
DnoteLR/LR+ 開発秘話

まえがき
特許経過情報見てみたら、カシオさんに権利譲渡されていたようで・・。
私が最初に買った電卓はFX-602Pでした。(u_u)
せっかくなので(?)開発秘話的なモノでも書いてみようかと。
権利的なこともあるので、技術的内容については、論文・特許等で公開済みのもののみになります。
経緯
私と落合氏は2020年6月いっぱいで退社して DnoteLR/LR+ から離れることになり、2020年10月に AudiiSion Sound Lab.を共同創業しました。
藤本健のDigital Audio Laboratory 「ヘッドフォンで立体音響を生み出す新技術「AudiiSion EP」とは?」(AV Watch)
最新サンプル音源
それまでの経緯をざっくり言うと、
2019年、ハードウェア事業での資金調達に頓挫して大規模リストラ、約1年の猶予期限付きで DnoteLR/LR+ の IP ライセンス販売に専念して事業継続することに。
デモの評判はすこぶる良く、音響学会でのポスター発表でも、予定の2時間を過ぎて他は全て撤収された後30分以上来場者が途絶えず、
「空間音響再現」がテーマだった AES International での展示でも、
"Congratulations!" と握手されたり、一回見た人が、"This one! This one!" と言いながら他の人を連れてきてくれたり。
年齢・性別問わず「今すぐ買いたい!」という声も多く、メーカーさんからの引き合い自体もかなりあったのですが、いざお金の話になると
「もう製品の値段は決まってるのでコストは増やせない」
というところが多く、
「この機能を入れれば○円高くても売れるのでは?」
という考えは通じませんでした。
この辺りは、会社全体としての営業・プロデュース力不足、開発も私一人でやれることが限られていた、というのもあったかと思います。
大口が決まりそうではあったのですが、結局、時間切れとなりました。
今回はその辺の反省は置いておいて・・、
手前味噌にはなりますが、個人的にこのまま消え去るには惜しい技術だと思ってはいるので、せめてもの供養にメモを残しておこうと思った次第です。
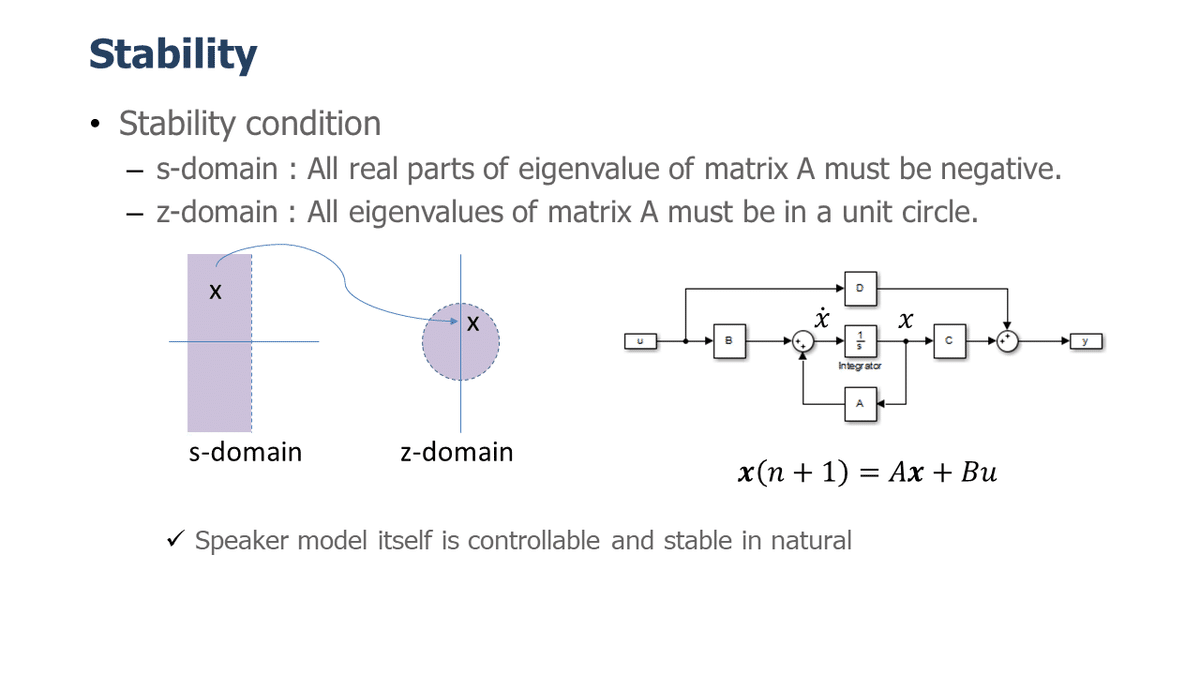
DnoteLR - 物理パラメータUIオーディオイコライザー
スピーカーの状態空間モデルと現代制御理論を用いて、ボイスコイル電流 ・ ダイアフラム位置 ・ ダイアフラム速度を推定し、その内部状態を考慮したフィードフォワード制御を行うことにより、スピーカーのインピーダンス、インダクタンス、フォースファクター、スティフネス、機械抵抗、可動部質量、キャビネット容量等を信号処理により仮想的にリアルタイムで変更できるシステムです。各パラメータは独立して変更可能で、物理的には実現困難な特性も容易かつ安定に作り出すことができます。



(参考記事)
藤本健のDigital Audio Laboratory 「100万円のスピーカーの音を安価に実現!? Dnote-LR+が見せる音の新たな未来」(AV Watch)
DnoteLR+ - 小型ステレオスピーカー一つで空間的な広がりを再現
DnoteLRのコア技術であるDTSCの「逆フィルターなしに安定した逆特性が実現できる」性質を「スピーカーの振動板の動きまで含めた高精度(高音質)なクロストークキャンセラ-」として応用。数cm~間隔のステレオスピーカー一つで広い音像空間が再現できます。HRTF処理、リバーブ等付加的なエフェクトが不要なため、音質変化や「センター抜け」度合いが小さく、空間的な広がり・明確な定位・高い解像度を同時に実現できます。通常のステレオソースの音像空間を大きく広げることができ、イマーシブソースに対してはさらに広い音像空間が再現されます。

