
Microsoft MarkItDown徹底解剖

MarkItDownとは?
MarkItDownは、Microsoftが開発したPythonライブラリで、さまざまなファイル形式をMarkdownに変換することができます。
リリースされてからわずか2週間でGitHubで25k以上のスターを獲得し、急速に人気を集めています!🤯
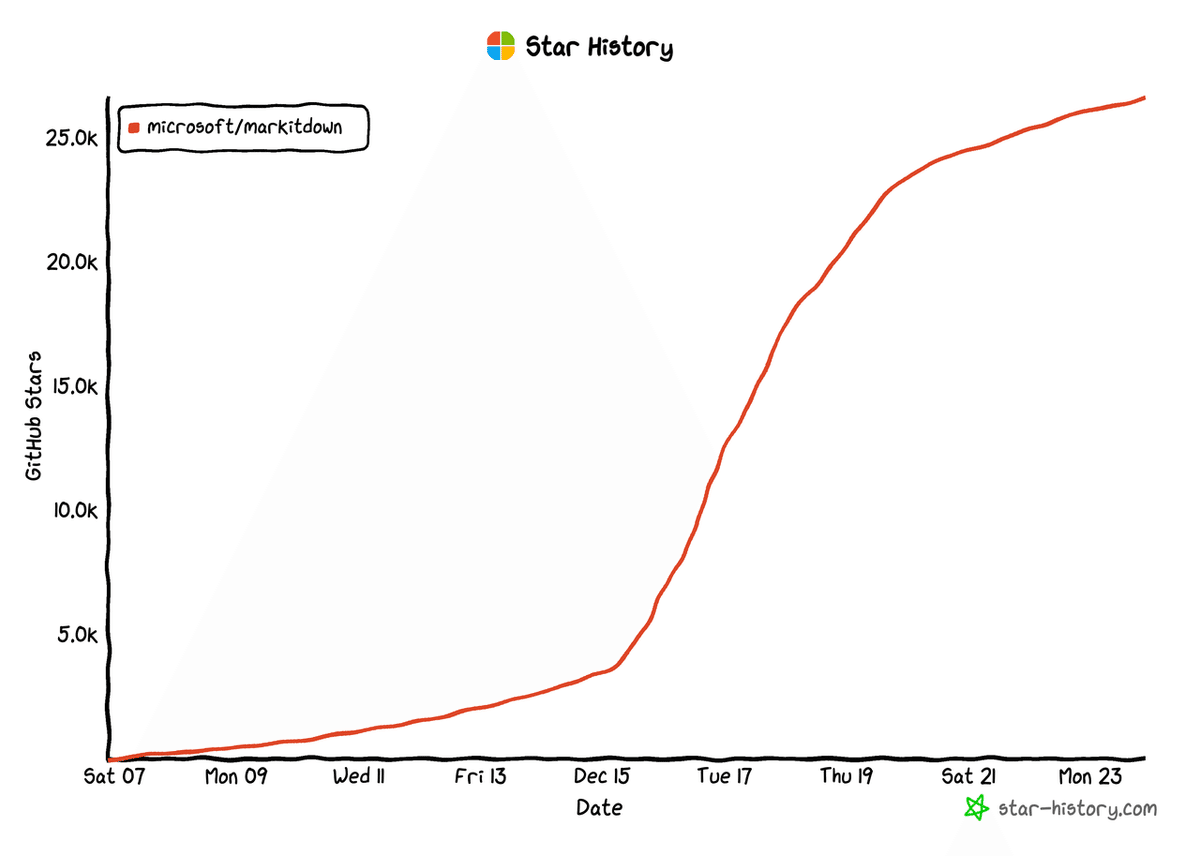
なぜMarkItDownはこんなに人気なのか?
