
【2023-24】ワードサーチ最新環境で解く正規表現実力診断テスト【EnigmaStudio】

2023年12月17日、EnigmaStudioが一周年を迎えました。
一周年! pic.twitter.com/oD0YVQ6loo
— わんど (@wand_125) December 17, 2023
▲一周年であることがわかるスクショを人の記事から持ってくる人
今日から使おう正規表現
記事の多くをEnigmaStudioの「正規表現置換検索」の説明に割いてくださっているありがたい記事なのですが、
1年の間のツールの進化によって、中級編、上級編を中心に書いている内容が必ずしも最善とはいえなくなりました。
「それはもっと簡単に実現する方法があるよ」
例えば、もう最近は自分は単語検索で正規表現の先読み、後読みをほとんど使わなくなっていたり。
「正規表現置換検索が難しい」や「正規表現記事の中級編・上級編が読めてない」という話を聞く一方でnoteの内容は既に古くなっているギャップをどうやって埋めていくかという課題感があります。
正規表現実力診断テスト
一旦自分がEnigmaStudioをどう使っているかを見せるのが早いのではないか。
フライパン職人氏による記事「正規表現は今日から使おう」では初級編の記事でEnigmaStudioの置換検索など一部を除いて、初級編〜上級編までの取り扱う記事の内容が全25問の実力診断テストの形で最初に提示されています。
これは「謎解き単語検索βのカスタム検索」を封印したり、あくまで「正規表現で書くこと」に主眼を置いたテストになっているのですが、
ここでは、ツール・プログラムなんでも使用可のレギュレーション(ただし、問題に特化したツール面の事前準備(保存した解答ファイルをコピペしたりユーザー辞書を設定するなど)はNG、あくまで普通の単語検索でできる範疇で利用可能なツール)とします。また、全列挙禁止などのいろんな注釈指示も全て無視していいものとします。
ワードサーチRTA
走りました。
▲タイピング音ASMR
以下、チャートについて解説していきます。
元記事を読まなくても良いように構成していますが、
元記事と比較しながらだとより楽しめるかもしれません。
Q1-Q5

主に開発環境のEnigmaStudio汎用検索 (有料版に入る予定のやつ)を使っていきます。
Q1-Q5はそのまま正規表現検索を使うのが早いです。
正規表現検索(汎用検索では単語を絞り込むものをすべて「フィルタ」と呼ぶので「正規表現フィルタ」と呼ばれる)に入力していきます。

Q1.
正規表現パターンにそのまま単語を入れると部分一致で判定されるので
「かうんと」を入れれば良い。
Q2.
先頭文字を表す特殊記号 ^を使って「^いち」とすればよい
Q3.
終端文字を表す特殊記号$を使って「くてん$」とすればよい
Q4.
長さフィルタで文字数を設定しても良いのですが、そのまま正規表現で
「^あ.{7}$」
先頭記号^+あ+ワイルドカード7文字連続+終端記号$
とする
Q5.
「あ」と「ん」の間に文字列を入れなくても良いため、0文字以上の任意長の連続を表す特殊記号*を使って
「^あ.*ん$」
とする
ここまでで34秒、どんどんいきます。
Q6-Q10
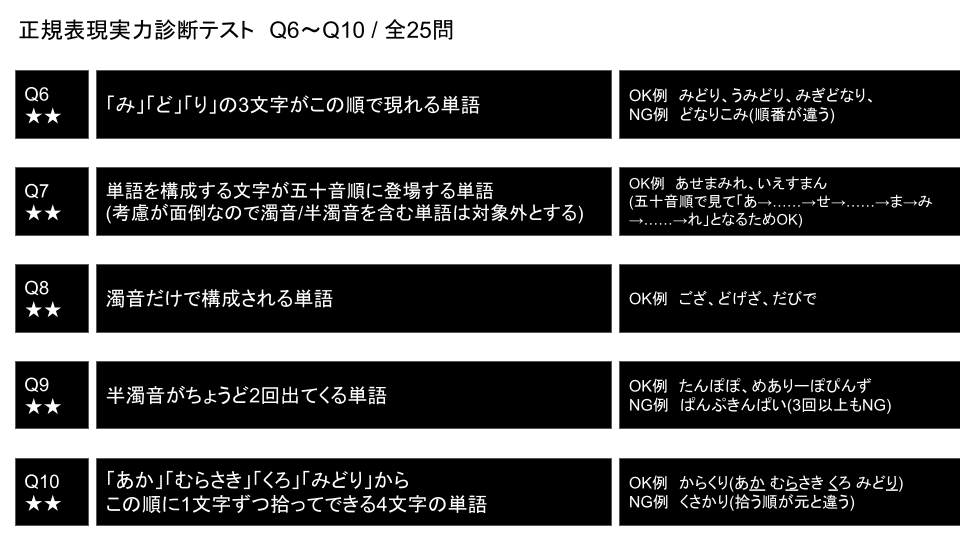
Q6. 「み」「ど」「り」の3文字がこの順で現れる単語
候補文字フィルタに「この順で含まれる」という、ピッタリの機能があるので使用します。実際謎解きでの使用頻度も割と高く、正規表現検索時代にもよく使っていました。
この機能は汎用検索だけでなく、一般検索の候補文字検索にも実装されています。

