = maskingTh0;
maskingTh((plugin.criticalBandCenterFIdx+1),1) = cBspl - 4;
maskingTh = interp1(find(~isnan(maskingTh)),maskingTh(~isnan(maskingTh)),1:MDCT_N);
maskingCrv = max(maskingTh', plugin.hth);
scale = max(-(maskingCrv + (100-grade)*(dRange/100))/dRange,2^-23)*2^15 ./ abs(R);
degR = round(R .* scale) ./ scale;
case 4
% Cut High Frequency
% cut High frequency
sN = max(round(MDCT_N * ((10^(grade/100)-1)/9)),1);
degL = zeros(size(degL));
degL(1:sN) = L(1:sN);
degR = zeros(size(degR));
degR(1:sN) = R(1:sN);
case 5
% Rotate Frequency
% rotate MDCT coefficients
sN = min(round(MDCT_N * (1-grade/100)), MDCT_N-1);
degL = circshift(L,sN);
degR = circshift(R,sN);
case 6
% Time Averaging
% take moving average of MDCT coefficients in time domain
accN = max(round((100 - grade)/2), 1);
st = [L(:,1) R(:,1)]; % define size
write(plugin.coeffbuff,st);
while plugin.coeffbuff.NumUnreadSamples >= (MDCT_N * accN)
x = read(plugin.coeffbuff, MDCT_N * accN, MDCT_N * (accN-1));
c = reshape(x,MDCT_N,accN,2);
mc = squeeze(mean(c,2));
degL = mc(1:size(degL,1),1); % define size
degR = mc(1:size(degR,1),2); % define size
end
case 7
% Pitch Shifter
% shift pitch
st1 = 1; end1 = MDCT_N/2; n1 = MDCT_N/2;
st2 = 1;
end2 = max(round((plugin.DeGrade + 100)/200 * MDCT_N), 2);
n2 = end2 - st2 + 1;
rate = n1/n2;
range1 = st1:end1;
range1s = st1:rate:end1;
degL = zeros(size(degL));
tmp = interp1(range1,L(range1),range1s);
range2 = st2:(st2 + length(tmp) - 1);
degL(range2) = tmp;
degR = zeros(size(degR));
tmp = interp1(range1,R(range1),range1s);
degR(range2) = tmp;
otherwise
% OFF
% do nothing
% inGain, outGain only
end
if ((plugin.DeGrade < 0) && (plugin.ModeN < 7))
degL = L - degL; degR = R - degR; % reverse polarity
end
% recall low frequency
if plugin.Bass ~= 0
bN = max(round(MDCT_N * plugin.Bass/100), 1);
idx = 1:bN;
degL(idx) = L(idx);
degR(idx) = R(idx);
end
% recall High frequency
if plugin.Treb ~= 0
tN = min(round(MDCT_N * plugin.Treb/100), MDCT_N - 1);
idx = (MDCT_N - tN):MDCT_N;
degL(idx) = L(idx);
degR(idx) = R(idx);
end
if (plugin.ModeN == 0) % OFF
% do nothing, inGain, outGain only
else
L = degL; R = degR;
C = cat(3,L,R);
end
y = zeros(plugin.N,2);
y(1:read_N,:) = imdct(C,mWin,'PadInput',false);
write(plugin.outbuff,y(1:MDCT_N,:)+plugin.mem(1:MDCT_N,:));
plugin.mem(1:MDCT_N,:) = y(MDCT_N+1:read_N,:);
end
out = read(plugin.outbuff,length(in)) * outGain;
if (plugin.ModeN ~= 0)
plugin.dBL.Threshold = plugin.LimitdB;
out = plugin.dBL(out);
end
end
function reset(plugin)
plugin.dBL.SampleRate = getSampleRate(plugin);
reset(plugin.dBL);
end
end
end※GUI の各 'Mode' は文字数が違います。MATLAB 動作では特に問題ありませんが、VST のようなコード生成でこのようにしたい場合、メモリサイズが異なるので set function が置けなかったり文字列比較等ができない制限があるので気を付けてください。
MDCT長がフレームループ内で変わってしまうのを避けるため、フレームループ前で一旦数字に置き換え、それにより実際の処理を切り替えています。(switch 文は使えます)
前回の Mode と比較し、変わったときだけバッファクリアを入れていましたが、ない方が Mode を変えたときでも滑らかに繋がるのでコメントアウトしてあります。必要であれば入れてください。
あとがき
プラグイン自体は簡単に作れましたが、この説明を書くのにかな~り苦労しました。(^_^;)
未だに使い道はピンときませんが、面白いといえば面白い、かな?w
JUCE には、MDCT はないようですね。
むか~し、DSP のアセンブラで組んだ記憶はありますが。
最初に「半世紀以上前から分かっていることもたくさんあります」とは書きましたが、聴覚心理特性も結局、「実験したらこうだった」というもので、HRTF 同様まだ全て解明されたわけではありません。
近年、聴覚は受動的に音を聴くだけではなく、音の状態によってダイナミックに特性を変えるアクティブセンサーであるということも分かってきています。
聴覚の正確なモデリングはまだまだ難しいかもしれませんね。
結局、Mode2-3 ('Cut inaudible', 'Quantize inaudible')しか「聴覚心理特性」を利用しなかったので、最初の趣旨からかなりズレてしまいましたが・・。
MDC(DCT)に関しては、色々と複雑なので説明はかなり省略しています。
その他、特に歴史的背景等は記憶違いもあるかもしれませんので、間違い等あれば教えてください。(¬_¬)
タイトル画像モデル:美香