(参考記事)
藤本健のDigital Audio Laboratory 「オーディオの革命!? 小型スピーカーで広い音場の独自技術「Dnote-LR+」を体験」(AV Watch)
「LR」はステレオのLRと、「(これまで不可能だった)臨場感(Live)と解像感(Resolution)の両立」をもじっています。
ロゴデザイン上の理由等により、途中で Dnote-LR/LR+ → DnoteLR/LR+ というハイフンを取った表記に変わりました。
(ロゴを作る前はそれぞれ、"DTSC"、"3D Sound"などと呼んでいました)
検索上の問題があるので「早く正式名称を決めましょう!」と進言していたのですが、あまり気にされなかったようです。(;¬_¬)
「簡単にできると思うんだけどね」
DTSCの大元は、マルチコイル・フルデジタルスピーカー「Dnote」の発案者でもある 法政大学教授 安田先生のアイデア、
「理論的にはこれでスピーカーの特性を他のスピーカーの特性に変えることができるはず」
という、現代制御理論とスピーカーの物理モデルを用いた Simulink の連続領域(アナログ)モデルでした。
速度のみスカラー制御
ただしこの時点では、
-音量が小さく、ゲインを上げるとすぐ発散する
-低音再現が全くできない
という大きな問題がありました。
入社してすぐこれを受け継ぎ、スピーカーモデルの最適な離散化、多次元ゲインベクトル化、スピーカーモデルごとの安定動作のためのフィードバックゲインベクトル(極)自動推定アルゴリズムの開発、10^±7オーダーという非常に広い信号ダイナミックレンジを持つこのシステムの、演算精度を保ったままの演算量削減、固定小数点演算対応などを行い、デジタル領域で、全オーディオ帯域での安定動作と高音質化を実現したのが DnoteLR(技術名:DTSC)です。
私はデジタルオーディオ信号処理の経験は長いですが、現代制御どころか古典制御も実経験はなく、数百の英語論文を読みあさり毎日数学と格闘、数ヶ月間何の進展もなく「そろそろクビかな~?」と思いながらの開発、とても「簡単」ではありませんでしたが・・。




DTSC は Digital Thiele-Small Correction の略で、スピーカーの特性を表す共通パラメーターとして使われている「T/Sパラメータ」を補正する技術という意味です。
T/Sパラメータの「T/S」は、1960年~70年初頭に掛けてスピーカーの解析技術(等価回路)を確立した ThieleさんとSmallさんのお名前から取られています。
自動極配置
デジタル制御を行うにはまず、スピーカーの微分方程式モデルを含むフィードバックシステム全体を離散化しなければならないわけですが、そこで必要になるのが「極(フィードバック・ゲインベクトル)」の「配置」です。
それ自体はアナログフィルターのデジタル化とほぼ同じ話なので詳細は省きますが、教科書や論文をいくら見ても、「まず適当なところに極を置き、そこから移動させて調整を繰り返す」としか書かれていませんでした。これではスピーカー毎にかなり手間が掛かりますし、手動で調整したのでは周波数特性をフラットにすることなど到底できません。また。安定動作のためには通常、制御帯域の4~8倍程度のオーバーサンプリングが必要とされており、それでは演算量が膨大になります。Hi-Fiオーディオですから、24ビット程度以上のビット解像度も必要で、ICの規模もかなり大きくなってしまいます。


( MATLAB スクリプト )