Q7. 単語を構成する文字が五十音順に登場する単語
EnigmaStudioの汎用検索・一般検索では辞書指定の代わりに自由入力として改行区切りの任意の単語を入力することができます。
さらに汎用検索では自由入力欄に「フル機能のワードジェネレータ」が組み込まれています。
例えば「ワードジェネレータ」から「謎解きの題材リスト」を選択して

候補文字フィルタで「わんど」「を全て含む」を選択すると

「『わんど』は『ドレミの歌』から拾える」ということがわかります。

ワードジェネレータがこの位置にあるのは単に使いたい単語を呼び出すだけの用途にも便利で、Q7では、
「あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん」という文字列をコピペするためにワードジェネレータに切り替えて使っています。
Q8.濁音だけで構成される単語
さらに、汎用検索にはよく使う文字列や変換に必要な文字列ををリスト定義できる機能が備わっており、最初からいくつかのリストが定義されています。

このリスト定義の内容は色々なところで利用でき、
正規表現フィルタの検索側では@<リスト名>、置換側では<リスト名>で展開されます。
「リスト名」がコロン:で区切られている部分はどちらの名前を使っても良いことを表しています。
つまり
「^[@<d>]+$」
は
「^[がぎぐげござじずぜぞだぢづでど;ばびぶべぼ]+$」と同じ意味を持ちます。
Q9. 半濁音がちょうど2回出てくる単語
「ぱぴぷぺぽ」は「@<h>」で取得できます。1文字しか減ってない(けどローマ字であれば6文字ぐらい、今回は@<d>から1文字だけ書き換えるだけで実現できました。
これは、元記事では「半濁音以外」と「半濁音」を使って実現していますが、

汎用検索では複数のフィルタを組み合わせて検索できるので、
正規表現フィルタの「否定マッチ」機能を使って「半濁音2つにマッチする(拡張)正規表現」と「半濁音3つにマッチしない(拡張)正規表現」を
組み合わせることでも実現できます。
Q10.「あか」「むらさき」「くろ」「みどり」から
この順に1文字ずつ拾ってできる4文字の単語
動画では普通に正規表現を入力していますが、
ワードジェネレータでに改行区切りで入力したあと

①→②の順に押してもいいかもしれないです。

「正規表現変換ボタン」で説明を別に書いたほうが良いかもしれない。
ここまでで1:51
Q11-Q15
元記事ではQ15までが初級編のようです。手厚いし十分すぎる

Q11.「はる」「なつ」「あき」「ふゆ」をどれか含む単語
手打ちしましたが同じくワードジェネレータで2タップで生成できます。タイム短縮の余地がある。

Q12. 十二支の名前を2個以上羅列して作れる単語
さすがにワードジェネレータがはやい。2回コピペして先頭終端記号をつけるところまでやってもよかったかもしれない、
あ、末尾に+が抜けていて2回ちょうどになっていてチャレンジに失敗してる!!!記事の本質には影響しませんが、RTA記録としては再走が要る

Q13. 同じ文字が3回以上出てくる単語
さすがに正規表現を直打ちが早そう、括弧で括ったところを\1,\2,…で呼び出す、キャプチャチュートリアルですね
「(.).*\1.*\1」
Q14. ちょうど5文字の回文
同じくキャプチャを利用しました。
汎用検索を使った別ルートとしては文字列反転してトレース比較で変換前と一致するかを見る、という正規表現を経由しない方法があります。

「トレース」という耳慣れない独自用語がでてきましたが、
「単語を変換するたびに追加される履歴」のことをトレースと呼んでいます。
この例では、トレース1が入力した単語でトレース2が反転した単語ということになります。
Q15.
「元記事では母音がちょうど2個のグループ」がn個ある形で正規表現を書いていますが、
母音以外「[^あいうえお]」を空文字列「」に置き換え、
文字列が偶数文字かを正規表現「^(..)+$」でマッチ、としています。

