スプレッドシートでの集合計算(和集合、積集合)

まとめ背景
Googleフォームなどで複数回答ありの選択肢のアンケートを取ったとき
回答結果を分析するために集合計算を使いたいケースがでてきた。
回答結果に対してxxxの当てはまる率は何%なのか?
逆に当てはまらないもののうち回答が多い選択肢は何なのか?
スプレッドシートには直接集合計算ができるような機能はなかったので、基本的な集合計算の実装方法をまとめておき用途に合わせて使い分けるようにナレッジをまとめておく。
各ケースに一致する「要素数の集計」「リストの作成」をアウトプットとする。
Output
詳細は以降で説明

本記事では集合関数の計算の一例が紹介されている。
他にもSUMPRODUCT、Query関数、ISNA、MATCHなど様々な関数を使って同じことが実現できる。
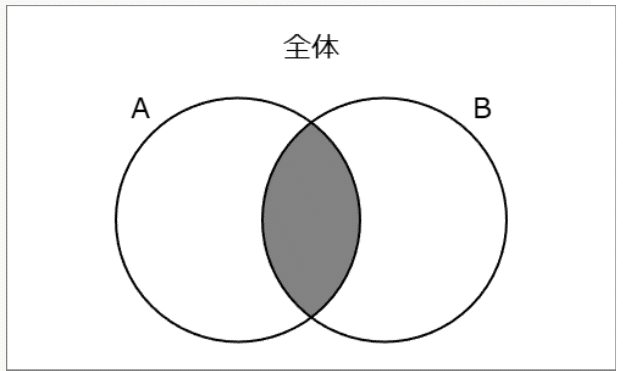
A∩B:共通部分(積集合)

FILTER(split(集合B,","),COUNTIF(split(集合A,","),split(集合B,","))>0)関数の詳細説明
COUNTIF(split(集合A,","), split(集合B,",")):
集合Bを分割した配列の各要素について、集合Aを分割した配列内にその要素が存在するかどうかをカウントします。
具体的には、集合Bの各要素を検索キーとして、集合Aの配列内での出現回数を数えます。
結果として、集合Bの要素数と同じ長さの数値配列が返されます。この配列の各要素は、対応する集合Bの要素が集合Aに現れる回数を示します。
COUNTIF(split(集合A,","),split(集合B,","))>0:
COUNTIF関数の結果の配列の各要素が0より大きいかどうかを評価します。
つまり、集合Bの各要素が集合Aに少なくとも1回出現するかどうかを評価します。
結果として、TRUE または FALSE のブール値の配列が返されます。
FILTER(split(集合B,","),COUNTIF(split(集合A,","),split(集合B,","))>0):
FILTER関数は、2番目の引数で指定された条件を満たす要素を、1番目の引数で指定された範囲から抽出します。
この場合、集合Bを分割した配列から、COUNTIF関数の結果が0より大きい(つまり、集合Aにも存在する)要素のみを抽出します。
言い換えると、集合Aと集合Bの両方に存在する要素(積集合)を抽出します。
A∪B:どちらか一方にしか所属しない(和集合)


transpose(UNIQUE(transpose(SPLIT(集合A&","&集合B,","))))関数詳細説明
集合A,集合Bを文字結合する
SPLIT関数でカンマ区切りに分割
Unique関数で重複を削除
※横向き配列だとUnque関数の重複削除がうまく動かないためtransposeで配列の向きを変更している
-A∩B:Bのみに属するもの(集合の引き算をどうするか)


FILTER(split(集合B,","), COUNTIF(split(集合A,","),split(集合B,","))<=0)関数の詳細説明
A∩Bとほぼ同じ
Countifの条件が「>0」から「≤0」に変更されている。
上記のように条件を変更することで集合Bの各要素に対して集合Aと一致しない場合に「True」を格納している。
Fileter関数では「True」と判別された要素のみに絞り込まれるため結果として集合Aに存在しない集合Bの要素だけが表示される。
感想
配列計算など具体的にイメージしながら関数を書いていけるので、1次元配列までであればスプレッドシートで手を動かしながら分析すると勉強になりそうだと感じた。
より大規模な要素、データを分析するとなるとちゃんと配列計算やPythonなど勉強した方がよさそう。
スプレッドシートの配列を扱える関数(filter, countif)について
一般的な使い方ではないためWebで検索しても挙動などが理解できなかった。(Google公式も配列を入れた場合の挙動の説明がなかった)
しかしGeminiに関数をそのまま入力して説明してと依頼するとわかりやすく説明をしてくれた。
関数、スクリプトなどの説明はいったんGeminiなどに投げてから細かな不明点を再度Gemini、Webで調べるとより効率よく作業ができそう。
ベン図メーカー
Googleドキュメントだと重なり部分をピンポイントで塗りつぶしなどができないため、今回のイラスト作成でお世話になりました。