そこでDTSCのある特性に注目し、最急降下法を応用した、オーバーサンプリングなしに全オーディオ帯域で周波数特性(ほぼ)フラットで安定動作可能な自動極ベクトル配置アルゴリズムを開発・アプリ化しました。
実際には、これができた時点でDTSC実用化の目処が立ったと言えます。
ダイナミックレンジスケーリング
信号ダイナミックレンジが極めて広いため、浮動小数点コプロセッサを使う予定でIC開発は進んでいました。しかし、詳細は言えませんがESができあった時点で、某メーカーから提供された浮動小数点コプロセッサが「(なぜか)仕様を大きく下回る性能」であることが判明!しかも、メインDSPには固定小数点演算時に演算精度を高めるためのフリーオプションがあったのですが、コプロを使う前提だったのでそれもOFF(予算的に作り直し不可)、かなり詰んだ状態でした。
しかたなく急遽アルゴリズムから見直し、プリ処理だけで演算精度を落とさずに固定小数点DSPにインプリすることが可能となりました。
こうしてでき上がったのが、DTSC内蔵デジタルスピーカーモジュール「DSM1338」です。
当初の目的は違っていた
安田先生のモデルも私のデジタル領域での安定動作化・高音質化等も、実は『(より複雑な)他の目的』で開発していました。ところがラボで Simulinkモデルでのリアルタイム動作が実現した段階で、
「デモは可能だが(モデル精度、時間変動等の問題で)実用化は困難」
「測定数値以外で効果が見えにくい(普通の音楽で聴いても差がほとんど分からない)」
という(当初から予想していた通りの)結果が明白になりました。(開発開始から8ヶ月経過)
安田先生曰く、
「やはりそうか・・ この分野は博士達の屍類類の・・」
(「簡単にできると思う」って言ったじゃん・・)(;¬_¬)
そこで 安田先生との朝の雑談の中で「さっさとやめて他のことやりましょうよ!」と相談、「本来の目的である『他の目的』が実現したら、その先にこういうこともできるね」程度であった、「スピーカーの特性を他のスピーカーの特性に変える」方が良いのではないか?という話になりました。
その実現に必要は技術は『他の目的』のために全て開発済みであったため、午後のミーティングを挟んで数時間後には、プロトタイプのGUIアプリ(MATLABアプリ)が完成しました。
実際に動かしてみると、「ほんとうに理論通りに音が変わる・・」というのが先生と私の共通の感想でした。
理論通りとはいえ、物理的な変更を加えたのと同じような音質変化が信号処理だけで実際に行えているというのが、開発した本人達にも感覚的に信じられなかったのです。
これがDnoteLR(DTSC)の誕生です。
のちにPA界の御大の方に試作品を持って行ったときも、無言で30分くらいいじり倒し、
「面白い!!今まで『これをこう変えると(理論的には)こうなる』と説明していた通りの音がする!」
とのお言葉でした。
模式図だけ見ると現代制御理論の教科書に載っているそのままに見えますが、(権利の関係で詳細は述べられませんが)実はちょっと「特殊な構造」になっています。
これまでのスピーカー設計では当然物理的な変更が必要で複数のパラメータが同時に変わってしまうこともあり、スピーカーの設計は何度もの作り直し・調整が必要となるわけですが、それは手間も時間も費用も掛かります。DTSCではそれらをリアルタイムに、独立して変えることができます。わざと「低音は出るけど締まりのない(やればできる子的な)」スピーカーを作っておいて、DTSC で「締まりのある低音」にコントロールすることも可能かと思われます。