ここまでで3分13秒、この辺りまではワードサーチの基本ということで、全部正規表現で書いたとしてもそんなに変わらないかもしれません。
Q16-Q20
ここから中級編
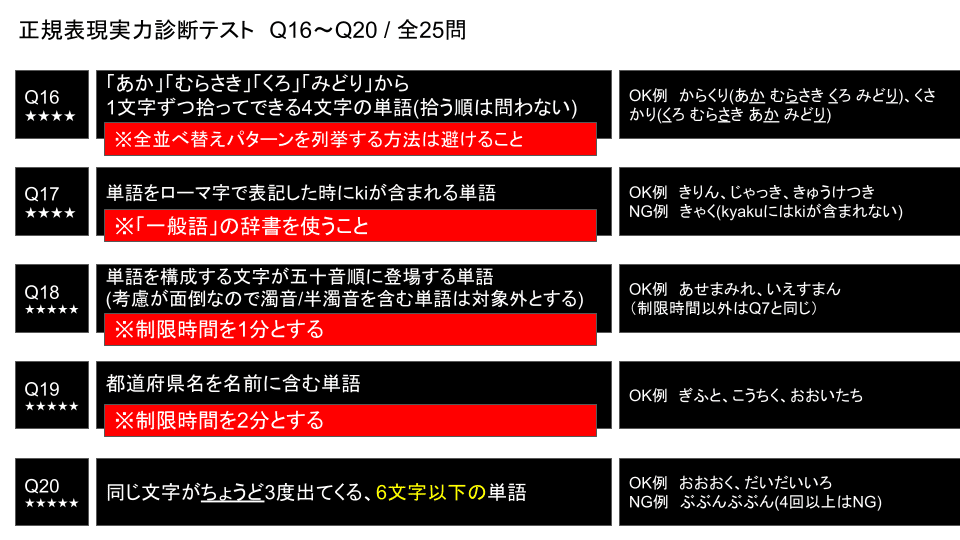
Q16. 「あか」「むらさき」「くろ」「みどり」から
1文字ずつ拾ってできる4文字の単語(拾う順は問わない)
というわけで、まずは上記の条件を先読みで書く方法を考える。
(パターン1) (?=.*[あいうえお]) または ^(?=.*[あいうえお])
(パターン2) (?=.*[かきくけこ]) または ^(?=.*[かきくけこ])
(パターン3) (?=.*[さしすせそ]) または ^(?=.*[さしすせそ])
(パターン4) ^(?=.{3}$)
となる。パターン1~3は括弧内に $ が書かないことに注意。例えばパターン1で $ を書くと、「末尾に [あいうえお] が登場する」場合に限定してしまう。どの位置でも良いのだから、$ は付けてはならない。
これらを組み合わせることで、
^(?=.*[あいうえお])(?=.*[かきくけこ])(?=.*[さしすせそ])(?=.{3}$)
とパターン1~4のすべての条件を重ねがけして検索することができる。
元記事では、先読みを利用して正規表現の条件の重ねがけを行う手法について紹介されていますが、
汎用検索であれば、フィルタを複数並べることで「条件の重ねがけ」が実現できます。
そのため、自分はこの用途での正規表現先読み、後読みを使うことがなくなりました。
汎用検索が正規表現中級編を過去にしてしまった理由1つ目

ただ、わかりやすさより速さを取るなら、一個ずつフォームに打つよりワードジェネレータで正規表現変換ボタンを押す方が依然早いかもしれない。

元記事にもありますが、重複した文字がある時はこれらの手法は使えず、
EnigmaStudioProの「ワードマッチング」が利用できます。
Q17. 単語をローマ字で表記した時にkiが含まれる単語
これは「「き」のあとに「ゃぃゅぇょ」が現れない」と読み替えて
「き(?![ゃぃゅぇょ])」と書く否定先読みのチュートリアル問題ですが、
汎用検索では「ローマ字変換」→「kiを含むか正規表現検索」で済みます。