MarkItDownは以下のような幅広いファイル形式に対応しています:
Officeドキュメント: PowerPoint、Word、Excel
リッチメディアファイル: 画像(EXIFおよび画像説明付き)、音声(文字起こし付き)
ウェブ・構造化データ: HTML、CSV、JSON、XML
アーカイブ: ZIPファイル
WordやExcelなどの一般的な形式に対応しているだけでなく、OCRや音声認識を活用してコンテンツを抽出することで、マルチモーダルなファイルにも対応しています。
これにより、あらゆるものをMarkdownに変換できるMarkItDownは、LLM(大規模言語モデル)トレーニングにおいて非常に強力なツールとなります。ドメイン特化型の文書を処理することで、LLM搭載アプリケーションにおいてより正確で関連性の高い応答を生成するためのリッチなコンテキストを提供します。
MarkItDownの使い方
MarkItDownの使用は驚くほど簡単で、わずか4行のコードで済みます:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("test.xlsx")
print(result.text_content)以下はMarkItDownの使用例です。
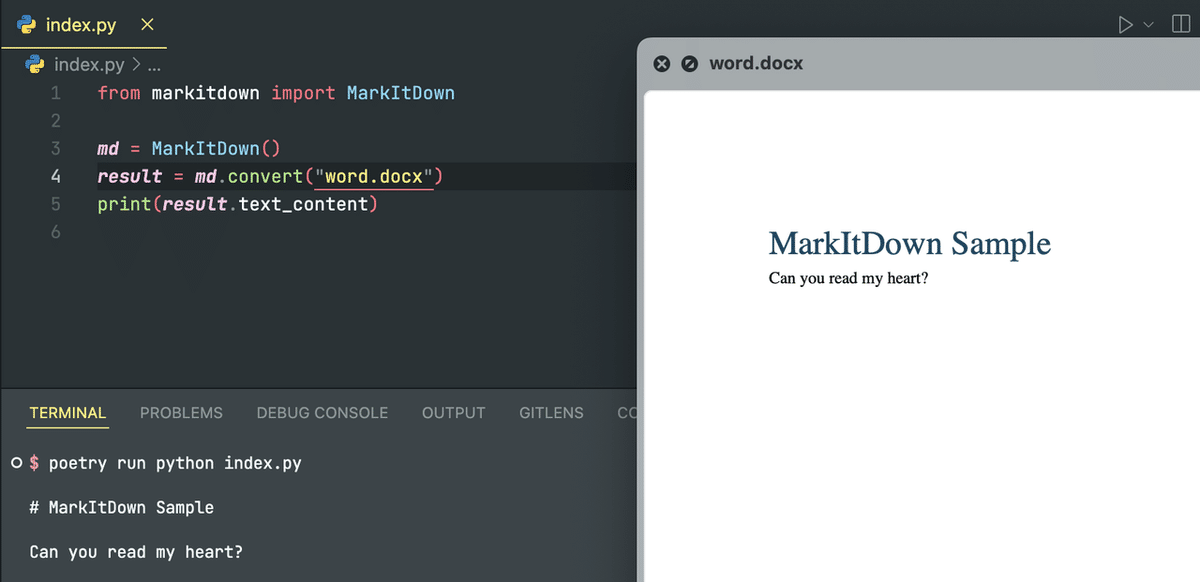
Wordファイルを変換すると、正確なMarkdownが出力されます:
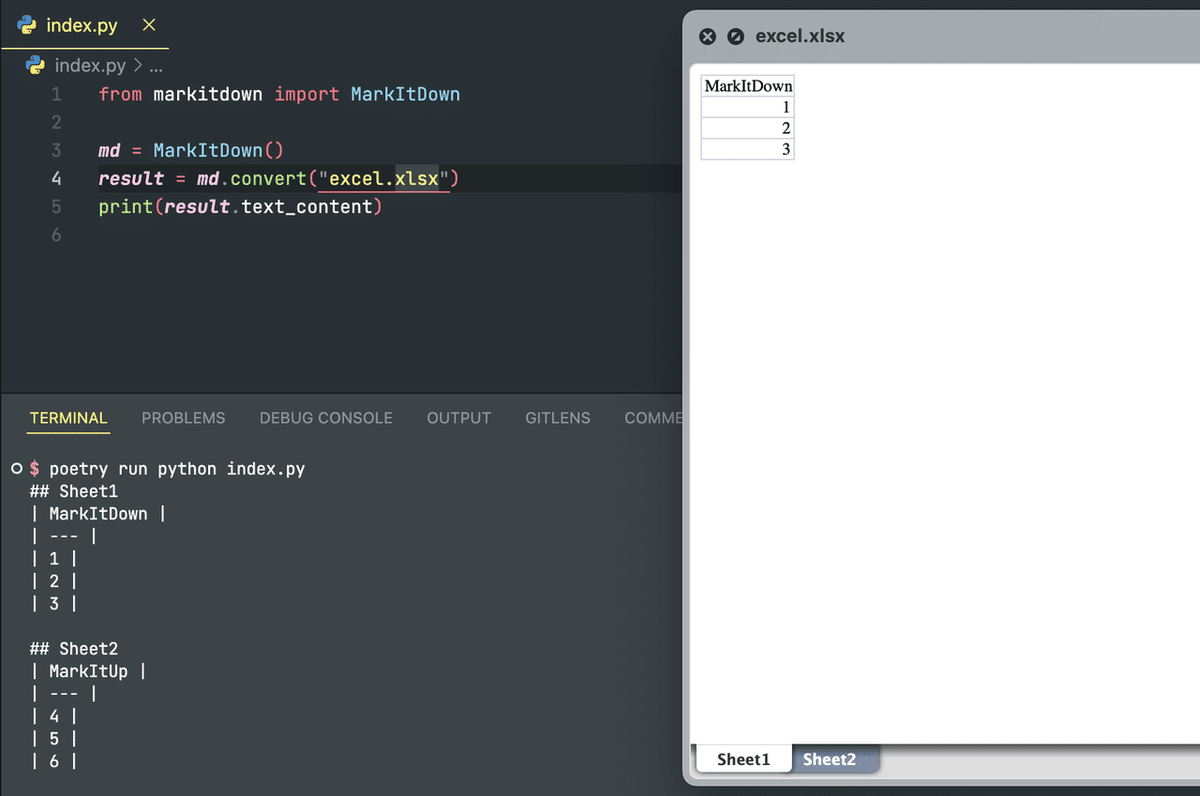
マルチシートのExcelファイルもお手のもの:
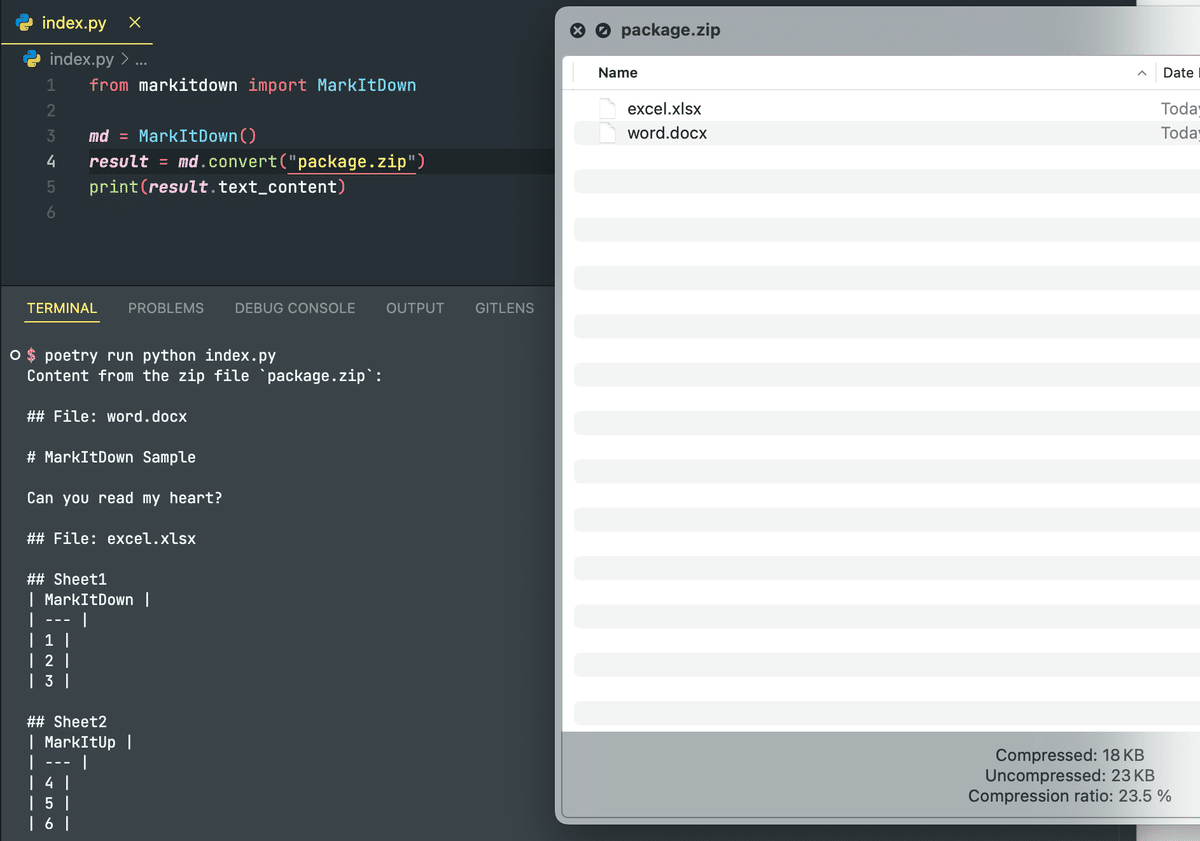
ZIPファイルも処理可能で、アーカイブ内の全てのコンテンツが再帰的に解析されます:
画像からコンテンツを抽出しようとすると、結果は何も得られません:

なぜ結果が得られないのでしょうか?MarkItDownは画像ファイルをサポートしています!
問題は、画像説明を抽出するためにLLMが必要な点にあります。以下のように、MarkItDownに適合したLLMクライアントを統合してください:
from openai import OpenAI
client = OpenAI(api_key="i-am-not-an-api-key")
md = MarkItDown(llm_client=client, llm_model="gpt-4o")これで画像コンテンツが正常に変換されます:
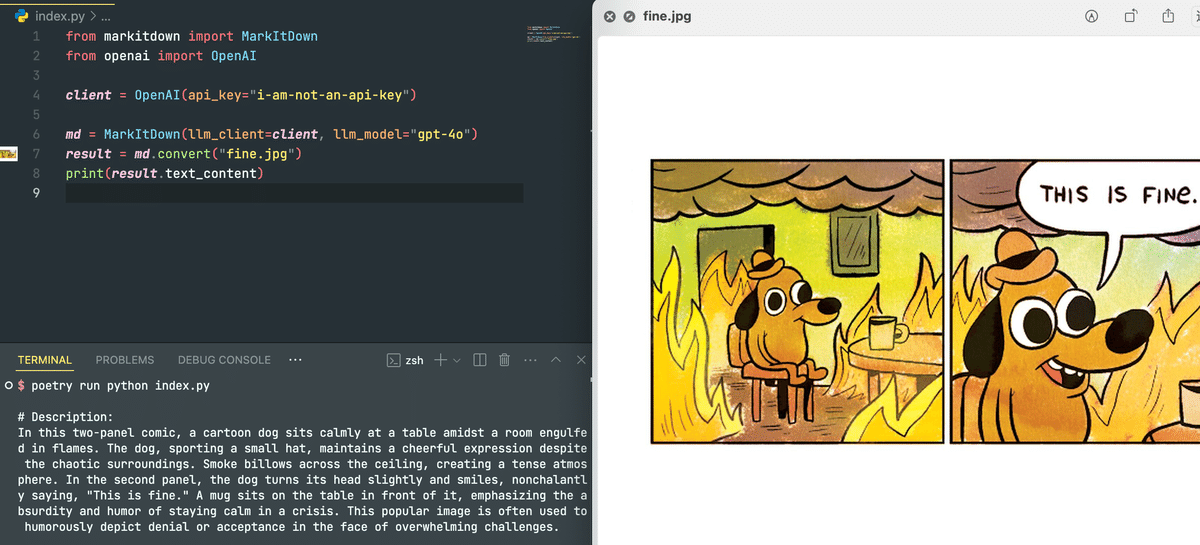
注意:LLMは画像に対してのみ機能します。PDFからコンテンツを抽出するには、事前にOCRで処理されている必要があります。

しかし、PDFから抽出されたテキストは全てのフォーマットを失い、見出しと通常のテキストの区別がつきません。