Webで公開されている海外有名メーカーのT/Sパラメータを用いると、「それっぽい」音が再現でき、左右でドライバも箱の大きさも違う別のスピーカーを使っても、DTSCで同じスピーカーモデルをターゲットモデルにすると「普通」にステレオシステムとして聴くことができました。

(シミュレーション)
固定の特性であればそれ専用のフィルターを作ればできないこともないですが、物理的なパラメーターを入力として自由に、リアルタイムに、しかも他の方法に比べ軽い処理でできるというのがポイントです。
スピーカーモデルの離散化までは何十次ものテーラー展開や極設定のイタレーションが必要ですが、一度行ってしまえば軽い行列演算のみで済みます。
グライコ等で同じことをしようとすると、数千~数万のバンドと、それを適切に操作できる技術が必要になります。それに、スピーカーの特性は経年変化も大きいですからね。
理論的には明快で論文でも公開していたので、打合せを行ったあるメーカーさんでは、
「こういうのって『アヤシイ』のが多いんですが、理論がちゃんと公開されてるのって珍しいですね」
と言われたりもしました。w
その後一年半ほどかけ、アプリケーションエンジニアであった落合氏がチューニング、様々なフィードバックを受け完成度を上げていきました。
理論は単純明快ですが、実際はノウハウの塊なのです。
またDTSCは、物理モデル(微分方程式による状態空間モデル)さえ定義できれば、通常高精度に求めることが困難な「逆関数」を求めなくても安定した逆特性が実現できる、という性質を持ち合わせていました。
ちなみに入社時、社内にはサポート切れの古いMATLABが数本あっただけでした。
Similinkはその後かなりアップデートされていたため、開発の目処が付いた段階でトライアルを申し込み、リアルタイム動作するGUI付きSimulinkモデルを開発しました。それを「経費に非常にシビアな」イギリス人社長に見せたところ気に入ったようで、「もうちょっとでトライアルライセンスが切れます」と説明したところ、「なにやってるんだ!?早く買え!」となり、ついでに数人分に盛った予算申請がすんなり通りました。同僚からは、「えっ、通ったんですか!?」とか言われましたが・・。
その後のサポート更新時も、他の予算申請は平気で2週間とか放って置かれてたのに、MATLABは申請書を見せるとその場でサインをもらえました。(u_u)
DnoteLR まとめ
状態空間モデルと現代制御理論を用いた、従来とは全く異なるUIのオーディオイコライザー
毎サンプル(一秒間に4万回以上)振動板の位置や速度を推定し振動板の動きをリアルタイムに制御
スピーカーのインピーダンス、インダクタンス、フォースファクター、スティフネス、機械抵抗、可動部質量、キャビネット容量等を仮想的に、それぞれ独立に変更可能(物理的手法では不可能)
物理的に作り直すことなく 別のスピーカーであるかのような特性にリアルタイムで変更可能
不要な共鳴を抑制、歪み感の低減、定位感の向上等が可能
ターゲットモデルを変更することにより、振動板の動く範囲等を制御可能
振動板の位置により、リアルタイムにスピーカーモデルを変えて振動板の動きに制限を掛けることも可能(スピーカー保護)
サブバンドフィルターが不要なマルチバンドコンプレッサーとしても動作
スピーカーのバラツキ、メーカー違い、L/Rスペースアンバランスの調整にも有効
演算量が少ない
浮動小数点DSPで10MIPS/2ch以下、固定小数点動作可能(モデル離散化部除く)
次のテーマへ
DTSCのブラッシュアップとオプション機能のアルゴリズム開発~各種ユーティリティアプリ開発~DSP実装までが終わり、開発部でのシステムIC化は1年前後掛かるため、開発部へのサポート以外は「何をやっても自由」な状況でした。私だけ「半導体屋」ではないのでミーティングすらなし。