「ヘボン風タイピング、訓令風タイピング」は韻を取り出す時に都合の良いローマ字で、
で説明しています。
Q18. 単語を構成する文字が五十音順に登場する単語
ここからは辞書登録とテキストエディタの文字列置換を覚えて楽をしようのコーナー、
制限時間は1分間ですが、10秒ぐらいでおわります。
Q19. 都道府県名を名前に含む単語
これもワードジェネレータに入っているので一瞬です。
Q18.Q19の2つ合わせて、元記事の5000文字相当分がカットされました。
(あくまで例が一瞬でこなせるようになっただけであって、正規表現置換自体は汎用検索でも頻出の有用な概念なので、やっている内容自体は価値がりますが。)
Q20. 同じ文字がちょうど3度出てくる、6文字以下の単語
元記事では肯定先読み、否定先読み、後読みの使い分けの話が繰り広げられていますが、

これまでやってきたように、シンプルに正規表現フィルタを重ねることで元記事初級編の範囲の正規表現で実現できます。
ここまでで5分8秒
Q21-Q25
いよいよ上級編、「正規表現の文法はわかるけど…….」という人でも面食らうような問題群です。

Q21.10文字以下の2-回文(2つの回文を並べてできる単語)
元記事では10文字以下の回文のどれかにマッチする正規表現を2つ繋げてマッチするかを判定しています。
「^(?=.{0,10}$)(.?)(.?)(.?)(.?)(.?).?\5\4\3\2\1(.?)(.?)(.?)(.?)(.?).?\10\9\8\7\6$」
空文字キャプチャを活用するかなり正規表現を活かしたルートで、正直こっちのほうが優れているな、これで良かったかとなっています。
自分の方では1分ほどかけてしまっていて、しかも検索時間も遅くなってしまっていますが、いろんなテクニックを使っているので説明します。
まずは「並列変換」という1つの単語に対して正規表現置換変換をそれぞれ掛けることができる機能を使います。