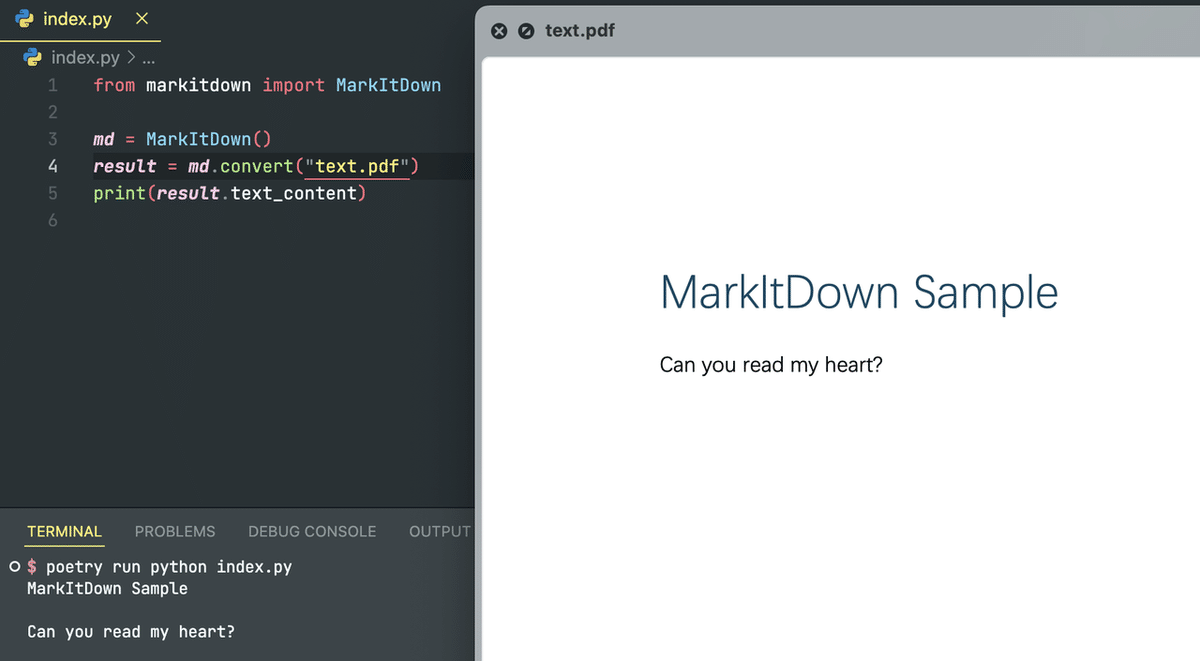
MarkItDownの制限事項
上記の例からも分かるように、MarkItDownにはいくつかの制限があります:
OCR未処理のPDFは処理できません。
PDFから抽出したテキストにはフォーマットがありません。
しかし、MarkItDownはオープンソースツールなので、拡張性が高く、そのシンプルなコードベースにより、開発者は新しい機能を簡単に追加できます。
MarkItDownの仕組み
MarkItDownのアーキテクチャはシンプルで、コア実装はわずか1つのファイルに収められています。
コードベースには、`DocumentConverter`クラスが定義されており、`convert()`メソッドを持っています:
class DocumentConverter:
"""Abstract superclass of all DocumentConverters."""