DTSCの「逆関数を求めなくても安定した逆特性が実現できる」という特徴は他の応用先があるはず、ということも頭の片隅に残しつつ、MATLABで色々遊びながら次の研究テーマを探していました。
カクテルパーティー効果
いくつか試している中でフト思い付いたのが、昔から興味はあったものの手を付けたことはなかった「空間音響再現」≓「カクテルパーティー効果を録音された音で再現する」ということでした。
「カクテルパーティー効果」とは、パーティー会場とか騒がしい場所でも、例えば自分の名前が離れた場所の会話で出てくるとそっちの会話が聞こえるようになったりするように、意識を集中させると特定の会話が聞き取れるようになる人間の能力を指します。しかし一旦それを普通に録音してしまうと、カクテルパーティー効果が発揮できなくなります。単に音ではなく、「音響空間」を記録・再現する必要があるのです。
ある程度はバイノーラル録音・再生(イヤホンを使用)で実現されていましたが、個人的には、効果が不十分・不自然で、「スピーカー再生の方が自然ではないか?」と(その時点ではなんとなく)思っていました。

トランスオーラルシステム
イヤホンを用いるバイノーラルシステムに対し、スピーカーを用いる立体音響再現をトランスオーラルシステムと呼びます。

目の前についたてを置くと音像が広がるなど、ステレオスピーカーのLR間クロストークをキャンセルすれば音像が広がることは古くから知られており、1960年代初頭にはすでに世界中で様々な試みがなされてきました。(日本では長岡鉄男氏のマトリックススピーカー等)
しかし、もちろんついたては邪魔ですし、当時のアナログ技術では高精度なクロストークキャンセラーの実現は不可能で、効果的にも音質的にも実用的とは言えませんでした。
1970年代になると、HRTF(頭部伝達関数)と言う考え方が一般化、トランスオーラルシステムでは(実は)再生時のHRTFキャンセルが必要であり、それを行うことにより高精度に実現できるという、CTC(CrossTalk Cancellation)フィルターを用いたシステムが発表され、トランスオーラルシステムの原理は理論的には確立します。
これまで高精度なトランスオーラルシステムが実現できなかったのは、HRTFのキャンセルを行っていなかったから、という考え方です。
CTCは論文等では枯れた技術として紹介されることも多く、トランスオーラルシステムは「理論的には実現可能」とされていました。
しかし実際はHRTFの特性から、
聴く人個人のHRTFを使う必要がある
ピンポイントの視聴位置でしか効果がでない
スピーカーと耳との相対位置が変わるとHRTFを変える必要がある
特性が複雑なHRTFの逆関数は近似解しか求まらず、全オーディオ帯域に渡る十分なキャンセル性能が実現できない(特に低域)
>原理的に2つのスピーカーではフィルター長が無限となる
>特定の周波数で非常に高いゲインが必要となり、実際はゲイン(=効果)を下げざるを得ない
>スピーカー間隔を非常に狭くすればそれが低域にシフトするが低域が再現できない(ステレオダイポール)調整が難しい
といった問題があり、
「(原理的には完成しているはずの)トランスオーラルシステムは実際にはできない」と断言する研究者も一方では存在しました。
そのため、ヘッドトラッキングの併用、十分ではない効果の補正のためにリバーブエフェクトの追加、帯域別に複数のスピーカーを用いる等、より複雑な方法が模索されていました。

(参考)
MATLABでHRTF~頭部伝達関数とは?~聴覚の仕組みは解明されていない~
単眼立体視