まずは1文字の単語と9文字の単語をキャプチャしてそれぞれをreverse関数で反転して、繋げています。

それをトレース比較機能を使って変換前と一致しているかどうかを見ています。
そして、ここで、タブを「フォームツール」から「JSON入出力」に切り替えます。

入力したフォームの内容はすべてJSONデータとして管理されています。
JSON入出力機能を使うことで、
作成したフォームを外部ファイルにコピペすることや、
逆に外部のJSONファイルを貼り付けて汎用検索のレシピとして利用することができます。
ここでは、効率的に似た内容のフォームを埋めるためにJSONファイルを直接編集します。
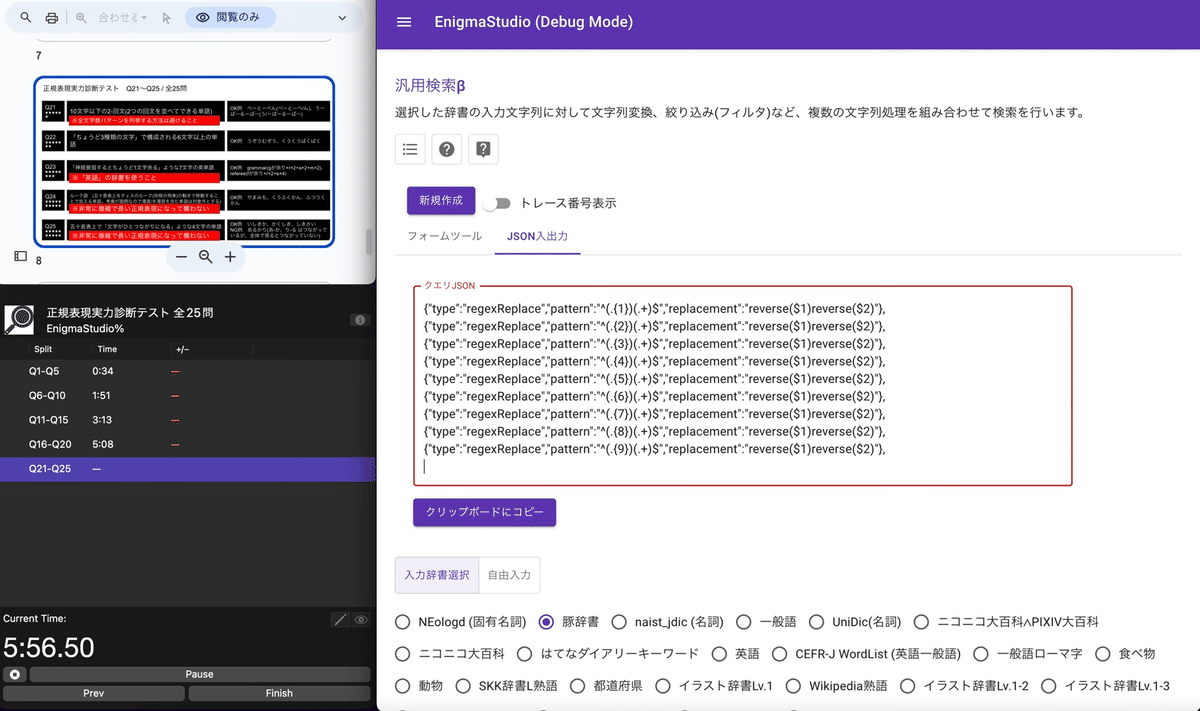
1文字キャプチャしている部分のフォームのコードをコピーして
1,2,3,…,9に書き換えて
フォームツールに戻すと9個の入力データができました。
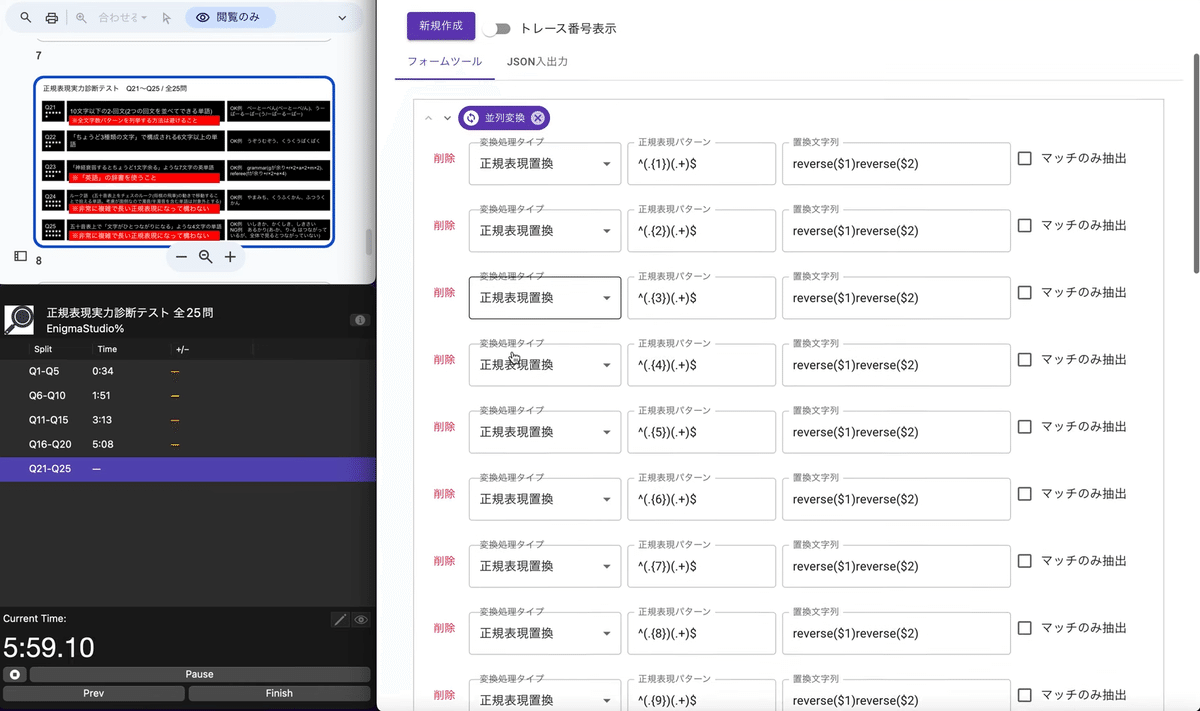
入れ忘れていた「マッチのみ抽出」にチェックを入れて検索することで、
「1-回文を含まない」「2-回文」を取り出すことができました。
1文字の単語を除外したりも簡単にできそうです。
ただ、明らかに特殊なテクニック(バッドノウハウ)なので、文字数を指定してのキャプチャも含め、機能追加で今後必要なくなるテクニックになる可能性が高いです。
あくまでEnigmaStudio一周年現在の手法ということになります。
Q22. 「ちょうど3種類の文字」で構成される6文字以上の単語
元記事では「キャプチャを意識した正規表現後読みが必要な例」として説明されていました。
汎用検索では先に単語を「文字列ソート」しておき、「同じ文字の連続部分が3つ以内」で、「2つ以内ではない」ことで判定できます。