def convert(
self, local_path: str, **kwargs: Any
) -> Union[None, DocumentConverterResult]:
raise NotImplementedError()さまざまなコンバーターがこの基底クラスを継承し、初期化時に登録されます:
self.register_page_converter(PlainTextConverter())
self.register_page_converter(HtmlConverter())
self.register_page_converter(DocxConverter())
self.register_page_converter(XlsxConverter())
self.register_page_converter(Mp3Converter())
self.register_page_converter(ImageConverter())
# ...このモジュラー設計により、開発者は必要に応じて独自のコンバーターを簡単に作成できます。
各ファイル形式の変換方法
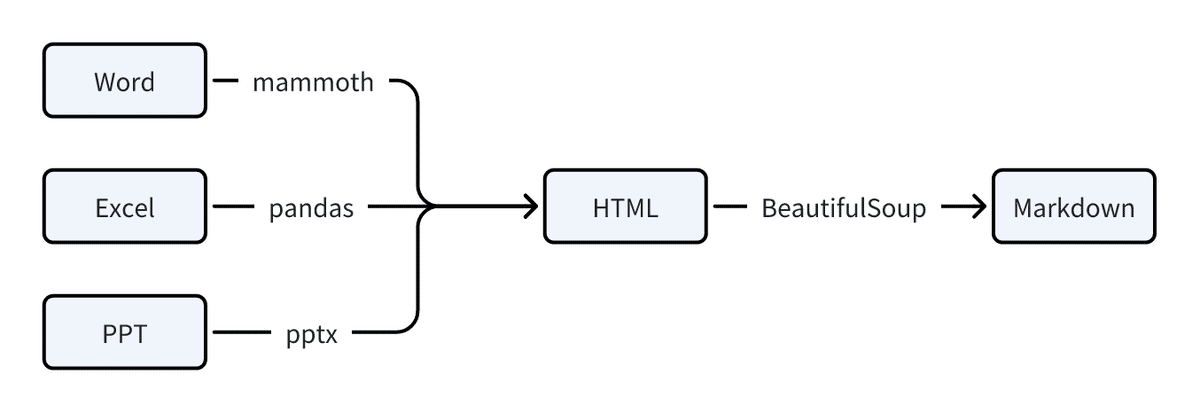
Officeファイル
Officeファイルは最初に`mammoth`、`pandas`、`pptx`などのライブラリを使ってHTMLに変換され、その後`BeautifulSoup`でMarkdownに解析されます。
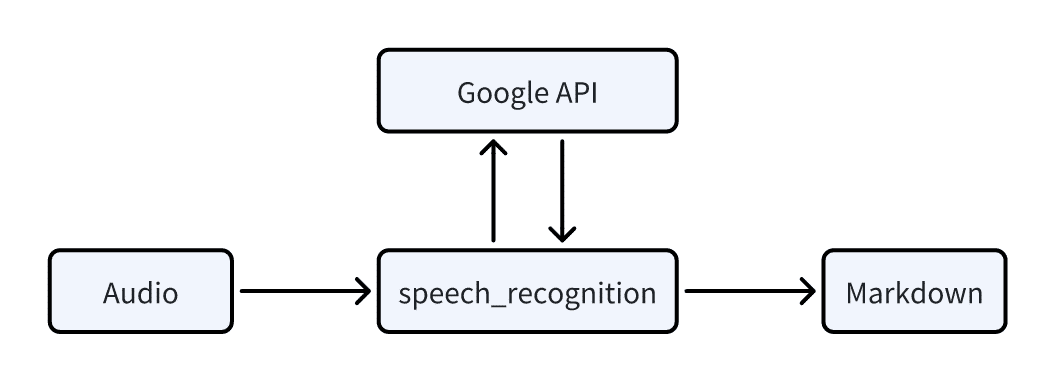
音声ファイル
音声ファイルは`speech_recognition`ライブラリを使って処理され、GoogleのAPIを活用して文字起こしが行われます。
(Microsoftさん、Azureにはまだ忠誠を誓っていますよね?💔)
画像
画像は以下のプロンプトを使用してLLMに処理されます:
`"Write a detailed caption for this image."`

PDFは`pdfminer`ライブラリを使って解析されます。ただし、OCRが内蔵されていないため、PDFの内容が事前に抽出可能であることを確認する必要があります。

MarkItDownをAPIとして利用する方法(無料でホスティング可能)
MarkItDownはローカルで実行できますが、APIとしてホスティングすると、Zapier、n8n、またはファイル変換サービスを提供する独自のウェブサイトなどのワークフローに統合しやすくなります。
以下は`FastAPI`を使用してMarkItDownをAPIとしてホスティングする簡単な例です:
import shutil