話は変わりますが、「単眼立体視」というのがあります。
平面ディスプレイで立体視を行うには、視差のある2枚の画像を用いることが一般的です。
これは、視差が立体視の「強い手掛かり」だからです。
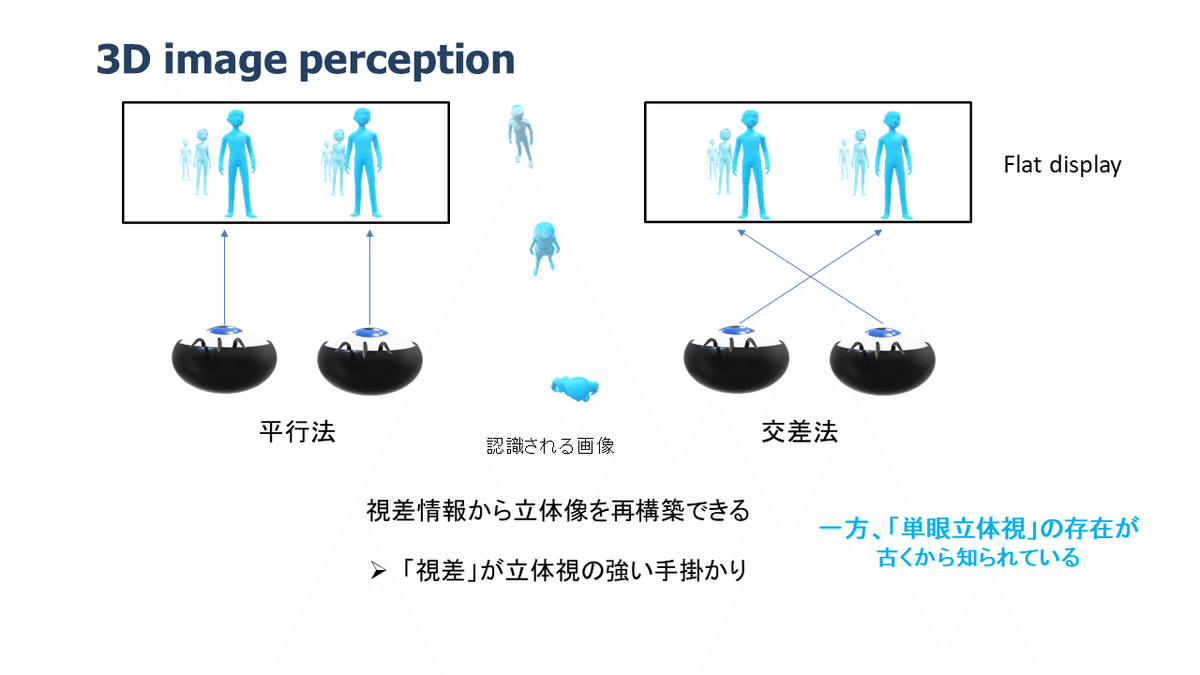

普通の平面ディスプレイが立体的に見えないのは、「視差がない」ので平面であることを認識してしまうことも原因の一つです。
一方、写真のポジフィルム等を「片目で見ると立体的に見える」ことが古くから知られていました。
これは、片目を閉じると視差情報がなくなるので、他の情報(重なり、相対的大きさ、かすみ、ぼけ等)を使って過去の経験から立体像を作り上げることができるからです。
現在なら、スマホ等で高品質な奥行き感のある写真を片目で見れば、立体的に見えてくることを実感できると思います。
つまり視差は立体視の強力ではあるが唯一の手掛かりではなく、この場合は逆に立体認識の「阻害要因」になっているということです。
(参考)
単眼立体視の話~脳は複数の情報から使えるものを使って認識する
音への応用
これを音に応用できないか?、と考えたのが DnoteLR+ の始まりです。
DnoteLR+は、単眼立体視の原理を元に
音は脳で認識されるのに、音像から耳までの物理特性であるHRTFだけを考えるのは不十分ではないか?
人の脳内認識の仕組みから考えて、むしろHRTFのキャンセルは必ずしも必要ないのではないか?
(人は複数の情報から使えるものを使う)
という発想から来ています。
単眼立体視で起きてることと同じように、音像認識の「阻害要因」だけをキャンセルし、あとは人間の音像認識能力にゆだねた方が、より自然な立体音響空間認識が行えるのではないか、という考えです。

但し、「単眼立体視」を音で実現するには、「単眼視」と同等のかなり高精度なクロストークキャンセル性能が必要であろうことは、それまでのクロストークキャンセラーでは十分な音像の広がりが実現できていないことからも予測できました。(片目を閉じるように、片耳の音だけ完全にシャットアウトすることは通常できません)
そこで思い付いたのが、
「DTSCの『逆関数を求めなくても安定な逆特性を実現できる』という特性を利用すれば、高精度なクロストークキャンセラーが実現できるのではないか?」ということです。
DTSCを利用して「スピーカーの振動板の動きまで含めた高精度(高音質)なキャンセラ-」として動作させれば、クロストークが存在する実際のステレオスピーカーを「クロストークが存在しない仮想的なスピーカー」として作用させることができ、HRTFのキャンセルを行わなくても高精度な立体音像が認識できるのではないか?、と考えたのです。
基本的にはDTSCにディレイとゲインを追加すれば実現できるため、
(「DTSCが時間方向にも有効だろうか?」という疑問を持ちつつも)
夜に家で思い付いて翌朝会社ですぐリアルタイム動作するMATLABアプリを作り、スピーカー間隔15cmほどのステレオスピーカー(ANKER SOUNDCORE2 だったか社内にあったデジタルスピーカーだったか・・?)で再生、
「広がる!」
隣の人に聞かせてみても、
「広がる!」


DnoteLR+のプロトタイプアプリも、MATLABを用いDTSC同様数時間で完成しました。
但しこれもまた落合氏と、1~2年掛けて完成度を上げていくことになります。
当初よりも、広がり、定位感、音質ともに大きく向上しました。
(予想に反し)単に水平方向に広がるだけでなく、「ちゃんと」調整した試聴室で聴くようにスピーカーの存在感が消え、目の前の空間全体に広がりのある音像(場合によっては後ろも)が再現できました。