このように、汎用検索でのソート機能は、ソート自体を謎解きに使うというよりは、同じ文字列をまとめたり、アナグラムして同じになる文字列を同一視したりする時に利用できます。
後者は「同じグループのものを代表値に正規化する」イメージですね
Q23. 「神経衰弱するとちょうど1文字余る」ような7文字の英単語
同じく、文字列をソートして、連続する同じ2文字を空文字列に変換し、
文字列長が1文字であるかで判定できます。
Q24. ルーク語(五十音表上をチェスのルーク(将棋の飛車)の動きで移動することで拾える単語。
ここから非常に長い正規表現をスプレッドシートを駆使してつくる
元記事で「全列挙型クソ長正規表現」と呼ばれているもののの話になります。本当にRTAできるんだろうか。
ルーク語の要素を大まかにわけると
隣接する2文字すべてについて検索
母音もしくは子音が一致するものを検索
となります。(細かいことをいうと、「あ」と「ん」も母音一致とみなしまたりしますが)
単語の特定の部分に対して関数を適用したい時や、単語の内部の複数の単語が条件を満たすかをを調べたい時は「正規表現マッチ比較フィルタ」を利用できます。
正規表現マッチ比較フィルタは、パターンから取り出した複数の比較文字列について、比較を行い、条件に一致する単語のみを残します。

例えば上の例では1文字目と4文字目が同じ5文字の単語にマッチします。
(この例は正規表現で「^(.)..\1.$」と書けます)
正規表現マッチ比較フィルタの正規表現パターンに部分文字列のパターンを指定した場合、
マッチしたすべての場所に対して比較が行われます。
が、マッチ位置が重複することはありません。
(Javascriptの正規表現のmatchAllの挙動)
例えば「..」という正規表現は
1-2文字目、3-4文字目、5-6文字目、…にマッチし、
2-3文字目、4-5文字目、6-7文字目…にはマッチしません。
今回は隣接する文字のペアすべてにマッチさせたい、
すなわち
「あいさつ」 から「あい」、「いさ」、「さつ」がマッチするように
「あいさつ」→「あいいささつ」となる変換を行います。
先頭文字と末尾の文字以外の文字を2文字ずつ繰り返すように正規表現置換を行います。

ここで初めて正規表現の先読み、後読みを使いました。
ワードサーチでAND検索を使うために使われがちですが、本来、直前や直後の文字の条件を指定するために使われがちな構文です。
これで、要素の一つ目「隣接する2文字すべてについて検索」ができそうです。
次は母音もしくは子音が一致するものの検索について。
これは汎用検索のpair関数を利用します。
pair関数は、文字列の1文字ごとに特定の文字に置き換えるもので、
置き換え文字列は直接入力もしくは定義リストが利用できます。
下の例では例えば濁音を静音に変換し、変換後の単語が辞書に含まれているかを検索しています。

