
保守・管理しやすいDB管理階層について考えてみる

テーブル管理構成の課題感
テーブルを作る際どこまでデータの整備をすればいいか責任範囲が各チームで曖昧
各チームのテーブル管理、中間テーブル作成のルールが曖昧
テーブルごとにルールが異なり分かりづらい
テーブル間のTransform処理の連携がうまくいかない
カラム変更
同期ずれ
テーブル管理階層の提案
DBTのディレクトリ構成をもとにデータベースのファイル管理をどうするべきかの構想。Snowfake×DBTを使っていることを前提としている。
参考
・DBT公式:How we structure our dbt projects
解説サイト
・Qiita:【データ基盤構築/dbt】modelディレクトリの構成のベストプラクティス
・DeveloperIO: dbtプロジェクト構築に関する ベストプラクティス #1「概要」 #dbt
階層構造イメージ

DBTファイル階層構造の実例:公式ページより取得
「models」ファイルの中身が今回見ていく内容。
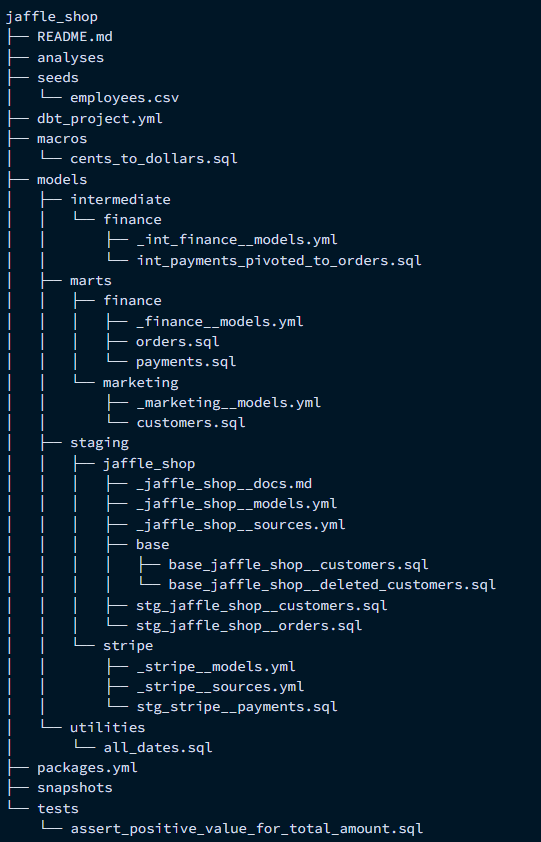
Raw
S3に格納されていたデータをそのままSnowflakeに入れるだけの層。Snowpipeを使うことでS3に更新が入った場合にすぐにRaw層にデータ反映ができる。
加工テーブルではないため、DBTベストプラクティスにはなかったが取得してきたそのままを格納する場所として定義。
Staging
簡単なデータの整理を行う。
データ取得元の変更をこの層で吸収することが目的。intermediate, mart層では取得元のカラム名変更、アップデートなど気にせずにモデル構築できるようにするのが理想。
処理例)
正規化
リネーム
カラム順の整理(左からよく使う、粒度大きいカラム)
型変換
基本的な計算(セントからドルに単位を変換する。など)
カテゴライズ(case文で、値をグループ分けする。など)
データの保持方法
大した処理を入れないかつRaw層とほぼ同じデータになるためテーブルとしてではなくViewとしてデータ保持した方がいい。
Viewであればデータ取得エラーや修正が入った場合でも後続の呼び出し毎に最新のデータを提供できる。データ量が多いテーブルに対してはDBTインクリメンタルモデルなどを使い差分更新をするなど工夫は必要。
サブディレクトリ
intermediate, marts層と異なり、データ取得元別にファイルを分ける。
ファイル名ルール
stg_[source]__[entity]s.sql
正規化を行う階層なので同じソースから複数テーブルに分割することもある。その際にentity(ファイル名)とともにソース名がないと何を正規化したものかわかりづらくなってしまう。
Intermediate
この層でTransform(結合、変換ロジック)をできる限り吸収する。
Marts層はユーザー要望に応えるため一気通貫したロジックが保てなくなることがある。
そのためInt層で明確かつ具体的なロジック全て適応し、Marts層はユーザー要望による修正ロジックのみを適応するというような区別。
サブディレクトリ
ビジネス領域別に区別
Marts
データマートを生成するための層。
実際のテーブルを作成。
完成物がユーザーに見えるためユーザー基準で各ルールを徹底。
サブディレクトリ
ビジネス領域別に区別
ファイル名ルール
ユーザーにとってわかりやすいファイル名(モデル、テーブル名)にする。
IntersectionMarts
別ドメインデータとの結合処理などを行う層
各ドメイン(部署)ごとにDBを用意しMarts層までのデータ管理をしてもらう。
Marts2層にて部署横断のテーブルを作る想定。
感想
DBTベストプラクティスは全部署横断でデータ管理をしている組織がある前提のファイル構成になっている印象を受けた。そのため上記では「IntersectionMarts」層を追記している。
全データを1部署で管理すると負荷高くなってしまうためドメインデータ(各部署で使っているツールや作業から発生するデータ)は部署ごとに責任もって管理してもらった方がいいと私は思っている。(データ入力する部署がデータ管理の責任を持たないとPDCAが回せないため。)
ただしデータ管理をする専門知識を持った人材を各部署に常時配置できるようなリソースが必要になる。
今回はデータベースの管理構造に注目して考えてみた。
しかしデータベースの管理をしているともう少し粒度小さい問題としてTransform処理が上手くいかない、管理できないという課題感を感じることもある。
ここについてもDBTやSnowflakeの機能で使えそうな機能があるので調査してみたい
Transform(矢印部分)処理の課題
同期ずれが起きる
どんな変更処理が入っているか不明
各カラムの定義が不明(特にビジネス利用用にロジック入っている場合)
データ品質としてどのカラムをどこまでチェックしているのか不明
過去のデータの修正、変更の意思決定が見えない
解決策
動的テーブル、DBTインクリメンタルモデル、DBTデータリネージなどの可視化機能