高精度に個人差なくクロストークを消すことは過去数十年間にわたる課題であり、それをスピーカーの状態空間モデルと現代制御理論を用いて解決したのが DnoteLR+ です。
DnoteLR+ まとめ
幅10cm前後のステレオスピーカー1組で広い音像空間・明確な定位・高い解像度を同時に実現
効果の個人差が小さい
スイートスポットが広い
音質変化やセンター抜け度合いが小さい
演算量が少ない(浮動小数点DSPで10MIPS/2ch程度、固定小数点動作可能)
ほとんどのステレオソースに対して効果的
イマーシブオーディオソースに対してはさらに立体的な音像空間が得られる(フロント2ch信号から)
(Dolby Atmos®、DTS:XTM、Auro-3D®、dearVR、NetEnt 3D等)新たなエンコード/オーサリング不要
小さな音量でも臨場感が得られる
解像度・定位分離がよく聞きとりやすい
二組のステレオスピーカー(4つのスピーカー)を用いればその4点を含むさらに広い空間を形成できる(TVの上下など)
外部発表関連ヒストリー
最後に、外部発表関連の履歴を載せておきます。
DnoteLR
2016/6 特許国際出願 → 2021/5 登録
2016/9 FIT出展
2017/1 CES出展(プライベートルーム)
2017/7 SIGMUSポスター発表
岩村 宏, 安田 彰, 岡村 淳一, 状態空間モデルと現代制御理論を用いた可変電気・機械特性スピーカー - The Dtsc ® (Digital Thiele-Small Correction) -, 研究報告音楽情報科学(MUS), 2017-MUS-115(24), 1-6 (2017-06-10)
DnoteLR+
2018/1 特許国際出願 → 国際調査報告 「全クレーム類似文献なし(特許性あり)」
2018/1 CES出展(プライベートルーム)
2018/3 電子情報通信学会総合大会出展
2018/8 AES International CONFERENCE ON SPATIAL REPRODUCTION 出展
2019/3 日本音響学会ポスター発表
岩村 宏, 安田 彰, 岡村 淳一, スピーカーの状態空間モデルと現代制御理論を用いた空間音響再現, 2-Q-16, pp.355-358, 日本音響学会2019年春季研究発表会論文集, 2019
2019/3 電子情報通信学会総合大会出展
2019/3 JAPAN INNOVATION DAY 出展
2019/5 MATLAB EXPO ポスター発表 → ユーザー投票2位
2019/7 1ビット研究会講演
2019/11 ET & IoT 展出展/スタートアップセッション技術講演
Web記事
藤本健のDigital Audio Laboratory 「オーディオの革命!? 小型スピーカーで広い音場の独自技術「Dnote-LR+」を体験」 2019年9月30日(AV Watch)
藤本健のDigital Audio Laboratory 「100万円のスピーカーの音を安価に実現!? Dnote-LR+が見せる音の新たな未来」 2019年10月7日(AV Watch)
プレイバック2019 「超リアルな立体サウンド「Dnote-LR+」に一番の衝撃を受けた」 2019年12月30日(AV Watch)
藤本健のDigital Audio Laboratory 不思議なUSBアクセサリからWindows音悪い問題まで。20年間の思い出ベスト5 2021年2月8日(AV Watch)
麻倉怜士の大閻魔帳 「サウンドバーで簡単イマーシブ! ~驚異の広がりDnote-LR+」 2020年3月26日(AV Watch)
なむ (-人-)