give(ギブ)→寄付
のような例が見つかります。
これを使って2つの文字を
あいうえお→あ
かきくけこ→か
さしすせそ→さ
…
と変換した上で一致するかを判定すれば子音の一致が判定できます。
同様に
あかさたな…→あ
いきしちに…→い
と変換した上で一致するかを判定すれば母音の一致も判定できます。
今回は母音の
正規表現パターン「(.)(.)」(隣接する2文字が$1,$2に入る)
として、
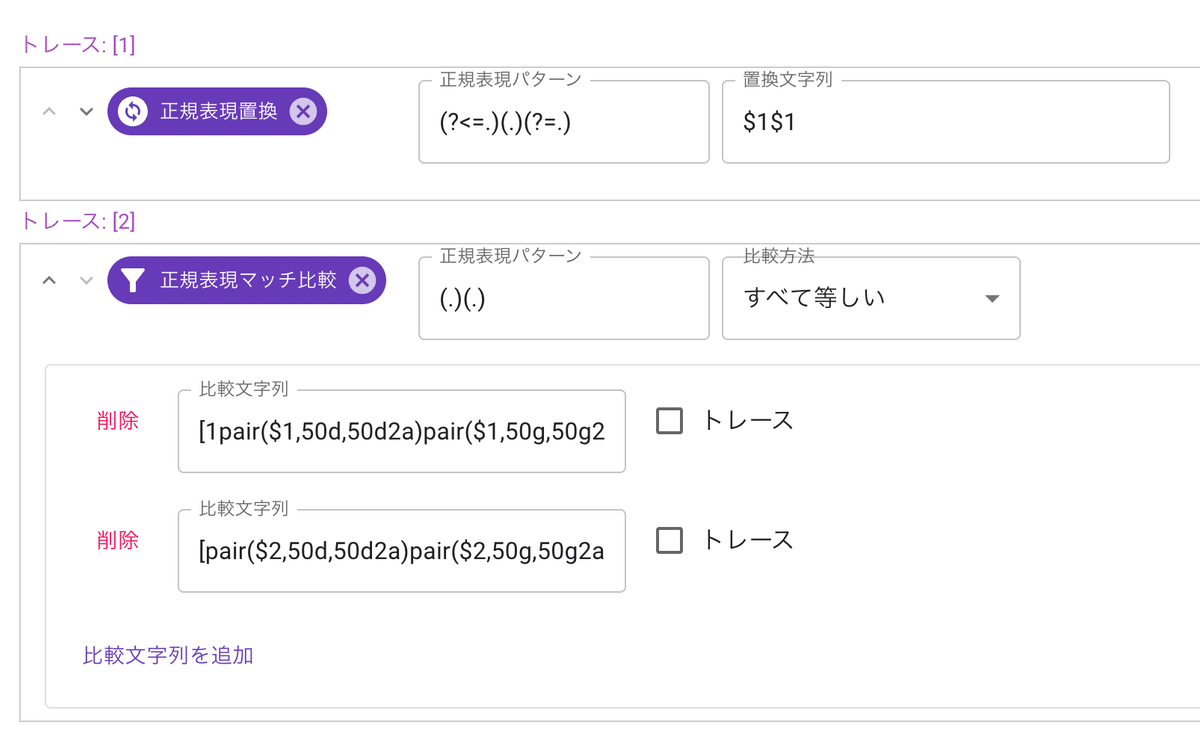
「pair($1,50d,50d2a)」「pair($1,50g,50g2a)]」とすることで、五十音の段の正規化ができます。
母音と子音のどちらかが一致すればいいので
複数指定した時に、「どれかが一致すれば良い」となるように
「[pair($1,50d,50d2a)|pair($1,50g,50g2a)]」のように
汎用検索のブラケット展開機能「[{文字列1}|{文字列2}]」を利用します。
また、「母音のた→あ」「子音のう→あ」が同一視されないように母音同士、子音同士が比較されるように
として、
「[1pair($1,50d,50d2a)|2pair($1,50g,50g2a)]」
あかさたな…→1あ
いきしちに…→1い
あいうえお→2あ
かきくけこ→2か
…
となるようにします。
1文字目$1と2文字目$2に同じ正規化変換をして比較することで同じ行にあることを調べられました。
Q25. 五十音表上で「文字がひとつながりになる」ような4文字の単語
しきさい
↓
さ
しきい
のように五十音表でテトリスのブロックになるもの(順不同)を探します。
大変そうすぎる。
元記事では、全列挙型正規表現でやる場合は「隣接する文字のペア」を全て列挙して、
さらにそれを3回並べて3回以上マッチするかを調べていました。
まずは、この制約が文字の順序に寄らないことを利用して
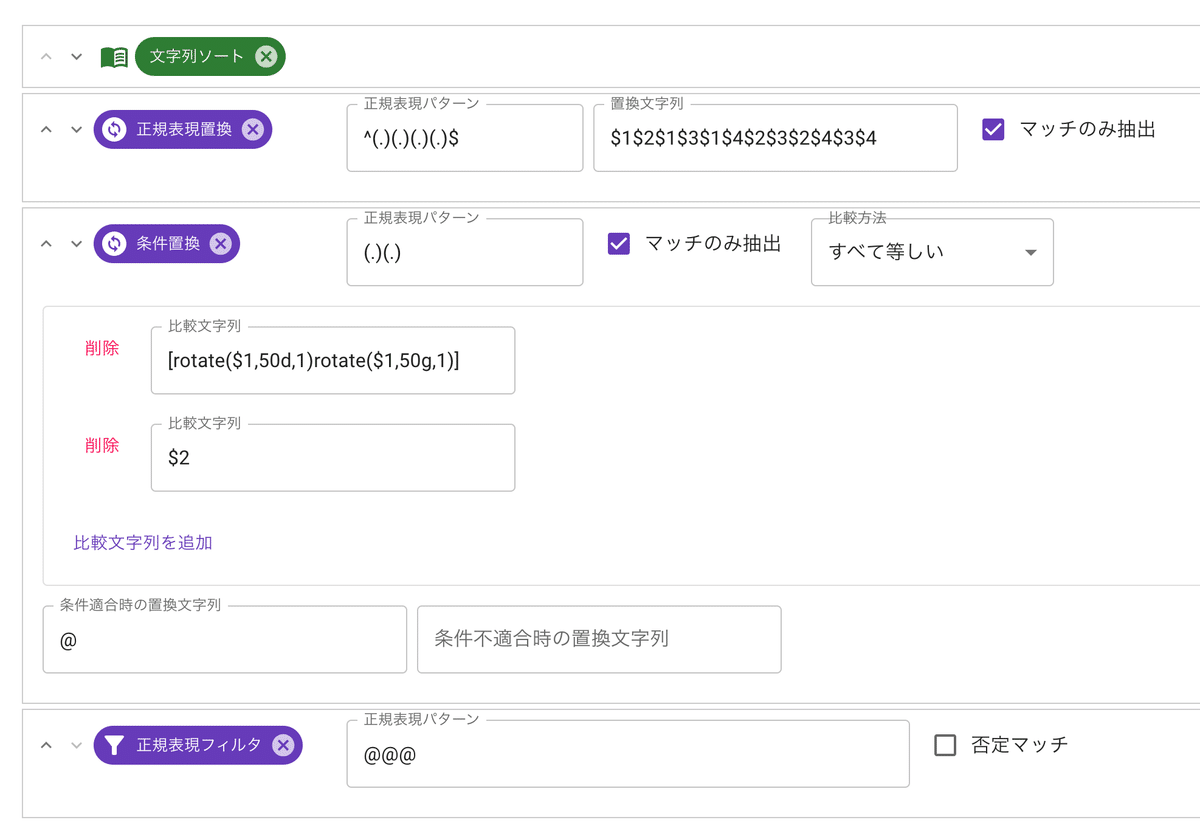
先に文字列ソートを掛けます。
4文字の隣接するペアをすべて列挙します
(1,2)文字目,(1,3)文字目,…,(3,4)文字目
6個しかないので手で列挙します。
今度は「条件検索」を使います。条件置換は正規表現マッチ比較フィルタの置換バージョンで、条件を満たす時と満たさない時の置換内容を変えることができます。
ここでは条件を満たす時に@、満たさない時に空文字列に変換して
@が3つ以上あるものを取り出します。