from markitdown import MarkItDown
from fastapi import FastAPI, UploadFile
from uuid import uuid4
md = MarkItDown()
app = FastAPI()
@app.post("/convert")
async def convert_markdown(file: UploadFile):
hash = uuid4()
folder_path = f"./tmp/{hash}"
shutil.os.makedirs(folder_path, exist_ok=True)
file_path = f"{folder_path}/{file.filename}"
with open(file_path, "wb") as f:
shutil.copyfileobj(file.file, f)
result = md.convert(file_path)
text = result.text_content
shutil.rmtree(folder_path)
return {"result": text}APIを次のように呼び出すことができます:
const formData = new FormData();
formData.append('file', file);
const response = await fetch('http://localhost:8000/convert', {
method: 'POST',
body: formData,
});APIを無料でホスティングする方法
Python APIのホスティングは難しいことがあります。AWS EC2やDigitalOceanのような従来のサービスは、サーバー全体をレンタルする必要があり、常にコストがかかります。
しかし、今ではLeapcellを利用できます。
LeapcellはPythonコードベースをサーバーレス方式でホスティングできるプラットフォームで、APIコールごとに課金され、無料の利用枠も寛大です。
GitHubリポジトリを接続し、ビルドと開始コマンドを定義するだけで準備完了です:
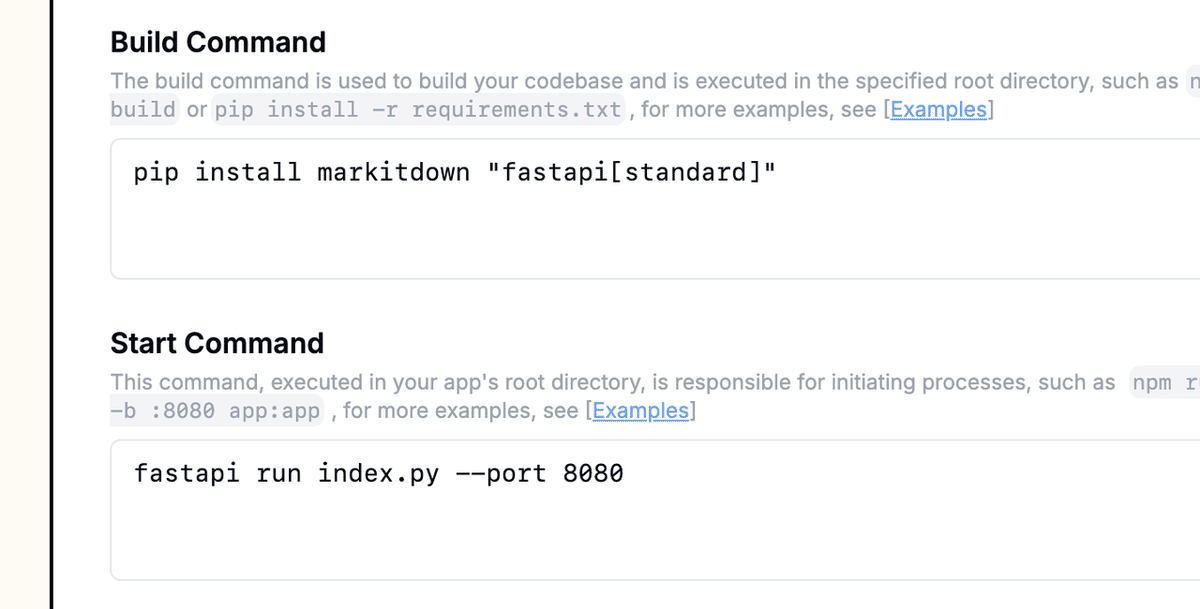
これでMarkItDown APIがクラウドにホストされ、ワークフローに統合できるようになります。そして何より、実際に呼び出されたときだけ課金されます。
今すぐLeapcellで自分のMarkItDown APIを構築しましょう!😎

LeapcellをXでフォローしましょう: https://x.com/LeapcellHQ