比較文字列の方では、今度はpair関数ではなくrotate関数指定したリストにマッチする文字列をリスト上で{数値}個進めることを意味します。
画像は隣接文字の1文字目を五十音の段か行で1つ進めることを意味しています。
先にソートしておいたので必ず進む方向となり、判定する方向が2方向で済みます。
ちなみにソートしない場合はrotate($1,50d,1&-1)といった書き方もできます。
(動画では出力を待ちましたが)検索ボタンを押したタイミングでタイマーストップです。10分31秒12
感想
最後は駆け足になりましたが、これで完走することができました。
誤りやもっと効率的にできそうなところも見つかったので再走したいところですね、またツールの方もまだまだ進化できそうです。
また、改めて記事の利用を快諾してくださった、そして汎用検索の仕様策定に大きく関わってくださっているフライパン職人氏(@1220oz_an)に感謝です。
▲本編には実力診断テストと合わせて50問の課題があります。
また、この記事は汎用検索の機能やできることを網羅できているわけではありませんし、汎用検索ができる大きなことでもRTAに関係なければ思い切って省いています。さらに、実をいうと自分やフライパン職人氏もまだこのツールで何ができるのか研究中なところがあります。
こういった点も今後の記事などで補足できたらと思いますが、
この記事がワードサーチの世界を覗くきっかけとなればなによりです。
汎用検索最新ver公開
告知です。
RTAは開発中の最新verの汎用検索を利用しましたが、
記事の更新に合わせて開発中の最新verをリリースしました。
(試走は動作テストの一環でもありました)
さらに正規表現用の拡張入力や全角記号を自動で置き換えるオプションなども入りました。
スマホから正規表現を楽に入力したいという要望 pic.twitter.com/Qm8XKVXGg8
— わんど (@wand_125) December 19, 2023

正規表現を活用したい人、使わずに楽をしたい人どちらの方向にも進化させています。
拡張入力は一般検索/汎用検索、スマホ/PCの両方でも利用可能にしているので、またチャートに変化がありそうです。
---
汎用検索はEnigmaStudioのPro以上のプラン(月500円)で利用可能となっています。
謎解き、謎制作、ワードパズル、言葉遊びはもちろん、正規表現問題集記事などと合わせることで、ワードサーチのおもちゃとしても楽しめるツールとなっています。
よかったらご支援いただけると幸いです。